 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVPP: Efficient Conditional 3D Generation via Voxel-Point Progressive Representation
Jul 28, 2023



Conditional 3D generation is undergoing a significant advancement, enabling the free creation of 3D content from inputs such as text or 2D images. However, previous approaches have suffered from low inference efficiency, limited generation categories, and restricted downstream applications. In this work, we revisit the impact of different 3D representations on generation quality and efficiency. We propose a progressive generation method through Voxel-Point Progressive Representation (VPP). VPP leverages structured voxel representation in the proposed Voxel Semantic Generator and the sparsity of unstructured point representation in the Point Upsampler, enabling efficient generation of multi-category objects. VPP can generate high-quality 8K point clouds within 0.2 seconds. Additionally, the masked generation Transformer allows for various 3D downstream tasks, such as generation, editing, completion, and pre-training. Extensive experiments demonstrate that VPP efficiently generates high-fidelity and diverse 3D shapes across different categories, while also exhibiting excellent representation transfer performance. Codes will be released on https://github.com/qizekun/VPP.
Revisiting Data Augmentation in Model Compression: An Empirical and Comprehensive Study
May 22, 2023The excellent performance of deep neural networks is usually accompanied by a large number of parameters and computations, which have limited their usage on the resource-limited edge devices. To address this issue, abundant methods such as pruning, quantization and knowledge distillation have been proposed to compress neural networks and achieved significant breakthroughs. However, most of these compression methods focus on the architecture or the training method of neural networks but ignore the influence from data augmentation. In this paper, we revisit the usage of data augmentation in model compression and give a comprehensive study on the relation between model sizes and their optimal data augmentation policy. To sum up, we mainly have the following three observations: (A) Models in different sizes prefer data augmentation with different magnitudes. Hence, in iterative pruning, data augmentation with varying magnitudes leads to better performance than data augmentation with a consistent magnitude. (B) Data augmentation with a high magnitude may significantly improve the performance of large models but harm the performance of small models. Fortunately, small models can still benefit from strong data augmentations by firstly learning them with "additional parameters" and then discard these "additional parameters" during inference. (C) The prediction of a pre-trained large model can be utilized to measure the difficulty of data augmentation. Thus it can be utilized as a criterion to design better data augmentation policies. We hope this paper may promote more research on the usage of data augmentation in model compression.
CORSD: Class-Oriented Relational Self Distillation
Apr 28, 2023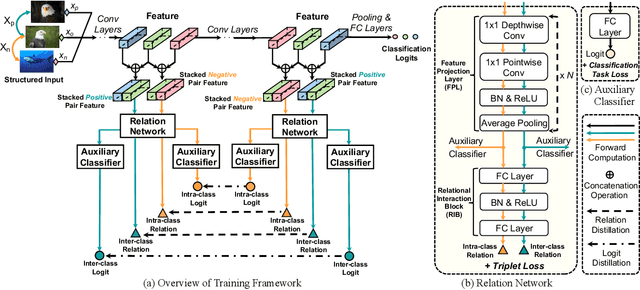
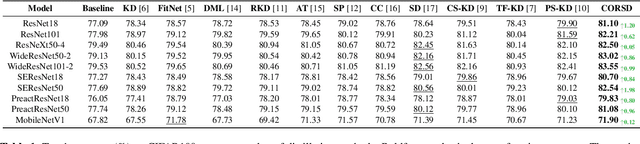
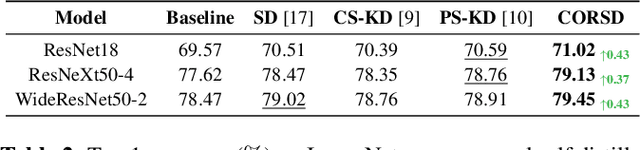
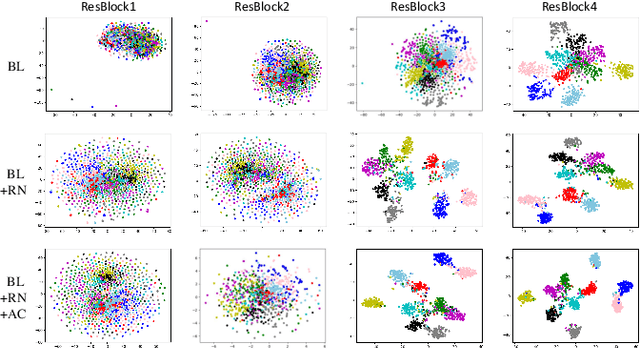
Knowledge distillation conducts an effective model compression method while holding some limitations:(1) the feature based distillation methods only focus on distilling the feature map but are lack of transferring the relation of data examples; (2) the relational distillation methods are either limited to the handcrafted functions for relation extraction, such as L2 norm, or weak in inter- and intra- class relation modeling. Besides, the feature divergence of heterogeneous teacher-student architectures may lead to inaccurate relational knowledge transferring. In this work, we propose a novel training framework named Class-Oriented Relational Self Distillation (CORSD) to address the limitations. The trainable relation networks are designed to extract relation of structured data input, and they enable the whole model to better classify samples by transferring the relational knowledge from the deepest layer of the model to shallow layers. Besides, auxiliary classifiers are proposed to make relation networks capture class-oriented relation that benefits classification task. Experiments demonstrate that CORSD achieves remarkable improvements. Compared to baseline, 3.8%, 1.5% and 4.5% averaged accuracy boost can be observed on CIFAR100, ImageNet and CUB-200-2011, respectively.