 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Defect Image Generation based on Consistency Modeling
Paper and Code
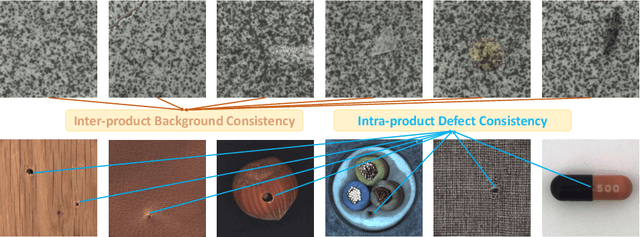
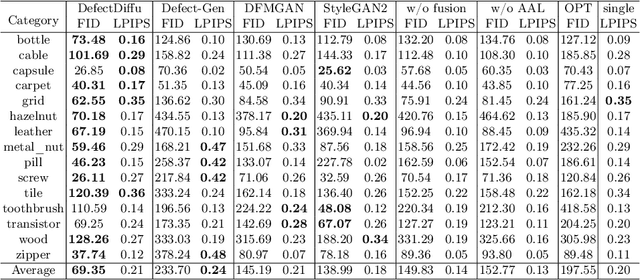

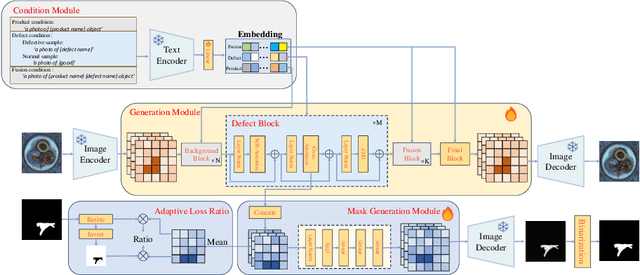
Image generation can solve insufficient labeled data issues in defect detection. Most defect generation methods are only trained on a single product without considering the consistencies among multiple products, leading to poor quality and diversity of generated results. To address these issues, we propose DefectDiffu, a novel text-guided diffusion method to model both intra-product background consistency and inter-product defect consistency across multiple products and modulate the consistency perturbation directions to control product type and defect strength, achieving diversified defect image generation. Firstly, we leverage a text encoder to separately provide consistency prompts for background, defect, and fusion parts of the disentangled integrated architecture, thereby disentangling defects and normal backgrounds. Secondly, we propose the double-free strategy to generate defect images through two-stage perturbation of consistency direction, thereby controlling product type and defect strength by adjusting the perturbation scale. Besides, DefectDiffu can generate defect mask annotations utilizing cross-attention maps from the defect part. Finally, to improve the generation quality of small defects and masks, we propose the adaptive attention-enhance loss to increase the attention to defects. Experimental results demonstrate that DefectDiffu surpasses state-of-the-art methods in terms of generation quality and diversity, thus effectively improving downstream defection performance. Moreover, defect perturbation directions can be transferred among various products to achieve zero-shot defect generation, which is highly beneficial for addressing insufficient data issues. The code are available at https://github.com/FFDD-diffusion/DefectDiffu.