 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAR-Dex: Few-shot Data Augmentation and Adaptive Residual Policy Refinement for Dexterous Manipulation
Mar 11, 2026Achieving human-like dexterous manipulation through the collaboration of multi-fingered hands with robotic arms remains a longstanding challenge in robotics, primarily due to the scarcity of high-quality demonstrations and the complexity of high-dimensional action spaces. To address these challenges, we propose FAR-Dex, a hierarchical framework that integrates few-shot data augmentation with adaptive residual refinement to enable robust and precise arm-hand coordination in dexterous tasks. First, FAR-DexGen leverages the IsaacLab simulator to generate diverse and physically constrained trajectories from a few demonstrations, providing a data foundation for policy training. Second, FAR-DexRes introduces an adaptive residual module that refines policies by combining multi-step trajectory segments with observation features, thereby enhancing accuracy and robustness in manipulation scenarios. Experiments in both simulation and real-world demonstrate that FAR-Dex improves data quality by 13.4% and task success rates by 7% over state-of-the-art methods. It further achieves over 80% success in real-world tasks, enabling fine-grained dexterous manipulation with strong positional generalization.
AG-VAS: Anchor-Guided Zero-Shot Visual Anomaly Segmentation with Large Multimodal Models
Mar 01, 2026Large multimodal models (LMMs) exhibit strong task generalization capabilities, offering new opportunities for zero-shot visual anomaly segmentation (ZSAS). However, existing LMM-based segmentation approaches still face fundamental limitations: anomaly concepts are inherently abstract and context-dependent, lacking stable visual prototypes, and the weak alignment between high-level semantic embeddings and pixel-level spatial features hinders precise anomaly localization. To address these challenges, we present AG-VAS (Anchor-Guided Visual Anomaly Segmentation), a new framework that expands the LMM vocabulary with three learnable semantic anchor tokens-[SEG], [NOR], and [ANO], establishing a unified anchor-guided segmentation paradigm. Specifically, [SEG] serves as an absolute semantic anchor that translates abstract anomaly semantics into explicit, spatially grounded visual entities (e.g., holes or scratches), while [NOR] and [ANO] act as relative anchors that model the contextual contrast between normal and abnormal patterns across categories. To further enhance cross-modal alignment, we introduce a Semantic-Pixel Alignment Module (SPAM) that aligns language-level semantic embeddings with high-resolution visual features, along with an Anchor-Guided Mask Decoder (AGMD) that performs anchor-conditioned mask prediction for precise anomaly localization. In addition, we curate Anomaly-Instruct20K, a large-scale instruction dataset that organizes anomaly knowledge into structured descriptions of appearance, shape, and spatial attributes, facilitating effective learning and integration of the proposed semantic anchors. Extensive experiments on six industrial and medical benchmarks demonstrate that AG-VAS achieves consistent state-of-the-art performance in the zero-shot setting.
MRAD: Zero-Shot Anomaly Detection with Memory-Driven Retrieval
Jan 31, 2026Zero-shot anomaly detection (ZSAD) often leverages pretrained vision or vision-language models, but many existing methods use prompt learning or complex modeling to fit the data distribution, resulting in high training or inference cost and limited cross-domain stability. To address these limitations, we propose Memory-Retrieval Anomaly Detection method (MRAD), a unified framework that replaces parametric fitting with a direct memory retrieval. The train-free base model, MRAD-TF, freezes the CLIP image encoder and constructs a two-level memory bank (image-level and pixel-level) from auxiliary data, where feature-label pairs are explicitly stored as keys and values. During inference, anomaly scores are obtained directly by similarity retrieval over the memory bank. Based on the MRAD-TF, we further propose two lightweight variants as enhancements: (i) MRAD-FT fine-tunes the retrieval metric with two linear layers to enhance the discriminability between normal and anomaly; (ii) MRAD-CLIP injects the normal and anomalous region priors from the MRAD-FT as dynamic biases into CLIP's learnable text prompts, strengthening generalization to unseen categories. Across 16 industrial and medical datasets, the MRAD framework consistently demonstrates superior performance in anomaly classification and segmentation, under both train-free and training-based settings. Our work shows that fully leveraging the empirical distribution of raw data, rather than relying only on model fitting, can achieve stronger anomaly detection performance. The code will be publicly released at https://github.com/CROVO1026/MRAD.
Survey of Vision-Language-Action Models for Embodied Manipulation
Aug 21, 2025Embodied intelligence systems, which enhance agent capabilities through continuous environment interactions, have garnered significant attention from both academia and industry. Vision-Language-Action models, inspired by advancements in large foundation models, serve as universal robotic control frameworks that substantially improve agent-environment interaction capabilities in embodied intelligence systems. This expansion has broadened application scenarios for embodied AI robots. This survey comprehensively reviews VLA models for embodied manipulation. Firstly, it chronicles the developmental trajectory of VLA architectures. Subsequently, we conduct a detailed analysis of current research across 5 critical dimensions: VLA model structures, training datasets, pre-training methods, post-training methods, and model evaluation. Finally, we synthesize key challenges in VLA development and real-world deployment, while outlining promising future research directions.
DTRT: Enhancing Human Intent Estimation and Role Allocation for Physical Human-Robot Collaboration
May 26, 2025In physical Human-Robot Collaboration (pHRC), accurate human intent estimation and rational human-robot role allocation are crucial for safe and efficient assistance. Existing methods that rely on short-term motion data for intention estimation lack multi-step prediction capabilities, hindering their ability to sense intent changes and adjust human-robot assignments autonomously, resulting in potential discrepancies. To address these issues, we propose a Dual Transformer-based Robot Trajectron (DTRT) featuring a hierarchical architecture, which harnesses human-guided motion and force data to rapidly capture human intent changes, enabling accurate trajectory predictions and dynamic robot behavior adjustments for effective collaboration. Specifically, human intent estimation in DTRT uses two Transformer-based Conditional Variational Autoencoders (CVAEs), incorporating robot motion data in obstacle-free case with human-guided trajectory and force for obstacle avoidance. Additionally, Differential Cooperative Game Theory (DCGT) is employed to synthesize predictions based on human-applied forces, ensuring robot behavior align with human intention. Compared to state-of-the-art (SOTA) methods, DTRT incorporates human dynamics into long-term prediction, providing an accurate understanding of intention and enabling rational role allocation, achieving robot autonomy and maneuverability. Experiments demonstrate DTRT's accurate intent estimation and superior collaboration performance.
Center-aware Residual Anomaly Synthesis for Multi-class Industrial Anomaly Detection
May 23, 2025Anomaly detection plays a vital role in the inspection of industrial images. Most existing methods require separate models for each category, resulting in multiplied deployment costs. This highlights the challenge of developing a unified model for multi-class anomaly detection. However, the significant increase in inter-class interference leads to severe missed detections. Furthermore, the intra-class overlap between normal and abnormal samples, particularly in synthesis-based methods, cannot be ignored and may lead to over-detection. To tackle these issues, we propose a novel Center-aware Residual Anomaly Synthesis (CRAS) method for multi-class anomaly detection. CRAS leverages center-aware residual learning to couple samples from different categories into a unified center, mitigating the effects of inter-class interference. To further reduce intra-class overlap, CRAS introduces distance-guided anomaly synthesis that adaptively adjusts noise variance based on normal data distribution. Experimental results on diverse datasets and real-world industrial applications demonstrate the superior detection accuracy and competitive inference speed of CRAS. The source code and the newly constructed dataset are publicly available at https://github.com/cqylunlun/CRAS.
Teacher Motion Priors: Enhancing Robot Locomotion over Challenging Terrain
Apr 14, 2025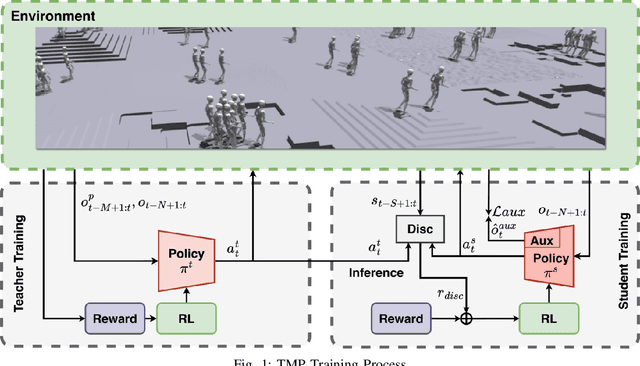
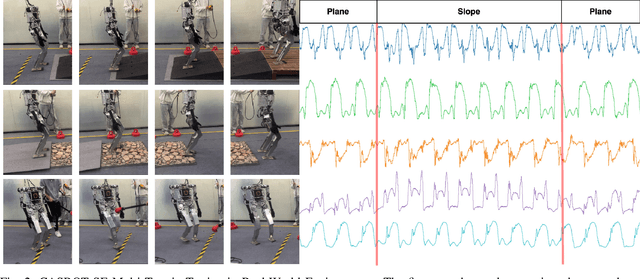
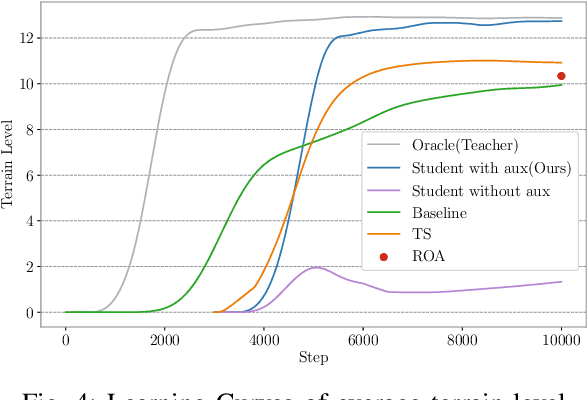
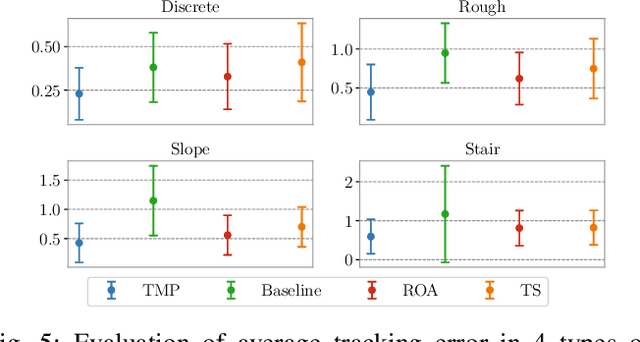
Achieving robust locomotion on complex terrains remains a challenge due to high dimensional control and environmental uncertainties. This paper introduces a teacher prior framework based on the teacher student paradigm, integrating imitation and auxiliary task learning to improve learning efficiency and generalization. Unlike traditional paradigms that strongly rely on encoder-based state embeddings, our framework decouples the network design, simplifying the policy network and deployment. A high performance teacher policy is first trained using privileged information to acquire generalizable motion skills. The teacher's motion distribution is transferred to the student policy, which relies only on noisy proprioceptive data, via a generative adversarial mechanism to mitigate performance degradation caused by distributional shifts. Additionally, auxiliary task learning enhances the student policy's feature representation, speeding up convergence and improving adaptability to varying terrains. The framework is validated on a humanoid robot, showing a great improvement in locomotion stability on dynamic terrains and significant reductions in development costs. This work provides a practical solution for deploying robust locomotion strategies in humanoid robots.
Bayesian Prompt Flow Learning for Zero-Shot Anomaly Detection
Mar 13, 2025Recently, vision-language models (e.g. CLIP) have demonstrated remarkable performance in zero-shot anomaly detection (ZSAD). By leveraging auxiliary data during training, these models can directly perform cross-category anomaly detection on target datasets, such as detecting defects on industrial product surfaces or identifying tumors in organ tissues. Existing approaches typically construct text prompts through either manual design or the optimization of learnable prompt vectors. However, these methods face several challenges: 1) handcrafted prompts require extensive expert knowledge and trial-and-error; 2) single-form learnable prompts struggle to capture complex anomaly semantics; and 3) an unconstrained prompt space limit generalization to unseen categories. To address these issues, we propose Bayesian Prompt Flow Learning (Bayes-PFL), which models the prompt space as a learnable probability distribution from a Bayesian perspective. Specifically, a prompt flow module is designed to learn both image-specific and image-agnostic distributions, which are jointly utilized to regularize the text prompt space and enhance the model's generalization on unseen categories. These learned distributions are then sampled to generate diverse text prompts, effectively covering the prompt space. Additionally, a residual cross-attention (RCA) module is introduced to better align dynamic text embeddings with fine-grained image features. Extensive experiments on 15 industrial and medical datasets demonstrate our method's superior performance.
Progressive Boundary Guided Anomaly Synthesis for Industrial Anomaly Detection
Dec 23, 2024



Unsupervised anomaly detection methods can identify surface defects in industrial images by leveraging only normal samples for training. Due to the risk of overfitting when learning from a single class, anomaly synthesis strategies are introduced to enhance detection capability by generating artificial anomalies. However, existing strategies heavily rely on anomalous textures from auxiliary datasets. Moreover, their limitations in the coverage and directionality of anomaly synthesis may result in a failure to capture useful information and lead to significant redundancy. To address these issues, we propose a novel Progressive Boundary-guided Anomaly Synthesis (PBAS) strategy, which can directionally synthesize crucial feature-level anomalies without auxiliary textures. It consists of three core components: Approximate Boundary Learning (ABL), Anomaly Feature Synthesis (AFS), and Refined Boundary Optimization (RBO). To make the distribution of normal samples more compact, ABL first learns an approximate decision boundary by center constraint, which improves the center initialization through feature alignment. AFS then directionally synthesizes anomalies with more flexible scales guided by the hypersphere distribution of normal features. Since the boundary is so loose that it may contain real anomalies, RBO refines the decision boundary through the binary classification of artificial anomalies and normal features. Experimental results show that our method achieves state-of-the-art performance and the fastest detection speed on three widely used industrial datasets, including MVTec AD, VisA, and MPDD. The code will be available at: https://github.com/cqylunlun/PBAS.
Few-shot Defect Image Generation based on Consistency Modeling
Aug 01, 2024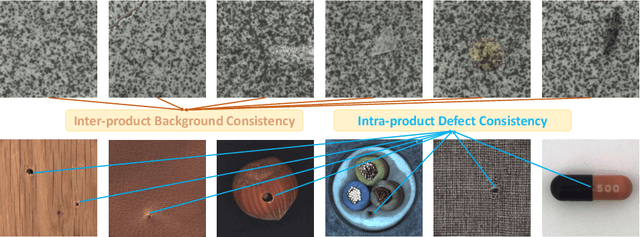
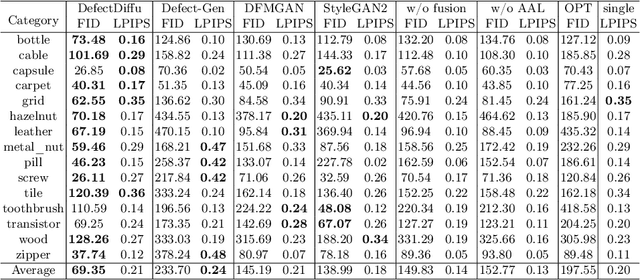

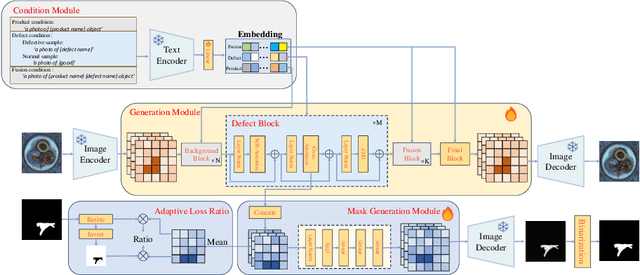
Image generation can solve insufficient labeled data issues in defect detection. Most defect generation methods are only trained on a single product without considering the consistencies among multiple products, leading to poor quality and diversity of generated results. To address these issues, we propose DefectDiffu, a novel text-guided diffusion method to model both intra-product background consistency and inter-product defect consistency across multiple products and modulate the consistency perturbation directions to control product type and defect strength, achieving diversified defect image generation. Firstly, we leverage a text encoder to separately provide consistency prompts for background, defect, and fusion parts of the disentangled integrated architecture, thereby disentangling defects and normal backgrounds. Secondly, we propose the double-free strategy to generate defect images through two-stage perturbation of consistency direction, thereby controlling product type and defect strength by adjusting the perturbation scale. Besides, DefectDiffu can generate defect mask annotations utilizing cross-attention maps from the defect part. Finally, to improve the generation quality of small defects and masks, we propose the adaptive attention-enhance loss to increase the attention to defects. Experimental results demonstrate that DefectDiffu surpasses state-of-the-art methods in terms of generation quality and diversity, thus effectively improving downstream defection performance. Moreover, defect perturbation directions can be transferred among various products to achieve zero-shot defect generation, which is highly beneficial for addressing insufficient data issues. The code are available at https://github.com/FFDD-diffusion/DefectDiffu.