 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformGen: Dynamics-Based Topology Augmentation for Deformable Manipulation Policy Learning
Jun 24, 2026Demonstration augmentation is proposed for cost-efficient data acquisition, but existing methods are fundamentally limited in deformable manipulation due to two challenges: (1) the state space is high-dimensional with physics-induced constraints, making valid configurations impossible to reach via low-dimensional pose perturbations; and (2) trajectory transfer is non-equivariant, as material points no longer move rigidly together under deformation. We present DeformGen, a dynamics-based augmentation framework that achieves topological diversity for deformable objects. For the state challenge, DeformGen expands the valid state distribution by applying localized physical disturbances and forward-simulating the dynamics to obtain topology-coherent, physically plausible deformable states. For the trajectory challenge, DeformGen transfers source manipulation trajectories via deformation-field warping, which lifts per-particle displacements into a continuous spatial function to adapt the end-effector trajectory consistently with the deformed geometry. In this way, our method jointly augments the state distribution and its associated manipulation behavior. Experiments on high-fidelity deformable manipulation benchmarks show that DeformGen generally improves policy learning compared with training on the original demonstrations alone and with rigid-style augmentation baselines.
ImageWAM: Do World Action Models Really Need Video Generation, or Just Image Editing?
Jun 17, 2026World Action Models (WAMs) commonly rely on video generation to bridge visual world modeling and robot control. However, video-based WAMs face three coupled limitations: dense multi-frame future tokens make inference costly, full video prediction spends capacity on action-irrelevant temporal and appearance details, and long-horizon future imagination may introduce errors that mislead action prediction. These issues raise a simple question: Does world action model really need video generation? We propose ImageWAM, a simple WAM framework that repurposes pretrained image editing models for robot action prediction. In contrast to video generation, image editing provides a better-matched prior: it only needs to model a target-frame transformation, focuses on action-relevant current-to-target visual differences, and grounds task instructions to localized visual changes through edit pretraining. In practice, ImageWAM does not decode the target frame at inference time; instead, it conditions a flow-matching action expert on the KV caches produced by image-editing denoising, using them as a compact world-action context. ImageWAM outperforms standard VLA baselines and matching competitive WAMs without additional policy pretraining across different simulator and real-world experiments. It also reduces FLOPs to 1/6 and latency to 1/4 of video-based WAMs. Attention analysis further shows that editing caches focus on task-relevant change regions, supporting image editing as an effective alternative to video-based world-action modeling.
LIMMT: Less is More for Motion Tracking
Jun 05, 2026We argue that high-quality motion data can steer tracking policies toward better optimization trajectories early in training. In this work, we introduce LIMMT (Less Is More for Motion Tracking). To our knowledge, this is the first data-centric study for physics-based humanoid motion tracking. We go beyond simply removing low-quality and erroneous clips, but define motion data quality through three dimensions: physics feasibility, diversity, and complexity. We show that even training with under 3% of AMASS yields better tracking performance than training with the full dataset. We further conduct data cleaning on the estimated web-sourced mocap data. Extensive experiments and analyses validate the effectiveness of our framework.
Humanoid-GPT: Scaling Data and Structure for Zero-Shot Motion Tracking
Jun 02, 2026We introduce Humanoid-GPT, a GPT-style Transformer with causal attention trained on a billion-scale motion corpus for whole-body control. Unlike prior shallow MLP trackers constrained by scarce data and an agility-generalization trade-off, Humanoid-GPT is pre-trained on a 2B-frame retargeted corpus that unifies all major mocap datasets with large-scale in-house recordings. Scaling both data and model capacity yields a single generative Transformer that tracks highly dynamic behaviors while achieving unprecedented zero-shot generalization to unseen motions and control tasks. Extensive experiments and scaling analyses show that our model establishes a new performance frontier, demonstrating robust zero-shot generalization to unseen tasks while simultaneously tracking highly dynamic and complex motions.
Learning Athletic Humanoid Tennis Skills from Imperfect Human Motion Data
Mar 13, 2026Human athletes demonstrate versatile and highly-dynamic tennis skills to successfully conduct competitive rallies with a high-speed tennis ball. However, reproducing such behaviors on humanoid robots is difficult, partially due to the lack of perfect humanoid action data or human kinematic motion data in tennis scenarios as reference. In this work, we propose LATENT, a system that Learns Athletic humanoid TEnnis skills from imperfect human motioN daTa. The imperfect human motion data consist only of motion fragments that capture the primitive skills used when playing tennis rather than precise and complete human-tennis motion sequences from real-world tennis matches, thereby significantly reducing the difficulty of data collection. Our key insight is that, despite being imperfect, such quasi-realistic data still provide priors about human primitive skills in tennis scenarios. With further correction and composition, we learn a humanoid policy that can consistently strike incoming balls under a wide range of conditions and return them to target locations, while preserving natural motion styles. We also propose a series of designs for robust sim-to-real transfer and deploy our policy on the Unitree G1 humanoid robot. Our method achieves surprising results in the real world and can stably sustain multi-shot rallies with human players. Project page: https://zzk273.github.io/LATENT/
VLA-JEPA: Enhancing Vision-Language-Action Model with Latent World Model
Feb 14, 2026Pretraining Vision-Language-Action (VLA) policies on internet-scale video is appealing, yet current latent-action objectives often learn the wrong thing: they remain anchored to pixel variation rather than action-relevant state transitions, making them vulnerable to appearance bias, nuisance motion, and information leakage. We introduce VLA-JEPA, a JEPA-style pretraining framework that sidesteps these pitfalls by design. The key idea is leakage-free state prediction: a target encoder produces latent representations from future frames, while the student pathway sees only the current observation -- future information is used solely as supervision targets, never as input. By predicting in latent space rather than pixel space, VLA-JEPA learns dynamics abstractions that are robust to camera motion and irrelevant background changes. This yields a simple two-stage recipe -- JEPA pretraining followed by action-head fine-tuning -- without the multi-stage complexity of prior latent-action pipelines. Experiments on LIBERO, LIBERO-Plus, SimplerEnv and real-world manipulation tasks show that VLA-JEPA achieves consistent gains in generalization and robustness over existing methods.
ReWorld: Multi-Dimensional Reward Modeling for Embodied World Models
Jan 18, 2026Recently, video-based world models that learn to simulate the dynamics have gained increasing attention in robot learning. However, current approaches primarily emphasize visual generative quality while overlooking physical fidelity, dynamic consistency, and task logic, especially for contact-rich manipulation tasks, which limits their applicability to downstream tasks. To this end, we introduce ReWorld, a framework aimed to employ reinforcement learning to align the video-based embodied world models with physical realism, task completion capability, embodiment plausibility and visual quality. Specifically, we first construct a large-scale (~235K) video preference dataset and employ it to train a hierarchical reward model designed to capture multi-dimensional reward consistent with human preferences. We further propose a practical alignment algorithm that post-trains flow-based world models using this reward through a computationally efficient PPO-style algorithm. Comprehensive experiments and theoretical analysis demonstrate that ReWorld significantly improves the physical fidelity, logical coherence, embodiment and visual quality of generated rollouts, outperforming previous methods.
DexVLG: Dexterous Vision-Language-Grasp Model at Scale
Jul 03, 2025As large models gain traction, vision-language-action (VLA) systems are enabling robots to tackle increasingly complex tasks. However, limited by the difficulty of data collection, progress has mainly focused on controlling simple gripper end-effectors. There is little research on functional grasping with large models for human-like dexterous hands. In this paper, we introduce DexVLG, a large Vision-Language-Grasp model for Dexterous grasp pose prediction aligned with language instructions using single-view RGBD input. To accomplish this, we generate a dataset of 170 million dexterous grasp poses mapped to semantic parts across 174,000 objects in simulation, paired with detailed part-level captions. This large-scale dataset, named DexGraspNet 3.0, is used to train a VLM and flow-matching-based pose head capable of producing instruction-aligned grasp poses for tabletop objects. To assess DexVLG's performance, we create benchmarks in physics-based simulations and conduct real-world experiments. Extensive testing demonstrates DexVLG's strong zero-shot generalization capabilities-achieving over 76% zero-shot execution success rate and state-of-the-art part-grasp accuracy in simulation-and successful part-aligned grasps on physical objects in real-world scenarios.
SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
Feb 18, 2025


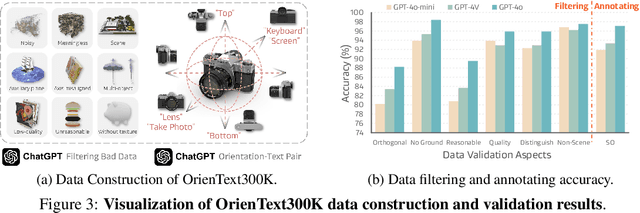
Spatial intelligence is a critical component of embodied AI, promoting robots to understand and interact with their environments. While recent advances have enhanced the ability of VLMs to perceive object locations and positional relationships, they still lack the capability to precisely understand object orientations-a key requirement for tasks involving fine-grained manipulations. Addressing this limitation not only requires geometric reasoning but also an expressive and intuitive way to represent orientation. In this context, we propose that natural language offers a more flexible representation space than canonical frames, making it particularly suitable for instruction-following robotic systems. In this paper, we introduce the concept of semantic orientation, which defines object orientations using natural language in a reference-frame-free manner (e.g., the ''plug-in'' direction of a USB or the ''handle'' direction of a knife). To support this, we construct OrienText300K, a large-scale dataset of 3D models annotated with semantic orientations that link geometric understanding to functional semantics. By integrating semantic orientation into a VLM system, we enable robots to generate manipulation actions with both positional and orientational constraints. Extensive experiments in simulation and real world demonstrate that our approach significantly enhances robotic manipulation capabilities, e.g., 48.7% accuracy on Open6DOR and 74.9% accuracy on SIMPLER.
Positional Prompt Tuning for Efficient 3D Representation Learning
Aug 21, 2024

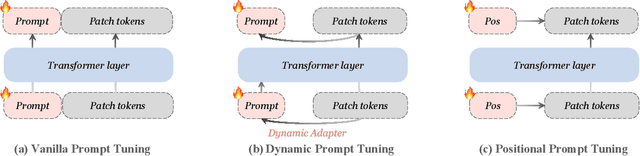

Point cloud analysis has achieved significant development and is well-performed in multiple downstream tasks like point cloud classification and segmentation, etc. Being conscious of the simplicity of the position encoding structure in Transformer-based architectures, we attach importance to the position encoding as a high-dimensional part and the patch encoder to offer multi-scale information. Together with the sequential Transformer, the whole module with position encoding comprehensively constructs a multi-scale feature abstraction module that considers both the local parts from the patch and the global parts from center points as position encoding. With only a few parameters, the position embedding module fits the setting of PEFT (Parameter-Efficient Fine-Tuning) tasks pretty well. Thus we unfreeze these parameters as a fine-tuning part. At the same time, we review the existing prompt and adapter tuning methods, proposing a fresh way of prompts and synthesizing them with adapters as dynamic adjustments. Our Proposed method of PEFT tasks, namely PPT, with only 1.05% of parameters for training, gets state-of-the-art results in several mainstream datasets, such as 95.01% accuracy in the ScanObjectNN OBJ_BG dataset. Codes will be released at https://github.com/zsc000722/PPT.