 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Triplet Restoration: A Novel Protocol for Hierarchical Table Understanding in Large Language Models
May 29, 2026Table question answering requires models to recover semantic relations encoded implicitly by two-dimensional layout, merged cells, and hierarchical headers. Current pipelines typically use HTML or Markdown as intermediate table representations, but these layout-oriented serializations introduce markup overhead and require large language models to infer header-cell alignments from row and column spans. We propose Semantic Triplet Restoration (STR), a protocol that rewrites each cell as an atomic fact <item path, feature path, value>, where the item path specifies the row-wise entity, the feature path specifies the hierarchical attribute, and the value contains the cell content. We also present TripletQL, a lightweight query-aware router that uses STR to select an appropriate rendering or filtered subset of triplets for each question. Across four Chinese and English table-QA benchmarks, STR matches or improves upon HTML-based baselines while reducing input tokens. The relative benefit grows for smaller language models and longer table contexts, suggesting that explicit semantic representations are especially useful under constrained inference budgets. Code and data are available at https://github.com/Phoenix-ni/STR.git .
Surg-R1: A Hierarchical Reasoning Foundation Model for Scalable and Interpretable Surgical Decision Support with Multi-Center Clinical Validation
Mar 12, 2026Surgical scene understanding demands not only accurate predictions but also interpretable reasoning that surgeons can verify against clinical expertise. However, existing surgical vision-language models generate predictions without reasoning chains, and general-purpose reasoning models fail on compositional surgical tasks without domain-specific knowledge. We present Surg-R1, a surgical Vision-Language Model that addresses this gap through hierarchical reasoning trained via a four-stage pipeline. Our approach introduces three key contributions: (1) a three-level reasoning hierarchy decomposing surgical interpretation into perceptual grounding, relational understanding, and contextual reasoning; (2) the largest surgical chain-of-thought dataset with 320,000 reasoning pairs; and (3) a four-stage training pipeline progressing from supervised fine-tuning to group relative policy optimization and iterative self-improvement. Evaluation on SurgBench, comprising six public benchmarks and six multi-center external validation datasets from five institutions, demonstrates that Surg-R1 achieves the highest Arena Score (64.9%) on public benchmarks versus Gemini 3.0 Pro (46.1%) and GPT-5.1 (37.9%), outperforming both proprietary reasoning models and specialized surgical VLMs on the majority of tasks spanning instrument localization, triplet recognition, phase recognition, action recognition, and critical view of safety assessment, with a 15.2 percentage point improvement over the strongest surgical baseline on external validation.
DynVLA: Learning World Dynamics for Action Reasoning in Autonomous Driving
Mar 11, 2026We propose DynVLA, a driving VLA model that introduces a new CoT paradigm termed Dynamics CoT. DynVLA forecasts compact world dynamics before action generation, enabling more informed and physically grounded decision-making. To obtain compact dynamics representations, DynVLA introduces a Dynamics Tokenizer that compresses future evolution into a small set of dynamics tokens. Considering the rich environment dynamics in interaction-intensive driving scenarios, DynVLA decouples ego-centric and environment-centric dynamics, yielding more accurate world dynamics modeling. We then train DynVLA to generate dynamics tokens before actions through SFT and RFT, improving decision quality while maintaining latency-efficient inference. Compared to Textual CoT, which lacks fine-grained spatiotemporal understanding, and Visual CoT, which introduces substantial redundancy due to dense image prediction, Dynamics CoT captures the evolution of the world in a compact, interpretable, and efficient form. Extensive experiments on NAVSIM, Bench2Drive, and a large-scale in-house dataset demonstrate that DynVLA consistently outperforms Textual CoT and Visual CoT methods, validating the effectiveness and practical value of Dynamics CoT.
Scaling World Model for Hierarchical Manipulation Policies
Feb 12, 2026Vision-Language-Action (VLA) models are promising for generalist robot manipulation but remain brittle in out-of-distribution (OOD) settings, especially with limited real-robot data. To resolve the generalization bottleneck, we introduce a hierarchical Vision-Language-Action framework \our{} that leverages the generalization of large-scale pre-trained world model for robust and generalizable VIsual Subgoal TAsk decomposition VISTA. Our hierarchical framework \our{} consists of a world model as the high-level planner and a VLA as the low-level executor. The high-level world model first divides manipulation tasks into subtask sequences with goal images, and the low-level policy follows the textual and visual guidance to generate action sequences. Compared to raw textual goal specification, these synthesized goal images provide visually and physically grounded details for low-level policies, making it feasible to generalize across unseen objects and novel scenarios. We validate both visual goal synthesis and our hierarchical VLA policies in massive out-of-distribution scenarios, and the performance of the same-structured VLA in novel scenarios could boost from 14% to 69% with the guidance generated by the world model. Results demonstrate that our method outperforms previous baselines with a clear margin, particularly in out-of-distribution scenarios. Project page: \href{https://vista-wm.github.io/}{https://vista-wm.github.io}
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Oct 14, 2025



Scaling Vision-Language-Action (VLA) models on large-scale data offers a promising path to achieving a more generalized driving intelligence. However, VLA models are limited by a ``supervision deficit'': the vast model capacity is supervised by sparse, low-dimensional actions, leaving much of their representational power underutilized. To remedy this, we propose \textbf{DriveVLA-W0}, a training paradigm that employs world modeling to predict future images. This task generates a dense, self-supervised signal that compels the model to learn the underlying dynamics of the driving environment. We showcase the paradigm's versatility by instantiating it for two dominant VLA archetypes: an autoregressive world model for VLAs that use discrete visual tokens, and a diffusion world model for those operating on continuous visual features. Building on the rich representations learned from world modeling, we introduce a lightweight action expert to address the inference latency for real-time deployment. Extensive experiments on the NAVSIM v1/v2 benchmark and a 680x larger in-house dataset demonstrate that DriveVLA-W0 significantly outperforms BEV and VLA baselines. Crucially, it amplifies the data scaling law, showing that performance gains accelerate as the training dataset size increases.
K2-Think: A Parameter-Efficient Reasoning System
Sep 09, 2025K2-Think is a reasoning system that achieves state-of-the-art performance with a 32B parameter model, matching or surpassing much larger models like GPT-OSS 120B and DeepSeek v3.1. Built on the Qwen2.5 base model, our system shows that smaller models can compete at the highest levels by combining advanced post-training and test-time computation techniques. The approach is based on six key technical pillars: Long Chain-of-thought Supervised Finetuning, Reinforcement Learning with Verifiable Rewards (RLVR), Agentic planning prior to reasoning, Test-time Scaling, Speculative Decoding, and Inference-optimized Hardware, all using publicly available open-source datasets. K2-Think excels in mathematical reasoning, achieving state-of-the-art scores on public benchmarks for open-source models, while also performing strongly in other areas such as Code and Science. Our results confirm that a more parameter-efficient model like K2-Think 32B can compete with state-of-the-art systems through an integrated post-training recipe that includes long chain-of-thought training and strategic inference-time enhancements, making open-source reasoning systems more accessible and affordable. K2-Think is freely available at k2think.ai, offering best-in-class inference speeds of over 2,000 tokens per second per request via the Cerebras Wafer-Scale Engine.
Unified Vision-Language-Action Model
Jun 24, 2025



Vision-language-action models (VLAs) have garnered significant attention for their potential in advancing robotic manipulation. However, previous approaches predominantly rely on the general comprehension capabilities of vision-language models (VLMs) to generate action signals, often overlooking the rich temporal and causal structure embedded in visual observations. In this paper, we present UniVLA, a unified and native multimodal VLA model that autoregressively models vision, language, and action signals as discrete token sequences. This formulation enables flexible multimodal tasks learning, particularly from large-scale video data. By incorporating world modeling during post-training, UniVLA captures causal dynamics from videos, facilitating effective transfer to downstream policy learning--especially for long-horizon tasks. Our approach sets new state-of-the-art results across several widely used simulation benchmarks, including CALVIN, LIBERO, and Simplenv-Bridge, significantly surpassing previous methods. For example, UniVLA achieves 95.5% average success rate on LIBERO benchmark, surpassing pi0-FAST's 85.5%. We further demonstrate its broad applicability on real-world ALOHA manipulation and autonomous driving.
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
Jun 17, 2025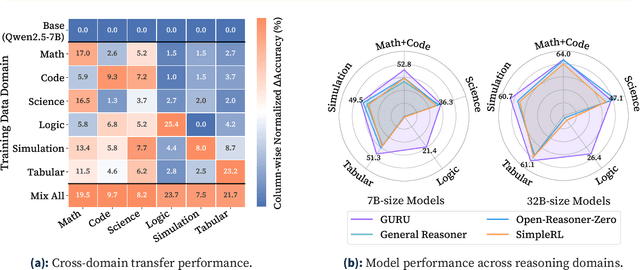
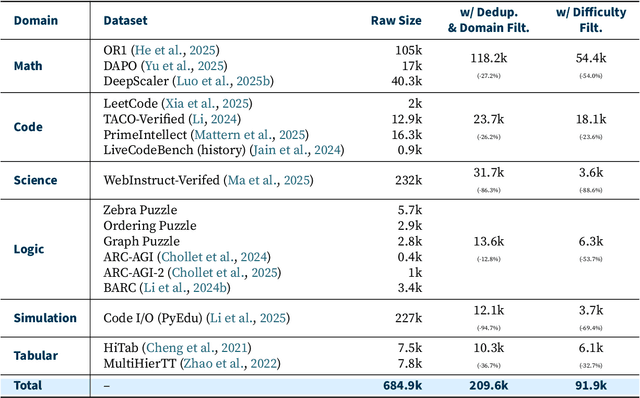
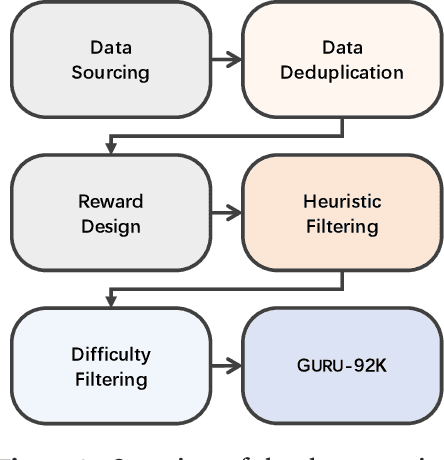

Reinforcement learning (RL) has emerged as a promising approach to improve large language model (LLM) reasoning, yet most open efforts focus narrowly on math and code, limiting our understanding of its broader applicability to general reasoning. A key challenge lies in the lack of reliable, scalable RL reward signals across diverse reasoning domains. We introduce Guru, a curated RL reasoning corpus of 92K verifiable examples spanning six reasoning domains--Math, Code, Science, Logic, Simulation, and Tabular--each built through domain-specific reward design, deduplication, and filtering to ensure reliability and effectiveness for RL training. Based on Guru, we systematically revisit established findings in RL for LLM reasoning and observe significant variation across domains. For example, while prior work suggests that RL primarily elicits existing knowledge from pretrained models, our results reveal a more nuanced pattern: domains frequently seen during pretraining (Math, Code, Science) easily benefit from cross-domain RL training, while domains with limited pretraining exposure (Logic, Simulation, and Tabular) require in-domain training to achieve meaningful performance gains, suggesting that RL is likely to facilitate genuine skill acquisition. Finally, we present Guru-7B and Guru-32B, two models that achieve state-of-the-art performance among open models RL-trained with publicly available data, outperforming best baselines by 7.9% and 6.7% on our 17-task evaluation suite across six reasoning domains. We also show that our models effectively improve the Pass@k performance of their base models, particularly on complex tasks less likely to appear in pretraining data. We release data, models, training and evaluation code to facilitate general-purpose reasoning at: https://github.com/LLM360/Reasoning360
Teacher Motion Priors: Enhancing Robot Locomotion over Challenging Terrain
Apr 14, 2025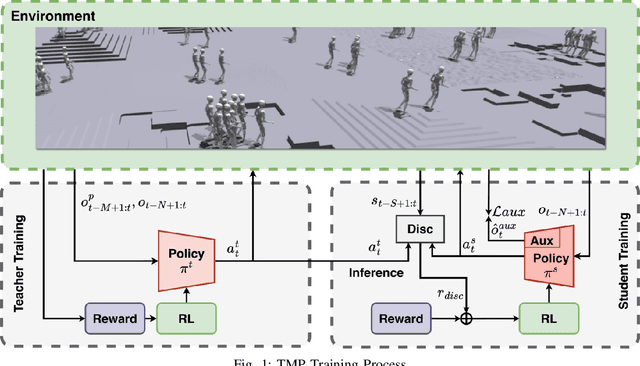
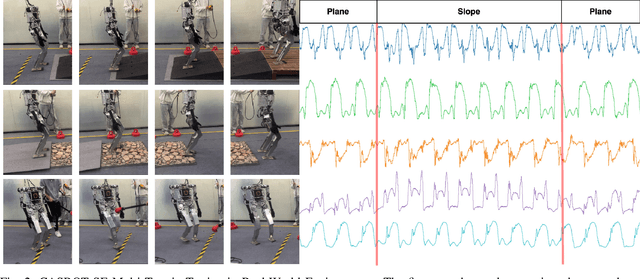
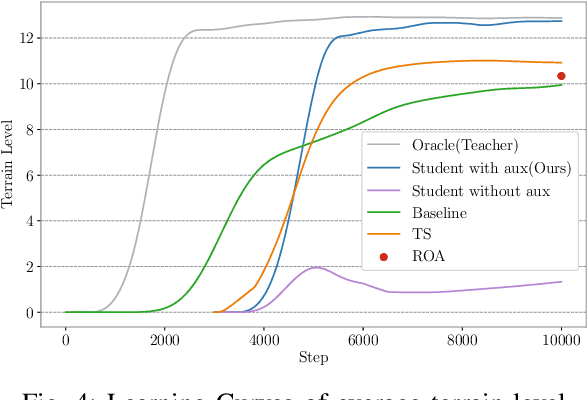
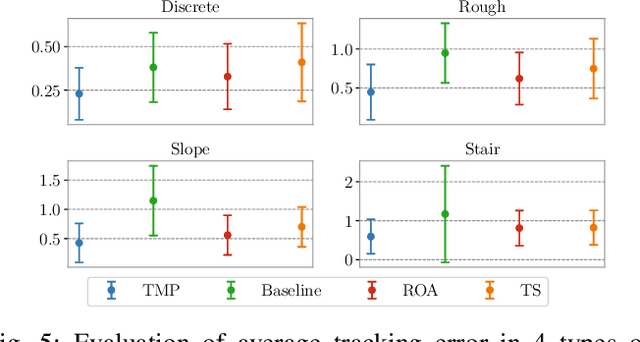
Achieving robust locomotion on complex terrains remains a challenge due to high dimensional control and environmental uncertainties. This paper introduces a teacher prior framework based on the teacher student paradigm, integrating imitation and auxiliary task learning to improve learning efficiency and generalization. Unlike traditional paradigms that strongly rely on encoder-based state embeddings, our framework decouples the network design, simplifying the policy network and deployment. A high performance teacher policy is first trained using privileged information to acquire generalizable motion skills. The teacher's motion distribution is transferred to the student policy, which relies only on noisy proprioceptive data, via a generative adversarial mechanism to mitigate performance degradation caused by distributional shifts. Additionally, auxiliary task learning enhances the student policy's feature representation, speeding up convergence and improving adaptability to varying terrains. The framework is validated on a humanoid robot, showing a great improvement in locomotion stability on dynamic terrains and significant reductions in development costs. This work provides a practical solution for deploying robust locomotion strategies in humanoid robots.
Palmprint De-Identification Using Diffusion Model for High-Quality and Diverse Synthesis
Apr 11, 2025



Palmprint recognition techniques have advanced significantly in recent years, enabling reliable recognition even when palmprints are captured in uncontrolled or challenging environments. However, this strength also introduces new risks, as publicly available palmprint images can be misused by adversaries for malicious activities. Despite this growing concern, research on methods to obscure or anonymize palmprints remains largely unexplored. Thus, it is essential to develop a palmprint de-identification technique capable of removing identity-revealing features while retaining the image's utility and preserving non-sensitive information. In this paper, we propose a training-free framework that utilizes pre-trained diffusion models to generate diverse, high-quality palmprint images that conceal identity features for de-identification purposes. To ensure greater stability and controllability in the synthesis process, we incorporate a semantic-guided embedding fusion alongside a prior interpolation mechanism. We further propose the de-identification ratio, a novel metric for intuitive de-identification assessment. Extensive experiments across multiple palmprint datasets and recognition methods demonstrate that our method effectively conceals identity-related traits with significant diversity across de-identified samples. The de-identified samples preserve high visual fidelity and maintain excellent usability, achieving a balance between de-identification and retaining non-identity information.