 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContact SLAM: An Active Tactile Exploration Policy Based on Physical Reasoning Utilized in Robotic Fine Blind Manipulation Tasks
Dec 11, 2025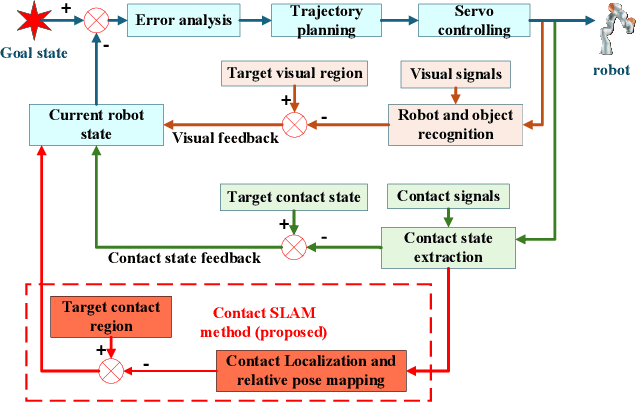
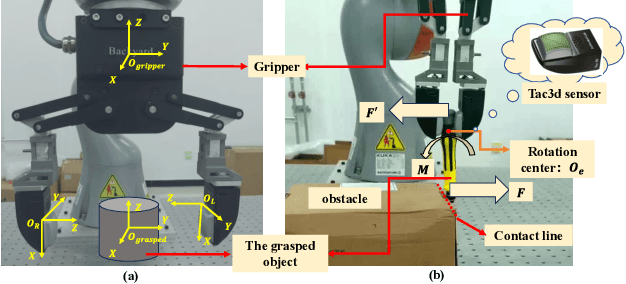
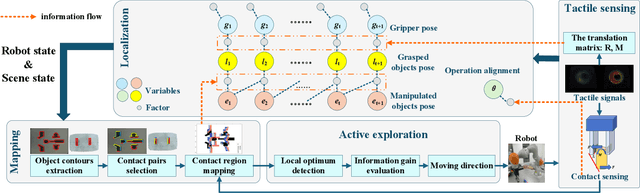
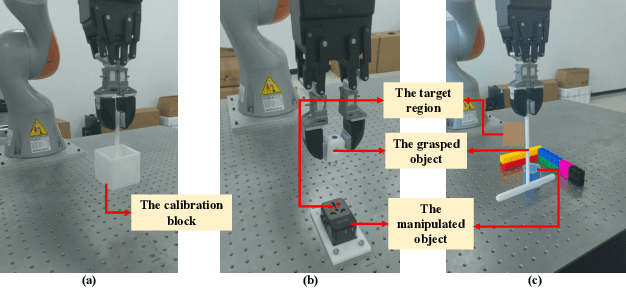
Contact-rich manipulation is difficult for robots to execute and requires accurate perception of the environment. In some scenarios, vision is occluded. The robot can then no longer obtain real-time scene state information through visual feedback. This is called ``blind manipulation". In this manuscript, a novel physically-driven contact cognition method, called ``Contact SLAM", is proposed. It estimates the state of the environment and achieves manipulation using only tactile sensing and prior knowledge of the scene. To maximize exploration efficiency, this manuscript also designs an active exploration policy. The policy gradually reduces uncertainties in the manipulation scene. The experimental results demonstrated the effectiveness and accuracy of the proposed method in several contact-rich tasks, including the difficult and delicate socket assembly task and block-pushing task.
DEKC: Data-Enable Control for Tethered Space Robot Deployment in the Presence of Uncertainty via Koopman Operator Theory
Jun 10, 2025This work focuses the deployment of tethered space robot in the presence of unknown uncertainty. A data-enable framework called DEKC which contains offline training part and online execution part is proposed to deploy tethered space robot in the presence of uncertainty. The main idea of this work is modeling the unknown uncertainty as a dynamical system, which enables high accuracy and convergence of capturing uncertainty. The core part of proposed framework is a proxy model of uncertainty, which is derived from data-driven Koopman theory and is separated with controller design. In the offline stage, the lifting functions associated with Koopman operator are parameterized with deep neural networks. Then by solving an optimization problem, the lifting functions are learned from sampling data. In the online execution stage, the proxy model cooperates the learned lifting functions obtained in the offline phase to capture the unknown uncertainty. Then the output of proxy model is compensated to the baseline controller such that the effect of uncertainty can be attenuated or even eliminated. Furthermore, considering some scenarios in which the performance of proxy model may weaken, a receding-horizon scheme is proposed to update the proxy model online. Finally, the extensive numerical simulations demonstrate the effectiveness of our proposed framework. The implementation of proposed DEKC framework is publicly available at https://github.com/NPU-RCIR/DEKC.git.
Curiosity-Diffuser: Curiosity Guide Diffusion Models for Reliability
Mar 19, 2025One of the bottlenecks in robotic intelligence is the instability of neural network models, which, unlike control models, lack a well-defined convergence domain and stability. This leads to risks when applying intelligence in the physical world. Specifically, imitation policy based on neural network may generate hallucinations, leading to inaccurate behaviors that impact the safety of real-world applications. To address this issue, this paper proposes the Curiosity-Diffuser, aimed at guiding the conditional diffusion model to generate trajectories with lower curiosity, thereby improving the reliability of policy. The core idea is to use a Random Network Distillation (RND) curiosity module to assess whether the model's behavior aligns with the training data, and then minimize curiosity by classifier guidance diffusion to reduce overgeneralization during inference. Additionally, we propose a computationally efficient metric for evaluating the reliability of the policy, measuring the similarity between the generated behaviors and the training dataset, to facilitate research about reliability learning. Finally, simulation verify the effectiveness and applicability of the proposed method to a variety of scenarios, showing that Curiosity-Diffuser significantly improves task performance and produces behaviors that are more similar to the training data. The code for this work is available at: github.com/CarlDegio/Curiosity-Diffuser
TIMRL: A Novel Meta-Reinforcement Learning Framework for Non-Stationary and Multi-Task Environments
Jan 13, 2025In recent years, meta-reinforcement learning (meta-RL) algorithm has been proposed to improve sample efficiency in the field of decision-making and control, enabling agents to learn new knowledge from a small number of samples. However, most research uses the Gaussian distribution to extract task representation, which is poorly adapted to tasks that change in non-stationary environment. To address this problem, we propose a novel meta-reinforcement learning method by leveraging Gaussian mixture model and the transformer network to construct task inference model. The Gaussian mixture model is utilized to extend the task representation and conduct explicit encoding of tasks. Specifically, the classification of tasks is encoded through transformer network to determine the Gaussian component corresponding to the task. By leveraging task labels, the transformer network is trained using supervised learning. We validate our method on MuJoCo benchmarks with non-stationary and multi-task environments. Experimental results demonstrate that the proposed method dramatically improves sample efficiency and accurately recognizes the classification of the tasks, while performing excellently in the environment.
Continuous Gaussian Process Pre-Optimization for Asynchronous Event-Inertial Odometry
Dec 12, 2024Event cameras, as bio-inspired sensors, are asynchronously triggered with high-temporal resolution compared to intensity cameras. Recent work has focused on fusing the event measurements with inertial measurements to enable ego-motion estimation in high-speed and HDR environments. However, existing methods predominantly rely on IMU preintegration designed mainly for synchronous sensors and discrete-time frameworks. In this paper, we propose a continuous-time preintegration method based on the Temporal Gaussian Process (TGP) called GPO. Concretely, we model the preintegration as a time-indexed motion trajectory and leverage an efficient two-step optimization to initialize the precision preintegration pseudo-measurements. Our method realizes a linear and constant time cost for initialization and query, respectively. To further validate the proposal, we leverage the GPO to design an asynchronous event-inertial odometry and compare with other asynchronous fusion schemes within the same odometry system. Experiments conducted on both public and own-collected datasets demonstrate that the proposed GPO offers significant advantages in terms of precision and efficiency, outperforming existing approaches in handling asynchronous sensor fusion.
Asynchronous Event-Inertial Odometry using a Unified Gaussian Process Regression Framework
Dec 04, 2024



Recent works have combined monocular event camera and inertial measurement unit to estimate the $SE(3)$ trajectory. However, the asynchronicity of event cameras brings a great challenge to conventional fusion algorithms. In this paper, we present an asynchronous event-inertial odometry under a unified Gaussian Process (GP) regression framework to naturally fuse asynchronous data associations and inertial measurements. A GP latent variable model is leveraged to build data-driven motion prior and acquire the analytical integration capacity. Then, asynchronous event-based feature associations and integral pseudo measurements are tightly coupled using the same GP framework. Subsequently, this fusion estimation problem is solved by underlying factor graph in a sliding-window manner. With consideration of sparsity, those historical states are marginalized orderly. A twin system is also designed for comparison, where the traditional inertial preintegration scheme is embedded in the GP-based framework to replace the GP latent variable model. Evaluations on public event-inertial datasets demonstrate the validity of both systems. Comparison experiments show competitive precision compared to the state-of-the-art synchronous scheme.
Self-reconfiguration Strategies for Space-distributed Spacecraft
Nov 26, 2024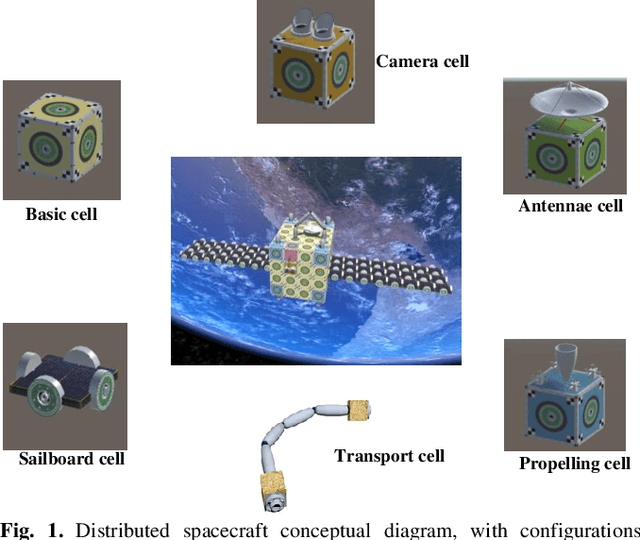
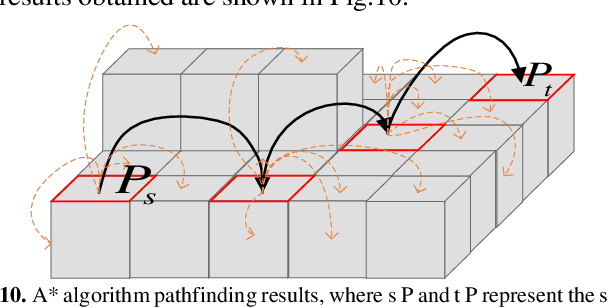
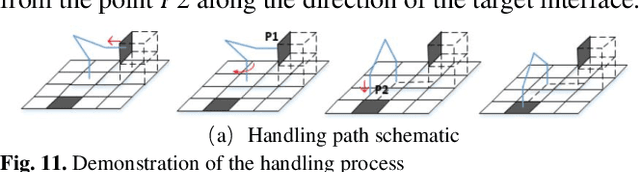
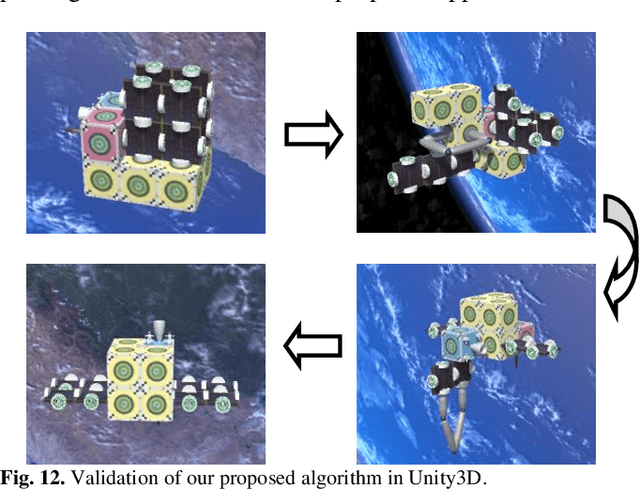
This paper proposes a distributed on-orbit spacecraft assembly algorithm, where future spacecraft can assemble modules with different functions on orbit to form a spacecraft structure with specific functions. This form of spacecraft organization has the advantages of reconfigurability, fast mission response and easy maintenance. Reasonable and efficient on-orbit self-reconfiguration algorithms play a crucial role in realizing the benefits of distributed spacecraft. This paper adopts the framework of imitation learning combined with reinforcement learning for strategy learning of module handling order. A robot arm motion algorithm is then designed to execute the handling sequence. We achieve the self-reconfiguration handling task by creating a map on the surface of the module, completing the path point planning of the robotic arm using A*. The joint planning of the robotic arm is then accomplished through forward and reverse kinematics. Finally, the results are presented in Unity3D.
Semantic-Geometric-Physical-Driven Robot Manipulation Skill Transfer via Skill Library and Tactile Representation
Nov 18, 2024



Deploying robots in open-world environments involves complex tasks characterized by long sequences and rich interactions, necessitating efficient transfer of robotic skills across diverse and complex scenarios. To address this challenge, we propose a skill library framework based on knowledge graphs, which endows robots with high-level skill awareness and spatial semantic understanding. The framework hierarchically organizes operational knowledge by constructing a "task graph" and a "scene graph" to represent task and scene semantic information, respectively. We introduce a "state graph" to facilitate interaction between high-level task planning and low-level scene information. Furthermore, we propose a hierarchical transfer framework for operational skills. At the task level, the framework integrates contextual learning and chain-of-thought prompting within a four-stage prompt paradigm, leveraging large language models' (LLMs) reasoning and generalization capabilities to achieve task-level subtask sequence transfer. At the motion level, an adaptive trajectory transfer method is developed using the A* algorithm and the skill library, enabling motion-level adaptive trajectory transfer. At the physical level, we introduce an adaptive contour extraction and posture perception method based on tactile perception. This method dynamically obtains high-precision contour and posture information from visual-tactile texture data and adjusts transferred skills, such as contact positions and postures, to ensure effectiveness in new environments. Experimental results validate the effectiveness of the proposed methods. Project website:https://github.com/MingchaoQi/skill_transfer
Neural Predictor for Flight Control with Payload
Oct 21, 2024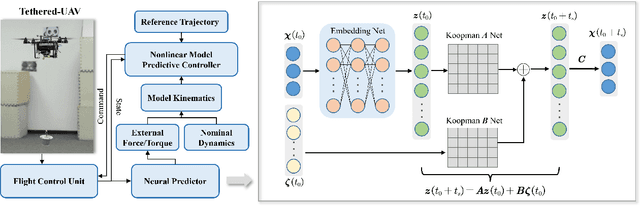
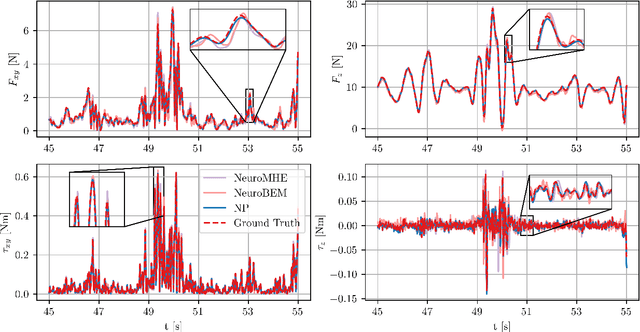

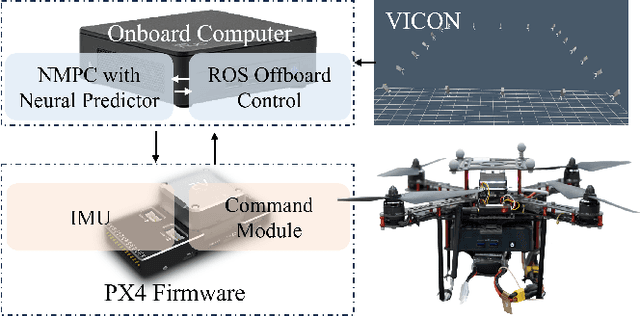
Aerial robotics for transporting suspended payloads as the form of freely-floating manipulator are growing great interest in recent years. However, the prior information of the payload, such as the mass, is always hard to obtain accurately in practice. The force/torque caused by payload and residual dynamics will introduce unmodeled perturbations to the system, which negatively affects the closed-loop performance. Different from estimation-like methods, this paper proposes Neural Predictor, a learning-based approach to model force/torque caused by payload and residual dynamics as a dynamical system. It results a hybrid model including both the first-principles dynamics and the learned dynamics. This hybrid model is then integrated into a MPC framework to improve closed-loop performance. Effectiveness of proposed framework is verified extensively in both numerical simulations and real-world flight experiments. The results indicate that our approach can capture force/torque caused by payload and residual dynamics accurately, respond quickly to the changes of them and improve the closed-loop performance significantly. In particular, Neural Predictor outperforms a state-of-the-art learning-based estimator and has reduced the force and torque estimation errors by up to 66.15% and 33.33% while using less samples.
An Integrating Comprehensive Trajectory Prediction with Risk Potential Field Method for Autonomous Driving
Apr 01, 2024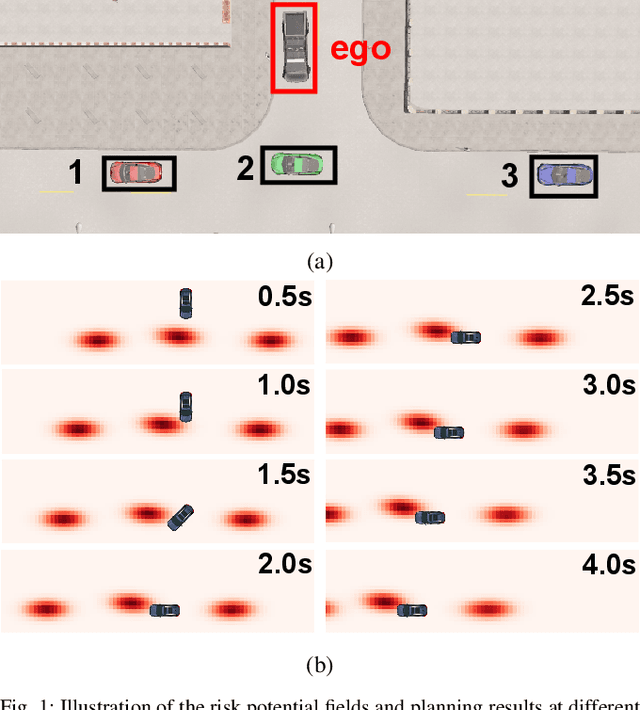
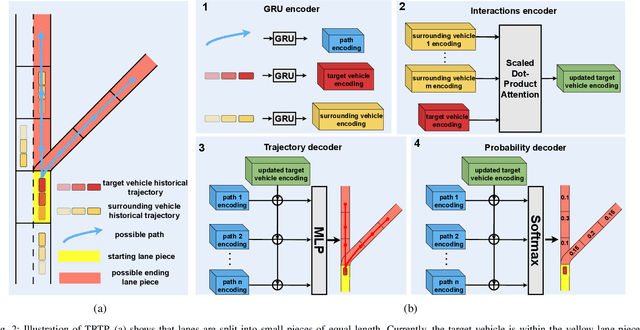
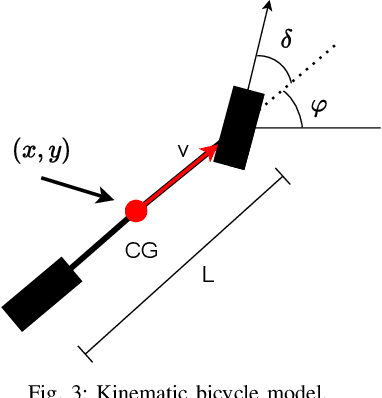
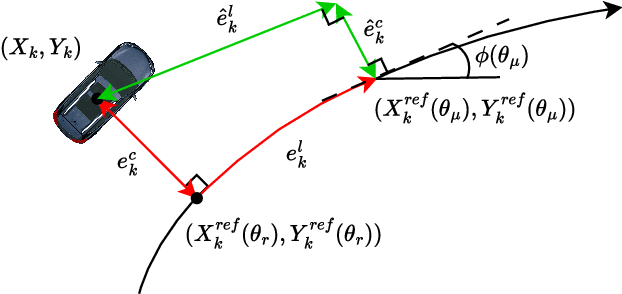
Due to the uncertainty of traffic participants' intentions, generating safe but not overly cautious behavior in interactive driving scenarios remains a formidable challenge for autonomous driving. In this paper, we address this issue by combining a deep learning-based trajectory prediction model with risk potential field-based motion planning. In order to comprehensively predict the possible future trajectories of other vehicles, we propose a target-region based trajectory prediction model(TRTP) which considers every region a vehicle may arrive in the future. After that, we construct a risk potential field at each future time step based on the prediction results of TRTP, and integrate risk value to the objective function of Model Predictive Contouring Control(MPCC). This enables the uncertainty of other vehicles to be taken into account during the planning process. Balancing between risk and progress along the reference path can achieve both driving safety and efficiency at the same time. We also demonstrate the security and effectiveness performance of our method in the CARLA simulator.