 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Reinforcement Learning with Incomplete System Dynamics
Oct 24, 2024Model-free reinforcement learning (RL) is inherently a reactive method, operating under the assumption that it starts with no prior knowledge of the system and entirely depends on trial-and-error for learning. This approach faces several challenges, such as poor sample efficiency, generalization, and the need for well-designed reward functions to guide learning effectively. On the other hand, controllers based on complete system dynamics do not require data. This paper addresses the intermediate situation where there is not enough model information for complete controller design, but there is enough to suggest that a model-free approach is not the best approach either. By carefully decoupling known and unknown information about the system dynamics, we obtain an embedded controller guided by our partial model and thus improve the learning efficiency of an RL-enhanced approach. A modular design allows us to deploy mainstream RL algorithms to refine the policy. Simulation results show that our method significantly improves sample efficiency compared with standard RL methods on continuous control tasks, and also offers enhanced performance over traditional control approaches. Experiments on a real ground vehicle also validate the performance of our method, including generalization and robustness.
Produce Once, Utilize Twice for Anomaly Detection
Dec 20, 2023



Visual anomaly detection aims at classifying and locating the regions that deviate from the normal appearance. Embedding-based methods and reconstruction-based methods are two main approaches for this task. However, they are either not efficient or not precise enough for the industrial detection. To deal with this problem, we derive POUTA (Produce Once Utilize Twice for Anomaly detection), which improves both the accuracy and efficiency by reusing the discriminant information potential in the reconstructive network. We observe that the encoder and decoder representations of the reconstructive network are able to stand for the features of the original and reconstructed image respectively. And the discrepancies between the symmetric reconstructive representations provides roughly accurate anomaly information. To refine this information, a coarse-to-fine process is proposed in POUTA, which calibrates the semantics of each discriminative layer by the high-level representations and supervision loss. Equipped with the above modules, POUTA is endowed with the ability to provide a more precise anomaly location than the prior arts. Besides, the representation reusage also enables to exclude the feature extraction process in the discriminative network, which reduces the parameters and improves the efficiency. Extensive experiments show that, POUTA is superior or comparable to the prior methods with even less cost. Furthermore, POUTA also achieves better performance than the state-of-the-art few-shot anomaly detection methods without any special design, showing that POUTA has strong ability to learn representations inherent in the training data.
Stabilizing reinforcement learning control: A modular framework for optimizing over all stable behavior
Oct 21, 2023



We propose a framework for the design of feedback controllers that combines the optimization-driven and model-free advantages of deep reinforcement learning with the stability guarantees provided by using the Youla-Kucera parameterization to define the search domain. Recent advances in behavioral systems allow us to construct a data-driven internal model; this enables an alternative realization of the Youla-Kucera parameterization based entirely on input-output exploration data. Perhaps of independent interest, we formulate and analyze the stability of such data-driven models in the presence of noise. The Youla-Kucera approach requires a stable "parameter" for controller design. For the training of reinforcement learning agents, the set of all stable linear operators is given explicitly through a matrix factorization approach. Moreover, a nonlinear extension is given using a neural network to express a parameterized set of stable operators, which enables seamless integration with standard deep learning libraries. Finally, we show how these ideas can also be applied to tune fixed-structure controllers.
Reinforcement Learning with Partial Parametric Model Knowledge
Apr 26, 2023We adapt reinforcement learning (RL) methods for continuous control to bridge the gap between complete ignorance and perfect knowledge of the environment. Our method, Partial Knowledge Least Squares Policy Iteration (PLSPI), takes inspiration from both model-free RL and model-based control. It uses incomplete information from a partial model and retains RL's data-driven adaption towards optimal performance. The linear quadratic regulator provides a case study; numerical experiments demonstrate the effectiveness and resulting benefits of the proposed method.
A modular framework for stabilizing deep reinforcement learning control
Apr 07, 2023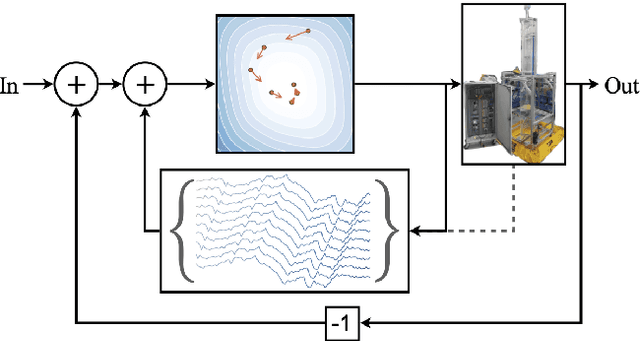
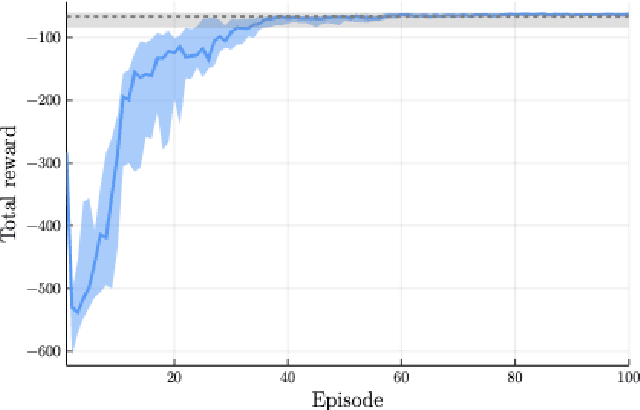
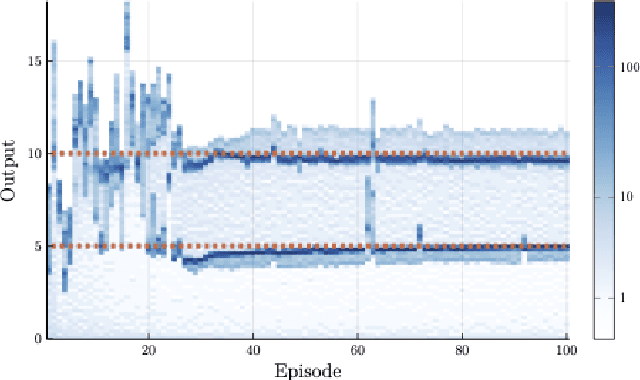
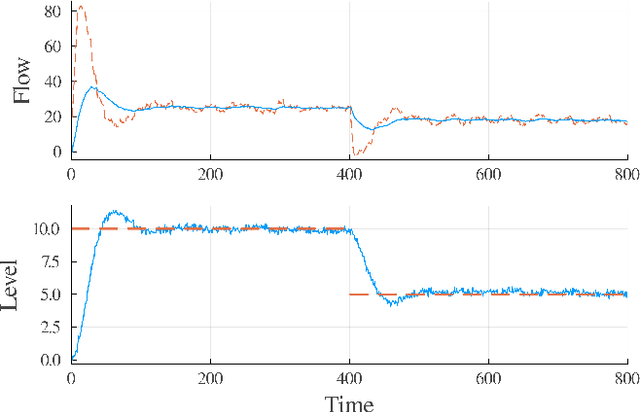
We propose a framework for the design of feedback controllers that combines the optimization-driven and model-free advantages of deep reinforcement learning with the stability guarantees provided by using the Youla-Kucera parameterization to define the search domain. Recent advances in behavioral systems allow us to construct a data-driven internal model; this enables an alternative realization of the Youla-Kucera parameterization based entirely on input-output exploration data. Using a neural network to express a parameterized set of nonlinear stable operators enables seamless integration with standard deep learning libraries. We demonstrate the approach on a realistic simulation of a two-tank system.