 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoClick: Lightweight Element Grounding Model for Autonomous GUI Interaction
Apr 27, 2026Graphical User Interface (GUI) element grounding (precisely locating elements on screenshots based on natural language instructions) is fundamental for agents interacting with GUIs. Deploying this capability directly on resource-constrained devices like mobile phones is increasingly critical for GUI agents requiring low latency. However, this goal faces a significant challenge, as current visual grounding methods typically employ large vision-language model (VLM) (more than 2.5B parameters), making them impractical for on-device execution due to memory and computational constraints. To address this, this paper introduces GoClick, a lightweight GUI element grounding VLM with only 230M parameters that achieves excellent visual grounding accuracy, even on par with significantly larger models. Simply downsizing existing decoder-only VLMs is a straightforward way to design a lightweight model, but our experiments reveal that this approach yields suboptimal results. Instead, we select an encoder-decoder architecture, which outperforms decoder-only alternatives at small parameter scales for GUI grounding tasks. Additionally, the limited capacity of small VLMs encourages us to develop a Progressive Data Refinement pipeline that utilizes task type filtering and data ratio adjustment to extract a high-quality 3.8M-sample core set from a 10.8M raw dataset. Training GoClick using this core set brings notable grounding accuracy gains. Our experiments show that GoClick excels on multiple GUI element grounding benchmarks while maintaining a small size and high inference speed. GoClick also enhances GUI agent performance when integrated into a device-cloud collaboration framework, where GoClick helps cloud-based task planners perform precise element localization and achieve higher success rates. We hope our method serves as a meaningful exploration within the GUI agent community.
AutoGUI-v2: A Comprehensive Multi-Modal GUI Functionality Understanding Benchmark
Apr 27, 2026Autonomous agents capable of navigating Graphical User Interfaces (GUIs) hold the potential to revolutionize digital productivity. However, achieving true digital autonomy extends beyond reactive element matching; it necessitates a predictive mental model of interface dynamics and the ability to foresee the "digital world state" resulting from interactions. Despite the perceptual capabilities of modern Vision-Language Models (VLMs), existing benchmarks remain bifurcated (focusing either on black-box task completion or static, shallow grounding), thereby failing to assess whether agents truly comprehend the implicit functionality and transition logic of GUIs. To bridge this gap, we introduce AutoGUI-v2, a comprehensive benchmark designed to evaluate deep GUI functionality understanding and interaction outcome prediction. We construct the benchmark using a novel VLM-human collaborative pipeline that recursively parses multi-platform screenshots into hierarchical functional regions to generate diverse evaluation tasks. Providing 2,753 tasks across six operating systems, AutoGUI-v2 rigorously tests agents on region and element-level semantics, grounding, and dynamic state prediction. Our evaluation reveals a striking dichotomy in VLMs: while open-source models fine-tuned on agent data (e.g., Qwen3-VL) excel at functional grounding, commercial models (e.g., Gemini-2.5-Pro-Thinking) dominate in functionality captioning. Crucially, all models struggle with complex interaction logic of uncommon actions, highlighting that deep functional understanding remains a significant hurdle. By systematically measuring these foundational capabilities, AutoGUI-v2 offers a new lens for advancing the next generation of GUI agents.
AutoGUI: Scaling GUI Grounding with Automatic Functionality Annotations from LLMs
Feb 04, 2025



User interface understanding with vision-language models has received much attention due to its potential for enabling next-generation software automation. However, existing UI datasets either only provide large-scale context-free element annotations or contextualized functional descriptions for elements at a much smaller scale. In this work, we propose the \methodname{} pipeline for automatically annotating UI elements with detailed functionality descriptions at scale. Specifically, we leverage large language models (LLMs) to infer element functionality by comparing the UI content changes before and after simulated interactions with specific UI elements. To improve annotation quality, we propose LLM-aided rejection and verification, eliminating invalid and incorrect annotations without human labor. We construct an \methodname{}-704k dataset using the proposed pipeline, featuring multi-resolution, multi-device screenshots, diverse data domains, and detailed functionality annotations that have never been provided by previous datasets. Human evaluation shows that the AutoGUI pipeline achieves annotation correctness comparable to trained human annotators. Extensive experimental results show that our \methodname{}-704k dataset remarkably enhances VLM's UI grounding capabilities, exhibits significant scaling effects, and outperforms existing web pre-training data types. We envision AutoGUI as a scalable pipeline for generating massive data to build GUI-oriented VLMs. AutoGUI dataset can be viewed at this anonymous URL: https://autogui-project.github.io/.
MemoNav: Working Memory Model for Visual Navigation
Feb 29, 2024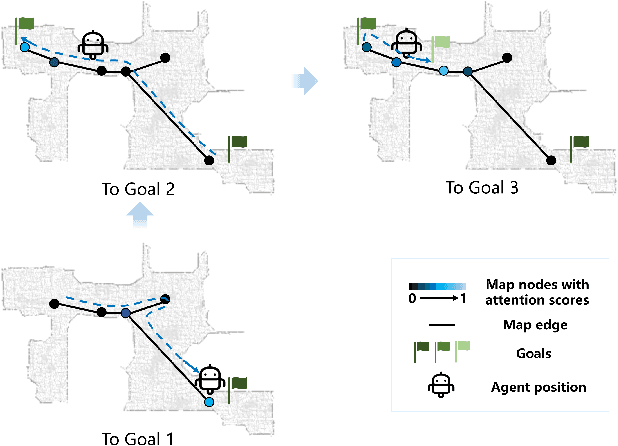
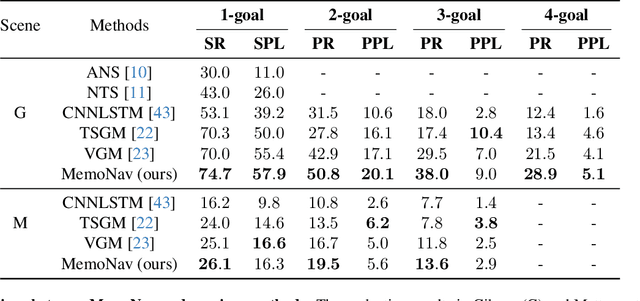
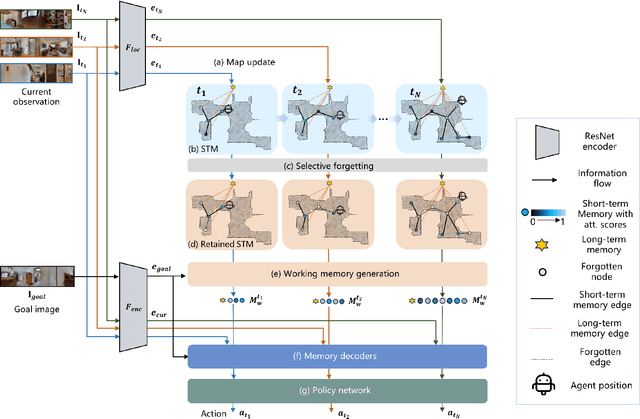
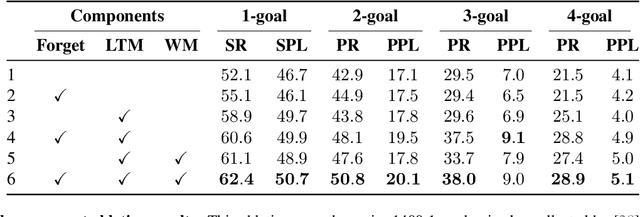
Image-goal navigation is a challenging task that requires an agent to navigate to a goal indicated by an image in unfamiliar environments. Existing methods utilizing diverse scene memories suffer from inefficient exploration since they use all historical observations for decision-making without considering the goal-relevant fraction. To address this limitation, we present MemoNav, a novel memory model for image-goal navigation, which utilizes a working memory-inspired pipeline to improve navigation performance. Specifically, we employ three types of navigation memory. The node features on a map are stored in the short-term memory (STM), as these features are dynamically updated. A forgetting module then retains the informative STM fraction to increase efficiency. We also introduce long-term memory (LTM) to learn global scene representations by progressively aggregating STM features. Subsequently, a graph attention module encodes the retained STM and the LTM to generate working memory (WM) which contains the scene features essential for efficient navigation. The synergy among these three memory types boosts navigation performance by enabling the agent to learn and leverage goal-relevant scene features within a topological map. Our evaluation on multi-goal tasks demonstrates that MemoNav significantly outperforms previous methods across all difficulty levels in both Gibson and Matterport3D scenes. Qualitative results further illustrate that MemoNav plans more efficient routes.
Driving into the Future: Multiview Visual Forecasting and Planning with World Model for Autonomous Driving
Nov 29, 2023In autonomous driving, predicting future events in advance and evaluating the foreseeable risks empowers autonomous vehicles to better plan their actions, enhancing safety and efficiency on the road. To this end, we propose Drive-WM, the first driving world model compatible with existing end-to-end planning models. Through a joint spatial-temporal modeling facilitated by view factorization, our model generates high-fidelity multiview videos in driving scenes. Building on its powerful generation ability, we showcase the potential of applying the world model for safe driving planning for the first time. Particularly, our Drive-WM enables driving into multiple futures based on distinct driving maneuvers, and determines the optimal trajectory according to the image-based rewards. Evaluation on real-world driving datasets verifies that our method could generate high-quality, consistent, and controllable multiview videos, opening up possibilities for real-world simulations and safe planning.
SheetCopilot: Bringing Software Productivity to the Next Level through Large Language Models
May 30, 2023



Computer end users have spent billions of hours completing daily tasks like tabular data processing and project timeline scheduling. Most of these tasks are repetitive and error-prone, yet most end users lack the skill of automating away these burdensome works. With the advent of large language models (LLMs), directing software with natural language user requests become a reachable goal. In this work, we propose a SheetCopilot agent which takes natural language task and control spreadsheet to fulfill the requirements. We propose a set of atomic actions as an abstraction of spreadsheet software functionalities. We further design a state machine-based task planning framework for LLMs to robustly interact with spreadsheets. We curate a representative dataset containing 221 spreadsheet control tasks and establish a fully automated evaluation pipeline for rigorously benchmarking the ability of LLMs in software control tasks. Our SheetCopilot correctly completes 44.3\% of tasks for a single generation, outperforming the strong code generation baseline by a wide margin. Our project page:https://sheetcopilot-demo.github.io/.
MemoNav: Selecting Informative Memories for Visual Navigation
Aug 20, 2022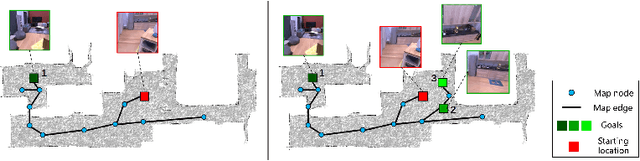
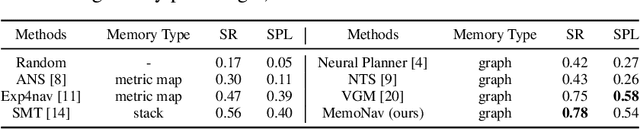
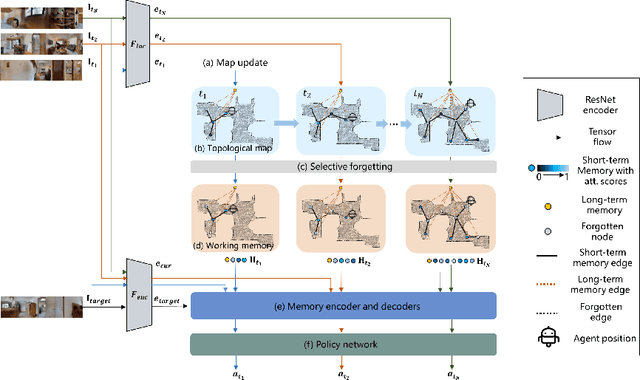
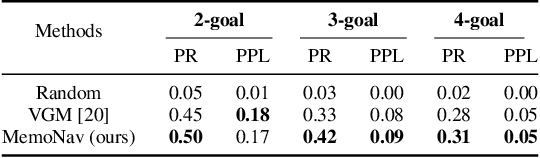
Image-goal navigation is a challenging task, as it requires the agent to navigate to a target indicated by an image in a previously unseen scene. Current methods introduce diverse memory mechanisms which save navigation history to solve this task. However, these methods use all observations in the memory for generating navigation actions without considering which fraction of this memory is informative. To address this limitation, we present the MemoNav, a novel memory mechanism for image-goal navigation, which retains the agent's informative short-term memory and long-term memory to improve the navigation performance on a multi-goal task. The node features on the agent's topological map are stored in the short-term memory, as these features are dynamically updated. To aid the short-term memory, we also generate long-term memory by continuously aggregating the short-term memory via a graph attention module. The MemoNav retains the informative fraction of the short-term memory via a forgetting module based on a Transformer decoder and then incorporates this retained short-term memory and the long-term memory into working memory. Lastly, the agent uses the working memory for action generation. We evaluate our model on a new multi-goal navigation dataset. The experimental results show that the MemoNav outperforms the SoTA methods by a large margin with a smaller fraction of navigation history. The results also empirically show that our model is less likely to be trapped in a deadlock, which further validates that the MemoNav improves the agent's navigation efficiency by reducing redundant steps.