 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFloorPlan-VLN: A New Paradigm for Floor Plan Guided Vision-Language Navigation
Mar 18, 2026Existing Vision-Language Navigation (VLN) task requires agents to follow verbose instructions, ignoring some potentially useful global spatial priors, limiting their capability to reason about spatial structures. Although human-readable spatial schematics (e.g., floor plans) are ubiquitous in real-world buildings, current agents lack the cognitive ability to comprehend and utilize them. To bridge this gap, we introduce \textbf{FloorPlan-VLN}, a new paradigm that leverages structured semantic floor plans as global spatial priors to enable navigation with only concise instructions. We first construct the FloorPlan-VLN dataset, which comprises over 10k episodes across 72 scenes. It pairs more than 100 semantically annotated floor plans with Matterport3D-based navigation trajectories and concise instructions that omit step-by-step guidance. Then, we propose a simple yet effective method \textbf{FP-Nav} that uses a dual-view, spatio-temporally aligned video sequence, and auxiliary reasoning tasks to align observations, floor plans, and instructions. When evaluated under this new benchmark, our method significantly outperforms adapted state-of-the-art VLN baselines, achieving more than a 60\% relative improvement in navigation success rate. Furthermore, comprehensive noise modeling and real-world deployments demonstrate the feasibility and robustness of FP-Nav to actuation drift and floor plan distortions. These results validate the effectiveness of floor plan guided navigation and highlight FloorPlan-VLN as a promising step toward more spatially intelligent navigation.
DexVLG: Dexterous Vision-Language-Grasp Model at Scale
Jul 03, 2025As large models gain traction, vision-language-action (VLA) systems are enabling robots to tackle increasingly complex tasks. However, limited by the difficulty of data collection, progress has mainly focused on controlling simple gripper end-effectors. There is little research on functional grasping with large models for human-like dexterous hands. In this paper, we introduce DexVLG, a large Vision-Language-Grasp model for Dexterous grasp pose prediction aligned with language instructions using single-view RGBD input. To accomplish this, we generate a dataset of 170 million dexterous grasp poses mapped to semantic parts across 174,000 objects in simulation, paired with detailed part-level captions. This large-scale dataset, named DexGraspNet 3.0, is used to train a VLM and flow-matching-based pose head capable of producing instruction-aligned grasp poses for tabletop objects. To assess DexVLG's performance, we create benchmarks in physics-based simulations and conduct real-world experiments. Extensive testing demonstrates DexVLG's strong zero-shot generalization capabilities-achieving over 76% zero-shot execution success rate and state-of-the-art part-grasp accuracy in simulation-and successful part-aligned grasps on physical objects in real-world scenarios.
End-to-End Driving with Online Trajectory Evaluation via BEV World Model
Apr 02, 2025End-to-end autonomous driving has achieved remarkable progress by integrating perception, prediction, and planning into a fully differentiable framework. Yet, to fully realize its potential, an effective online trajectory evaluation is indispensable to ensure safety. By forecasting the future outcomes of a given trajectory, trajectory evaluation becomes much more effective. This goal can be achieved by employing a world model to capture environmental dynamics and predict future states. Therefore, we propose an end-to-end driving framework WoTE, which leverages a BEV World model to predict future BEV states for Trajectory Evaluation. The proposed BEV world model is latency-efficient compared to image-level world models and can be seamlessly supervised using off-the-shelf BEV-space traffic simulators. We validate our framework on both the NAVSIM benchmark and the closed-loop Bench2Drive benchmark based on the CARLA simulator, achieving state-of-the-art performance. Code is released at https://github.com/liyingyanUCAS/WoTE.
SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
Feb 18, 2025


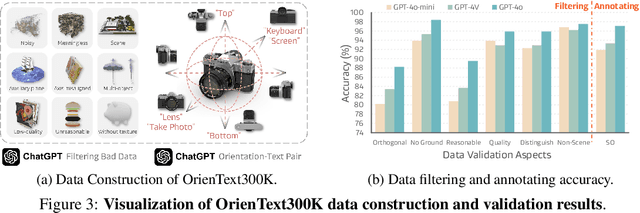
Spatial intelligence is a critical component of embodied AI, promoting robots to understand and interact with their environments. While recent advances have enhanced the ability of VLMs to perceive object locations and positional relationships, they still lack the capability to precisely understand object orientations-a key requirement for tasks involving fine-grained manipulations. Addressing this limitation not only requires geometric reasoning but also an expressive and intuitive way to represent orientation. In this context, we propose that natural language offers a more flexible representation space than canonical frames, making it particularly suitable for instruction-following robotic systems. In this paper, we introduce the concept of semantic orientation, which defines object orientations using natural language in a reference-frame-free manner (e.g., the ''plug-in'' direction of a USB or the ''handle'' direction of a knife). To support this, we construct OrienText300K, a large-scale dataset of 3D models annotated with semantic orientations that link geometric understanding to functional semantics. By integrating semantic orientation into a VLM system, we enable robots to generate manipulation actions with both positional and orientational constraints. Extensive experiments in simulation and real world demonstrate that our approach significantly enhances robotic manipulation capabilities, e.g., 48.7% accuracy on Open6DOR and 74.9% accuracy on SIMPLER.
DrivingDojo Dataset: Advancing Interactive and Knowledge-Enriched Driving World Model
Oct 14, 2024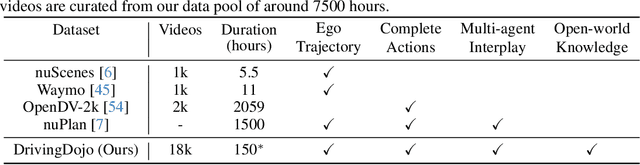
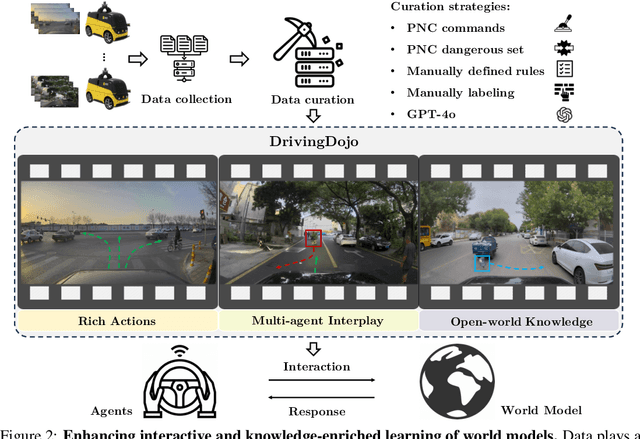

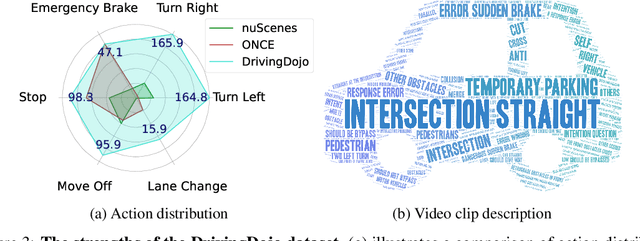
Driving world models have gained increasing attention due to their ability to model complex physical dynamics. However, their superb modeling capability is yet to be fully unleashed due to the limited video diversity in current driving datasets. We introduce DrivingDojo, the first dataset tailor-made for training interactive world models with complex driving dynamics. Our dataset features video clips with a complete set of driving maneuvers, diverse multi-agent interplay, and rich open-world driving knowledge, laying a stepping stone for future world model development. We further define an action instruction following (AIF) benchmark for world models and demonstrate the superiority of the proposed dataset for generating action-controlled future predictions.
Enhancing End-to-End Autonomous Driving with Latent World Model
Jun 12, 2024



End-to-end autonomous driving has garnered widespread attention. Current end-to-end approaches largely rely on the supervision from perception tasks such as detection, tracking, and map segmentation to aid in learning scene representations. However, these methods require extensive annotations, hindering the data scalability. To address this challenge, we propose a novel self-supervised method to enhance end-to-end driving without the need for costly labels. Specifically, our framework \textbf{LAW} uses a LAtent World model to predict future latent features based on the predicted ego actions and the latent feature of the current frame. The predicted latent features are supervised by the actually observed features in the future. This supervision jointly optimizes the latent feature learning and action prediction, which greatly enhances the driving performance. As a result, our approach achieves state-of-the-art performance in both open-loop and closed-loop benchmarks without costly annotations.
Rethinking Test-time Likelihood: The Likelihood Path Principle and Its Application to OOD Detection
Jan 10, 2024While likelihood is attractive in theory, its estimates by deep generative models (DGMs) are often broken in practice, and perform poorly for out of distribution (OOD) Detection. Various recent works started to consider alternative scores and achieved better performances. However, such recipes do not come with provable guarantees, nor is it clear that their choices extract sufficient information. We attempt to change this by conducting a case study on variational autoencoders (VAEs). First, we introduce the likelihood path (LPath) principle, generalizing the likelihood principle. This narrows the search for informative summary statistics down to the minimal sufficient statistics of VAEs' conditional likelihoods. Second, introducing new theoretic tools such as nearly essential support, essential distance and co-Lipschitzness, we obtain non-asymptotic provable OOD detection guarantees for certain distillation of the minimal sufficient statistics. The corresponding LPath algorithm demonstrates SOTA performances, even using simple and small VAEs with poor likelihood estimates. To our best knowledge, this is the first provable unsupervised OOD method that delivers excellent empirical results, better than any other VAEs based techniques. We use the same model as \cite{xiao2020likelihood}, open sourced from: https://github.com/XavierXiao/Likelihood-Regret
Driving into the Future: Multiview Visual Forecasting and Planning with World Model for Autonomous Driving
Nov 29, 2023In autonomous driving, predicting future events in advance and evaluating the foreseeable risks empowers autonomous vehicles to better plan their actions, enhancing safety and efficiency on the road. To this end, we propose Drive-WM, the first driving world model compatible with existing end-to-end planning models. Through a joint spatial-temporal modeling facilitated by view factorization, our model generates high-fidelity multiview videos in driving scenes. Building on its powerful generation ability, we showcase the potential of applying the world model for safe driving planning for the first time. Particularly, our Drive-WM enables driving into multiple futures based on distinct driving maneuvers, and determines the optimal trajectory according to the image-based rewards. Evaluation on real-world driving datasets verifies that our method could generate high-quality, consistent, and controllable multiview videos, opening up possibilities for real-world simulations and safe planning.
AutoCast++: Enhancing World Event Prediction with Zero-shot Ranking-based Context Retrieval
Oct 03, 2023



Machine-based prediction of real-world events is garnering attention due to its potential for informed decision-making. Whereas traditional forecasting predominantly hinges on structured data like time-series, recent breakthroughs in language models enable predictions using unstructured text. In particular, (Zou et al., 2022) unveils AutoCast, a new benchmark that employs news articles for answering forecasting queries. Nevertheless, existing methods still trail behind human performance. The cornerstone of accurate forecasting, we argue, lies in identifying a concise, yet rich subset of news snippets from a vast corpus. With this motivation, we introduce AutoCast++, a zero-shot ranking-based context retrieval system, tailored to sift through expansive news document collections for event forecasting. Our approach first re-ranks articles based on zero-shot question-passage relevance, honing in on semantically pertinent news. Following this, the chosen articles are subjected to zero-shot summarization to attain succinct context. Leveraging a pre-trained language model, we conduct both the relevance evaluation and article summarization without needing domain-specific training. Notably, recent articles can sometimes be at odds with preceding ones due to new facts or unanticipated incidents, leading to fluctuating temporal dynamics. To tackle this, our re-ranking mechanism gives preference to more recent articles, and we further regularize the multi-passage representation learning to align with human forecaster responses made on different dates. Empirical results underscore marked improvements across multiple metrics, improving the performance for multiple-choice questions (MCQ) by 48% and true/false (TF) questions by up to 8%.
Localization-Guided Track: A Deep Association Multi-Object Tracking Framework Based on Localization Confidence of Detections
Sep 18, 2023



In currently available literature, no tracking-by-detection (TBD) paradigm-based tracking method has considered the localization confidence of detection boxes. In most TBD-based methods, it is considered that objects of low detection confidence are highly occluded and thus it is a normal practice to directly disregard such objects or to reduce their priority in matching. In addition, appearance similarity is not a factor to consider for matching these objects. However, in terms of the detection confidence fusing classification and localization, objects of low detection confidence may have inaccurate localization but clear appearance; similarly, objects of high detection confidence may have inaccurate localization or unclear appearance; yet these objects are not further classified. In view of these issues, we propose Localization-Guided Track (LG-Track). Firstly, localization confidence is applied in MOT for the first time, with appearance clarity and localization accuracy of detection boxes taken into account, and an effective deep association mechanism is designed; secondly, based on the classification confidence and localization confidence, a more appropriate cost matrix can be selected and used; finally, extensive experiments have been conducted on MOT17 and MOT20 datasets. The results show that our proposed method outperforms the compared state-of-art tracking methods. For the benefit of the community, our code has been made publicly at https://github.com/mengting2023/LG-Track.