 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction-based Image Editing with Planning, Reasoning, and Generation
Feb 26, 2026Editing images via instruction provides a natural way to generate interactive content, but it is a big challenge due to the higher requirement of scene understanding and generation. Prior work utilizes a chain of large language models, object segmentation models, and editing models for this task. However, the understanding models provide only a single modality ability, restricting the editing quality. We aim to bridge understanding and generation via a new multi-modality model that provides the intelligent abilities to instruction-based image editing models for more complex cases. To achieve this goal, we individually separate the instruction editing task with the multi-modality chain of thought prompts, i.e., Chain-of-Thought (CoT) planning, editing region reasoning, and editing. For Chain-of-Thought planning, the large language model could reason the appropriate sub-prompts considering the instruction provided and the ability of the editing network. For editing region reasoning, we train an instruction-based editing region generation network with a multi-modal large language model. Finally, a hint-guided instruction-based editing network is proposed for editing image generations based on the sizeable text-to-image diffusion model to accept the hints for generation. Extensive experiments demonstrate that our method has competitive editing abilities on complex real-world images.
* 10 pages, 7 figures
MultiMotion: Multi Subject Video Motion Transfer via Video Diffusion Transformer
Dec 12, 2025Multi-object video motion transfer poses significant challenges for Diffusion Transformer (DiT) architectures due to inherent motion entanglement and lack of object-level control. We present MultiMotion, a novel unified framework that overcomes these limitations. Our core innovation is Maskaware Attention Motion Flow (AMF), which utilizes SAM2 masks to explicitly disentangle and control motion features for multiple objects within the DiT pipeline. Furthermore, we introduce RectPC, a high-order predictor-corrector solver for efficient and accurate sampling, particularly beneficial for multi-entity generation. To facilitate rigorous evaluation, we construct the first benchmark dataset specifically for DiT-based multi-object motion transfer. MultiMotion demonstrably achieves precise, semantically aligned, and temporally coherent motion transfer for multiple distinct objects, maintaining DiT's high quality and scalability. The code is in the supp.
FlowSteer: Conditioning Flow Field for Consistent Image Restoration
Dec 09, 2025Flow-based text-to-image (T2I) models excel at prompt-driven image generation, but falter on Image Restoration (IR), often "drifting away" from being faithful to the measurement. Prior work mitigate this drift with data-specific flows or task-specific adapters that are computationally heavy and not scalable across tasks. This raises the question "Can't we efficiently manipulate the existing generative capabilities of a flow model?" To this end, we introduce FlowSteer (FS), an operator-aware conditioning scheme that injects measurement priors along the sampling path,coupling a frozed flow's implicit guidance with explicit measurement constraints. Across super-resolution, deblurring, denoising, and colorization, FS improves measurement consistency and identity preservation in a strictly zero-shot setting-no retrained models, no adapters. We show how the nature of flow models and their sensitivities to noise inform the design of such a scheduler. FlowSteer, although simple, achieves a higher fidelity of reconstructed images, while leveraging the rich generative priors of flow models.
Follow-Your-Motion: Video Motion Transfer via Efficient Spatial-Temporal Decoupled Finetuning
Jun 05, 2025Recently, breakthroughs in the video diffusion transformer have shown remarkable capabilities in diverse motion generations. As for the motion-transfer task, current methods mainly use two-stage Low-Rank Adaptations (LoRAs) finetuning to obtain better performance. However, existing adaptation-based motion transfer still suffers from motion inconsistency and tuning inefficiency when applied to large video diffusion transformers. Naive two-stage LoRA tuning struggles to maintain motion consistency between generated and input videos due to the inherent spatial-temporal coupling in the 3D attention operator. Additionally, they require time-consuming fine-tuning processes in both stages. To tackle these issues, we propose Follow-Your-Motion, an efficient two-stage video motion transfer framework that finetunes a powerful video diffusion transformer to synthesize complex motion.Specifically, we propose a spatial-temporal decoupled LoRA to decouple the attention architecture for spatial appearance and temporal motion processing. During the second training stage, we design the sparse motion sampling and adaptive RoPE to accelerate the tuning speed. To address the lack of a benchmark for this field, we introduce MotionBench, a comprehensive benchmark comprising diverse motion, including creative camera motion, single object motion, multiple object motion, and complex human motion. We show extensive evaluations on MotionBench to verify the superiority of Follow-Your-Motion.
TIMRL: A Novel Meta-Reinforcement Learning Framework for Non-Stationary and Multi-Task Environments
Jan 13, 2025In recent years, meta-reinforcement learning (meta-RL) algorithm has been proposed to improve sample efficiency in the field of decision-making and control, enabling agents to learn new knowledge from a small number of samples. However, most research uses the Gaussian distribution to extract task representation, which is poorly adapted to tasks that change in non-stationary environment. To address this problem, we propose a novel meta-reinforcement learning method by leveraging Gaussian mixture model and the transformer network to construct task inference model. The Gaussian mixture model is utilized to extend the task representation and conduct explicit encoding of tasks. Specifically, the classification of tasks is encoded through transformer network to determine the Gaussian component corresponding to the task. By leveraging task labels, the transformer network is trained using supervised learning. We validate our method on MuJoCo benchmarks with non-stationary and multi-task environments. Experimental results demonstrate that the proposed method dramatically improves sample efficiency and accurately recognizes the classification of the tasks, while performing excellently in the environment.
UniPaint: Unified Space-time Video Inpainting via Mixture-of-Experts
Dec 09, 2024



In this paper, we present UniPaint, a unified generative space-time video inpainting framework that enables spatial-temporal inpainting and interpolation. Different from existing methods that treat video inpainting and video interpolation as two distinct tasks, we leverage a unified inpainting framework to tackle them and observe that these two tasks can mutually enhance synthesis performance. Specifically, we first introduce a plug-and-play space-time video inpainting adapter, which can be employed in various personalized models. The key insight is to propose a Mixture of Experts (MoE) attention to cover various tasks. Then, we design a spatial-temporal masking strategy during the training stage to mutually enhance each other and improve performance. UniPaint produces high-quality and aesthetically pleasing results, achieving the best quantitative results across various tasks and scale setups. The code and checkpoints will be available soon.
DiT4Edit: Diffusion Transformer for Image Editing
Nov 05, 2024

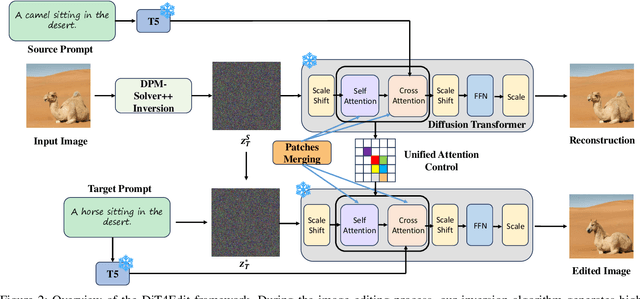

Despite recent advances in UNet-based image editing, methods for shape-aware object editing in high-resolution images are still lacking. Compared to UNet, Diffusion Transformers (DiT) demonstrate superior capabilities to effectively capture the long-range dependencies among patches, leading to higher-quality image generation. In this paper, we propose DiT4Edit, the first Diffusion Transformer-based image editing framework. Specifically, DiT4Edit uses the DPM-Solver inversion algorithm to obtain the inverted latents, reducing the number of steps compared to the DDIM inversion algorithm commonly used in UNet-based frameworks. Additionally, we design unified attention control and patches merging, tailored for transformer computation streams. This integration allows our framework to generate higher-quality edited images faster. Our design leverages the advantages of DiT, enabling it to surpass UNet structures in image editing, especially in high-resolution and arbitrary-size images. Extensive experiments demonstrate the strong performance of DiT4Edit across various editing scenarios, highlighting the potential of Diffusion Transformers in supporting image editing.
Adaptive Domain Learning for Cross-domain Image Denoising
Nov 03, 2024



Different camera sensors have different noise patterns, and thus an image denoising model trained on one sensor often does not generalize well to a different sensor. One plausible solution is to collect a large dataset for each sensor for training or fine-tuning, which is inevitably time-consuming. To address this cross-domain challenge, we present a novel adaptive domain learning (ADL) scheme for cross-domain RAW image denoising by utilizing existing data from different sensors (source domain) plus a small amount of data from the new sensor (target domain). The ADL training scheme automatically removes the data in the source domain that are harmful to fine-tuning a model for the target domain (some data are harmful as adding them during training lowers the performance due to domain gaps). Also, we introduce a modulation module to adopt sensor-specific information (sensor type and ISO) to understand input data for image denoising. We conduct extensive experiments on public datasets with various smartphone and DSLR cameras, which show our proposed model outperforms prior work on cross-domain image denoising, given a small amount of image data from the target domain sensor.
Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
Mar 13, 2024



Despite recent advances in image-to-video generation, better controllability and local animation are less explored. Most existing image-to-video methods are not locally aware and tend to move the entire scene. However, human artists may need to control the movement of different objects or regions. Additionally, current I2V methods require users not only to describe the target motion but also to provide redundant detailed descriptions of frame contents. These two issues hinder the practical utilization of current I2V tools. In this paper, we propose a practical framework, named Follow-Your-Click, to achieve image animation with a simple user click (for specifying what to move) and a short motion prompt (for specifying how to move). Technically, we propose the first-frame masking strategy, which significantly improves the video generation quality, and a motion-augmented module equipped with a short motion prompt dataset to improve the short prompt following abilities of our model. To further control the motion speed, we propose flow-based motion magnitude control to control the speed of target movement more precisely. Our framework has simpler yet precise user control and better generation performance than previous methods. Extensive experiments compared with 7 baselines, including both commercial tools and research methods on 8 metrics, suggest the superiority of our approach. Project Page: https://follow-your-click.github.io/
TIP: Text-Driven Image Processing with Semantic and Restoration Instructions
Dec 18, 2023Text-driven diffusion models have become increasingly popular for various image editing tasks, including inpainting, stylization, and object replacement. However, it still remains an open research problem to adopt this language-vision paradigm for more fine-level image processing tasks, such as denoising, super-resolution, deblurring, and compression artifact removal. In this paper, we develop TIP, a Text-driven Image Processing framework that leverages natural language as a user-friendly interface to control the image restoration process. We consider the capacity of text information in two dimensions. First, we use content-related prompts to enhance the semantic alignment, effectively alleviating identity ambiguity in the restoration outcomes. Second, our approach is the first framework that supports fine-level instruction through language-based quantitative specification of the restoration strength, without the need for explicit task-specific design. In addition, we introduce a novel fusion mechanism that augments the existing ControlNet architecture by learning to rescale the generative prior, thereby achieving better restoration fidelity. Our extensive experiments demonstrate the superior restoration performance of TIP compared to the state of the arts, alongside offering the flexibility of text-based control over the restoration effects.