 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoNav: Selecting Informative Memories for Visual Navigation
Paper and Code
Aug 20, 2022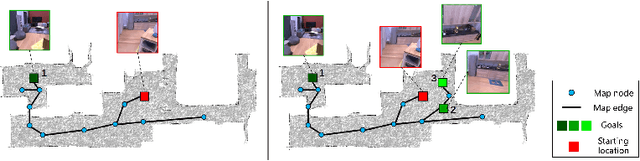
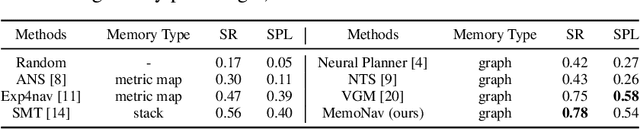
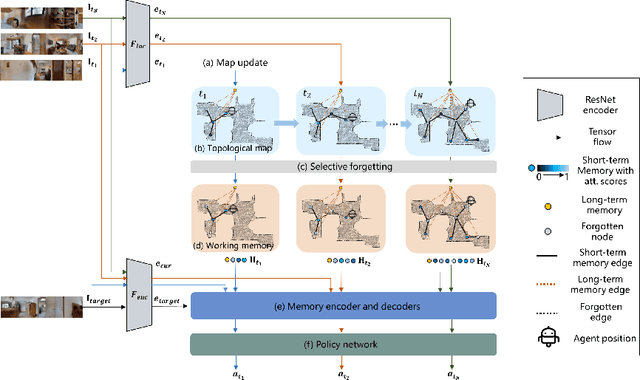
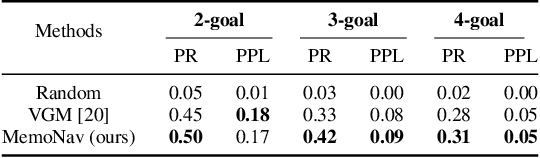
Image-goal navigation is a challenging task, as it requires the agent to navigate to a target indicated by an image in a previously unseen scene. Current methods introduce diverse memory mechanisms which save navigation history to solve this task. However, these methods use all observations in the memory for generating navigation actions without considering which fraction of this memory is informative. To address this limitation, we present the MemoNav, a novel memory mechanism for image-goal navigation, which retains the agent's informative short-term memory and long-term memory to improve the navigation performance on a multi-goal task. The node features on the agent's topological map are stored in the short-term memory, as these features are dynamically updated. To aid the short-term memory, we also generate long-term memory by continuously aggregating the short-term memory via a graph attention module. The MemoNav retains the informative fraction of the short-term memory via a forgetting module based on a Transformer decoder and then incorporates this retained short-term memory and the long-term memory into working memory. Lastly, the agent uses the working memory for action generation. We evaluate our model on a new multi-goal navigation dataset. The experimental results show that the MemoNav outperforms the SoTA methods by a large margin with a smaller fraction of navigation history. The results also empirically show that our model is less likely to be trapped in a deadlock, which further validates that the MemoNav improves the agent's navigation efficiency by reducing redundant steps.