 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnique3D: High-Quality and Efficient 3D Mesh Generation from a Single Image
May 30, 2024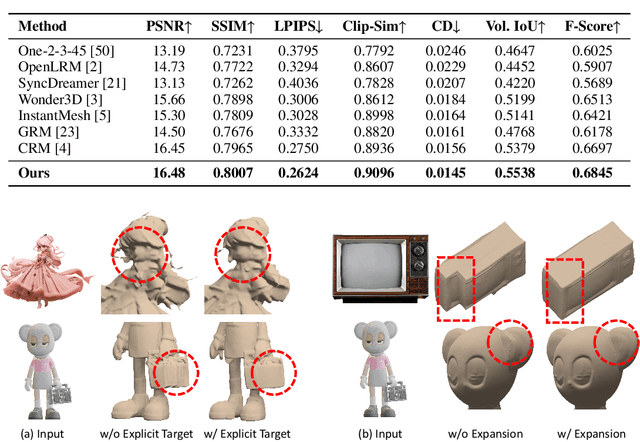
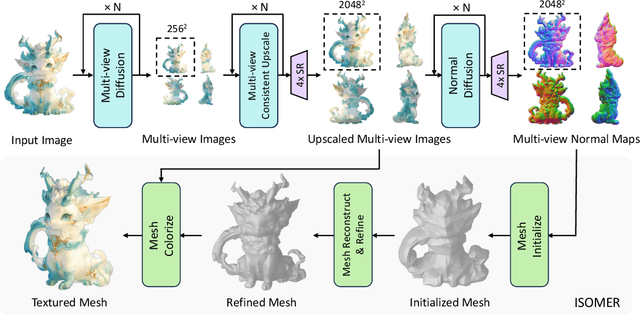


In this work, we introduce Unique3D, a novel image-to-3D framework for efficiently generating high-quality 3D meshes from single-view images, featuring state-of-the-art generation fidelity and strong generalizability. Previous methods based on Score Distillation Sampling (SDS) can produce diversified 3D results by distilling 3D knowledge from large 2D diffusion models, but they usually suffer from long per-case optimization time with inconsistent issues. Recent works address the problem and generate better 3D results either by finetuning a multi-view diffusion model or training a fast feed-forward model. However, they still lack intricate textures and complex geometries due to inconsistency and limited generated resolution. To simultaneously achieve high fidelity, consistency, and efficiency in single image-to-3D, we propose a novel framework Unique3D that includes a multi-view diffusion model with a corresponding normal diffusion model to generate multi-view images with their normal maps, a multi-level upscale process to progressively improve the resolution of generated orthographic multi-views, as well as an instant and consistent mesh reconstruction algorithm called ISOMER, which fully integrates the color and geometric priors into mesh results. Extensive experiments demonstrate that our Unique3D significantly outperforms other image-to-3D baselines in terms of geometric and textural details.
Flow Score Distillation for Diverse Text-to-3D Generation
May 16, 2024



Recent advancements in Text-to-3D generation have yielded remarkable progress, particularly through methods that rely on Score Distillation Sampling (SDS). While SDS exhibits the capability to create impressive 3D assets, it is hindered by its inherent maximum-likelihood-seeking essence, resulting in limited diversity in generation outcomes. In this paper, we discover that the Denoise Diffusion Implicit Models (DDIM) generation process (\ie PF-ODE) can be succinctly expressed using an analogue of SDS loss. One step further, one can see SDS as a generalized DDIM generation process. Following this insight, we show that the noise sampling strategy in the noise addition stage significantly restricts the diversity of generation results. To address this limitation, we present an innovative noise sampling approach and introduce a novel text-to-3D method called Flow Score Distillation (FSD). Our validation experiments across various text-to-image Diffusion Models demonstrate that FSD substantially enhances generation diversity without compromising quality.
An Integrating Comprehensive Trajectory Prediction with Risk Potential Field Method for Autonomous Driving
Apr 01, 2024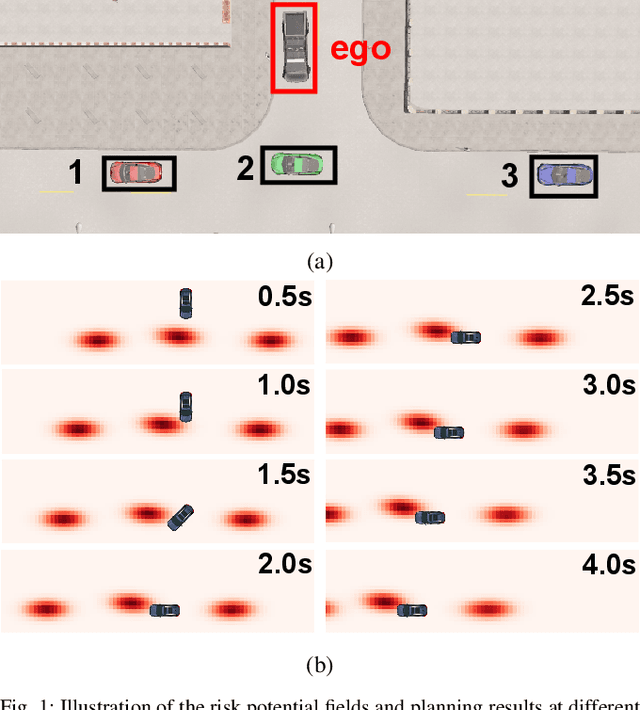
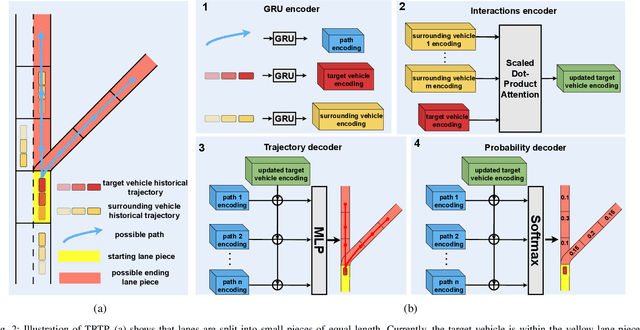
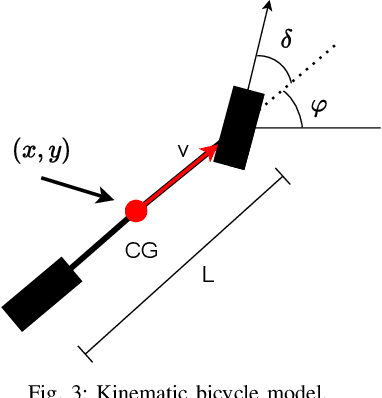
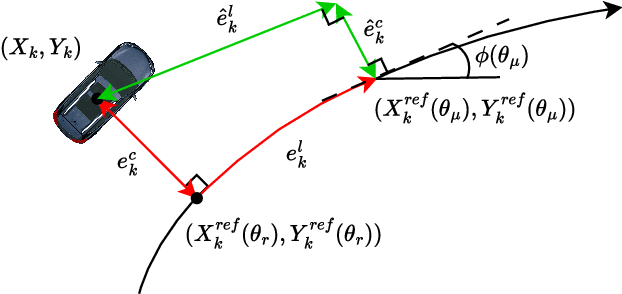
Due to the uncertainty of traffic participants' intentions, generating safe but not overly cautious behavior in interactive driving scenarios remains a formidable challenge for autonomous driving. In this paper, we address this issue by combining a deep learning-based trajectory prediction model with risk potential field-based motion planning. In order to comprehensively predict the possible future trajectories of other vehicles, we propose a target-region based trajectory prediction model(TRTP) which considers every region a vehicle may arrive in the future. After that, we construct a risk potential field at each future time step based on the prediction results of TRTP, and integrate risk value to the objective function of Model Predictive Contouring Control(MPCC). This enables the uncertainty of other vehicles to be taken into account during the planning process. Balancing between risk and progress along the reference path can achieve both driving safety and efficiency at the same time. We also demonstrate the security and effectiveness performance of our method in the CARLA simulator.
CORSD: Class-Oriented Relational Self Distillation
Apr 28, 2023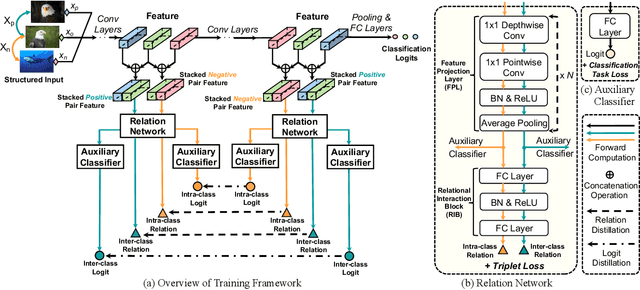
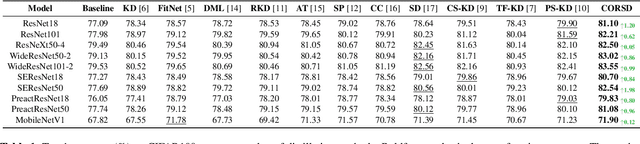
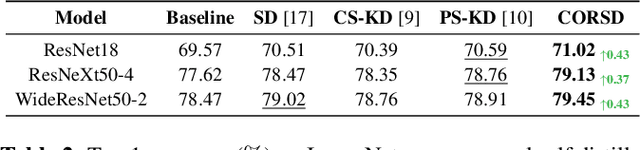
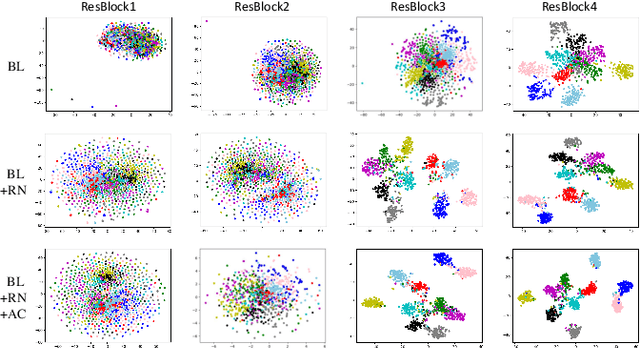
Knowledge distillation conducts an effective model compression method while holding some limitations:(1) the feature based distillation methods only focus on distilling the feature map but are lack of transferring the relation of data examples; (2) the relational distillation methods are either limited to the handcrafted functions for relation extraction, such as L2 norm, or weak in inter- and intra- class relation modeling. Besides, the feature divergence of heterogeneous teacher-student architectures may lead to inaccurate relational knowledge transferring. In this work, we propose a novel training framework named Class-Oriented Relational Self Distillation (CORSD) to address the limitations. The trainable relation networks are designed to extract relation of structured data input, and they enable the whole model to better classify samples by transferring the relational knowledge from the deepest layer of the model to shallow layers. Besides, auxiliary classifiers are proposed to make relation networks capture class-oriented relation that benefits classification task. Experiments demonstrate that CORSD achieves remarkable improvements. Compared to baseline, 3.8%, 1.5% and 4.5% averaged accuracy boost can be observed on CIFAR100, ImageNet and CUB-200-2011, respectively.
Light-weight Calibrator: a Separable Component for Unsupervised Domain Adaptation
Nov 28, 2019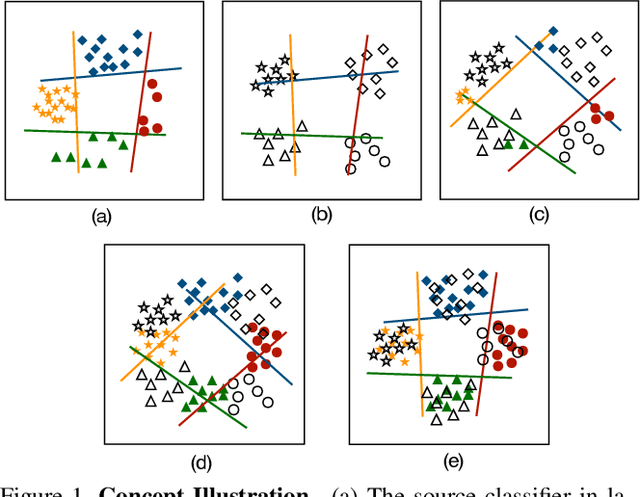
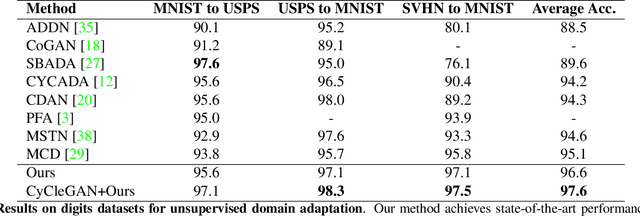
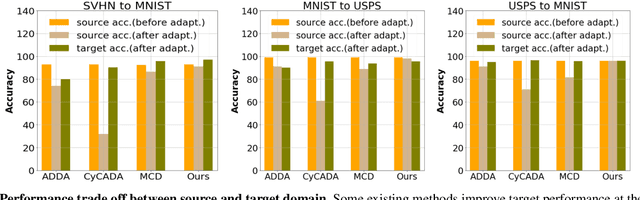

Existing domain adaptation methods aim at learning features that can be generalized among domains. These methods commonly require to update source classifier to adapt to the target domain and do not properly handle the trade off between the source domain and the target domain. In this work, instead of training a classifier to adapt to the target domain, we use a separable component called data calibrator to help the fixed source classifier recover discrimination power in the target domain, while preserving the source domain's performance. When the difference between two domains is small, the source classifier's representation is sufficient to perform well in the target domain and outperforms GAN-based methods in digits. Otherwise, the proposed method can leverage synthetic images generated by GANs to boost performance and achieve state-of-the-art performance in digits datasets and driving scene semantic segmentation. Our method empirically reveals that certain intriguing hints, which can be mitigated by adversarial attack to domain discriminators, are one of the sources for performance degradation under the domain shift. Code release is at https://github.com/yeshaokai/Calibrator-Domain-Adaptation.