 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCOP: Multi-UAV Collaborative Occupancy Prediction
Oct 14, 2025Unmanned Aerial Vehicle (UAV) swarm systems necessitate efficient collaborative perception mechanisms for diverse operational scenarios. Current Bird's Eye View (BEV)-based approaches exhibit two main limitations: bounding-box representations fail to capture complete semantic and geometric information of the scene, and their performance significantly degrades when encountering undefined or occluded objects. To address these limitations, we propose a novel multi-UAV collaborative occupancy prediction framework. Our framework effectively preserves 3D spatial structures and semantics through integrating a Spatial-Aware Feature Encoder and Cross-Agent Feature Integration. To enhance efficiency, we further introduce Altitude-Aware Feature Reduction to compactly represent scene information, along with a Dual-Mask Perceptual Guidance mechanism to adaptively select features and reduce communication overhead. Due to the absence of suitable benchmark datasets, we extend three datasets for evaluation: two virtual datasets (Air-to-Pred-Occ and UAV3D-Occ) and one real-world dataset (GauUScene-Occ). Experiments results demonstrate that our method achieves state-of-the-art accuracy, significantly outperforming existing collaborative methods while reducing communication overhead to only a fraction of previous approaches.
TC-Light: Temporally Consistent Relighting for Dynamic Long Videos
Jun 23, 2025Editing illumination in long videos with complex dynamics has significant value in various downstream tasks, including visual content creation and manipulation, as well as data scaling up for embodied AI through sim2real and real2real transfer. Nevertheless, existing video relighting techniques are predominantly limited to portrait videos or fall into the bottleneck of temporal consistency and computation efficiency. In this paper, we propose TC-Light, a novel paradigm characterized by the proposed two-stage post optimization mechanism. Starting from the video preliminarily relighted by an inflated video relighting model, it optimizes appearance embedding in the first stage to align global illumination. Then it optimizes the proposed canonical video representation, i.e., Unique Video Tensor (UVT), to align fine-grained texture and lighting in the second stage. To comprehensively evaluate performance, we also establish a long and highly dynamic video benchmark. Extensive experiments show that our method enables physically plausible relighting results with superior temporal coherence and low computation cost. The code and video demos are available at https://dekuliutesla.github.io/tclight/.
MemoNav: Working Memory Model for Visual Navigation
Feb 29, 2024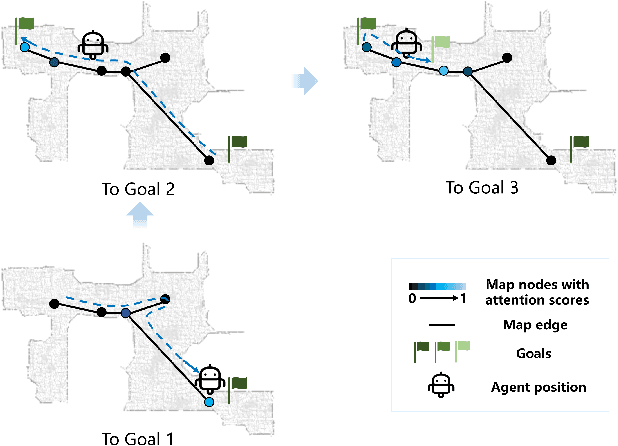
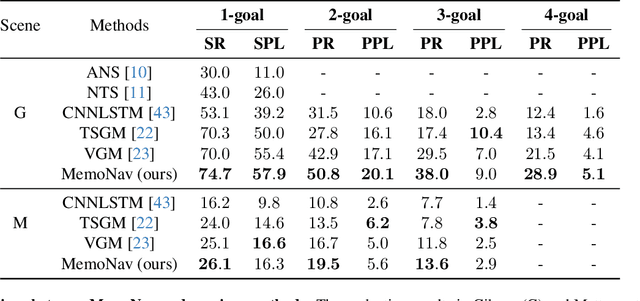
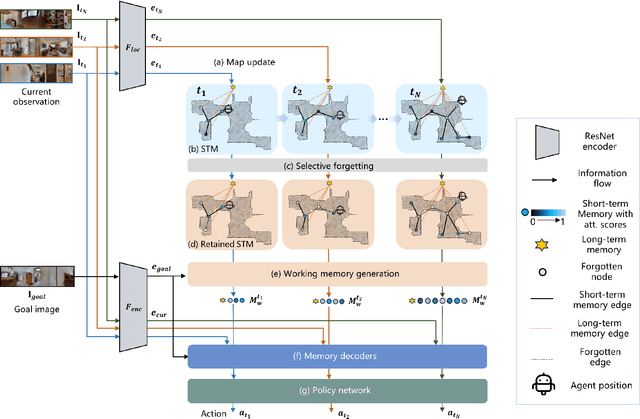
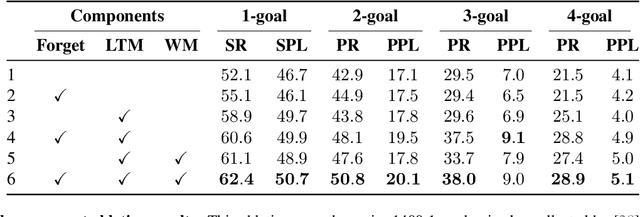
Image-goal navigation is a challenging task that requires an agent to navigate to a goal indicated by an image in unfamiliar environments. Existing methods utilizing diverse scene memories suffer from inefficient exploration since they use all historical observations for decision-making without considering the goal-relevant fraction. To address this limitation, we present MemoNav, a novel memory model for image-goal navigation, which utilizes a working memory-inspired pipeline to improve navigation performance. Specifically, we employ three types of navigation memory. The node features on a map are stored in the short-term memory (STM), as these features are dynamically updated. A forgetting module then retains the informative STM fraction to increase efficiency. We also introduce long-term memory (LTM) to learn global scene representations by progressively aggregating STM features. Subsequently, a graph attention module encodes the retained STM and the LTM to generate working memory (WM) which contains the scene features essential for efficient navigation. The synergy among these three memory types boosts navigation performance by enabling the agent to learn and leverage goal-relevant scene features within a topological map. Our evaluation on multi-goal tasks demonstrates that MemoNav significantly outperforms previous methods across all difficulty levels in both Gibson and Matterport3D scenes. Qualitative results further illustrate that MemoNav plans more efficient routes.
Informative Data Mining for One-Shot Cross-Domain Semantic Segmentation
Sep 25, 2023



Contemporary domain adaptation offers a practical solution for achieving cross-domain transfer of semantic segmentation between labeled source data and unlabeled target data. These solutions have gained significant popularity; however, they require the model to be retrained when the test environment changes. This can result in unbearable costs in certain applications due to the time-consuming training process and concerns regarding data privacy. One-shot domain adaptation methods attempt to overcome these challenges by transferring the pre-trained source model to the target domain using only one target data. Despite this, the referring style transfer module still faces issues with computation cost and over-fitting problems. To address this problem, we propose a novel framework called Informative Data Mining (IDM) that enables efficient one-shot domain adaptation for semantic segmentation. Specifically, IDM provides an uncertainty-based selection criterion to identify the most informative samples, which facilitates quick adaptation and reduces redundant training. We then perform a model adaptation method using these selected samples, which includes patch-wise mixing and prototype-based information maximization to update the model. This approach effectively enhances adaptation and mitigates the overfitting problem. In general, we provide empirical evidence of the effectiveness and efficiency of IDM. Our approach outperforms existing methods and achieves a new state-of-the-art one-shot performance of 56.7\%/55.4\% on the GTA5/SYNTHIA to Cityscapes adaptation tasks, respectively. The code will be released at \url{https://github.com/yxiwang/IDM}.
MemoNav: Selecting Informative Memories for Visual Navigation
Aug 20, 2022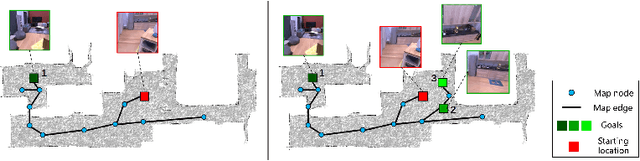
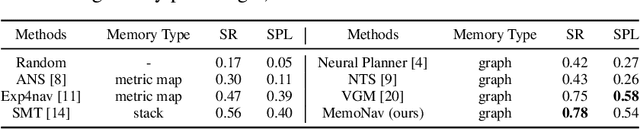
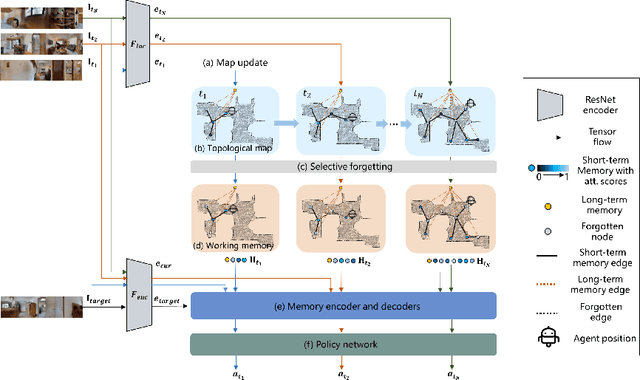
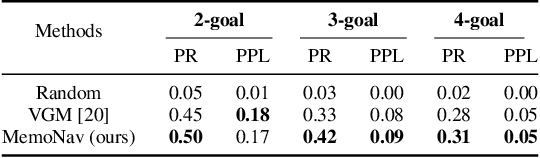
Image-goal navigation is a challenging task, as it requires the agent to navigate to a target indicated by an image in a previously unseen scene. Current methods introduce diverse memory mechanisms which save navigation history to solve this task. However, these methods use all observations in the memory for generating navigation actions without considering which fraction of this memory is informative. To address this limitation, we present the MemoNav, a novel memory mechanism for image-goal navigation, which retains the agent's informative short-term memory and long-term memory to improve the navigation performance on a multi-goal task. The node features on the agent's topological map are stored in the short-term memory, as these features are dynamically updated. To aid the short-term memory, we also generate long-term memory by continuously aggregating the short-term memory via a graph attention module. The MemoNav retains the informative fraction of the short-term memory via a forgetting module based on a Transformer decoder and then incorporates this retained short-term memory and the long-term memory into working memory. Lastly, the agent uses the working memory for action generation. We evaluate our model on a new multi-goal navigation dataset. The experimental results show that the MemoNav outperforms the SoTA methods by a large margin with a smaller fraction of navigation history. The results also empirically show that our model is less likely to be trapped in a deadlock, which further validates that the MemoNav improves the agent's navigation efficiency by reducing redundant steps.