 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Reinforcement Learning with Incomplete System Dynamics
Oct 24, 2024Model-free reinforcement learning (RL) is inherently a reactive method, operating under the assumption that it starts with no prior knowledge of the system and entirely depends on trial-and-error for learning. This approach faces several challenges, such as poor sample efficiency, generalization, and the need for well-designed reward functions to guide learning effectively. On the other hand, controllers based on complete system dynamics do not require data. This paper addresses the intermediate situation where there is not enough model information for complete controller design, but there is enough to suggest that a model-free approach is not the best approach either. By carefully decoupling known and unknown information about the system dynamics, we obtain an embedded controller guided by our partial model and thus improve the learning efficiency of an RL-enhanced approach. A modular design allows us to deploy mainstream RL algorithms to refine the policy. Simulation results show that our method significantly improves sample efficiency compared with standard RL methods on continuous control tasks, and also offers enhanced performance over traditional control approaches. Experiments on a real ground vehicle also validate the performance of our method, including generalization and robustness.
Machine learning for industrial sensing and control: A survey and practical perspective
Jan 24, 2024With the rise of deep learning, there has been renewed interest within the process industries to utilize data on large-scale nonlinear sensing and control problems. We identify key statistical and machine learning techniques that have seen practical success in the process industries. To do so, we start with hybrid modeling to provide a methodological framework underlying core application areas: soft sensing, process optimization, and control. Soft sensing contains a wealth of industrial applications of statistical and machine learning methods. We quantitatively identify research trends, allowing insight into the most successful techniques in practice. We consider two distinct flavors for data-driven optimization and control: hybrid modeling in conjunction with mathematical programming techniques and reinforcement learning. Throughout these application areas, we discuss their respective industrial requirements and challenges. A common challenge is the interpretability and efficiency of purely data-driven methods. This suggests a need to carefully balance deep learning techniques with domain knowledge. As a result, we highlight ways prior knowledge may be integrated into industrial machine learning applications. The treatment of methods, problems, and applications presented here is poised to inform and inspire practitioners and researchers to develop impactful data-driven sensing, optimization, and control solutions in the process industries.
* 48 pages
Stabilizing reinforcement learning control: A modular framework for optimizing over all stable behavior
Oct 21, 2023



We propose a framework for the design of feedback controllers that combines the optimization-driven and model-free advantages of deep reinforcement learning with the stability guarantees provided by using the Youla-Kucera parameterization to define the search domain. Recent advances in behavioral systems allow us to construct a data-driven internal model; this enables an alternative realization of the Youla-Kucera parameterization based entirely on input-output exploration data. Perhaps of independent interest, we formulate and analyze the stability of such data-driven models in the presence of noise. The Youla-Kucera approach requires a stable "parameter" for controller design. For the training of reinforcement learning agents, the set of all stable linear operators is given explicitly through a matrix factorization approach. Moreover, a nonlinear extension is given using a neural network to express a parameterized set of stable operators, which enables seamless integration with standard deep learning libraries. Finally, we show how these ideas can also be applied to tune fixed-structure controllers.
Reinforcement Learning with Partial Parametric Model Knowledge
Apr 26, 2023We adapt reinforcement learning (RL) methods for continuous control to bridge the gap between complete ignorance and perfect knowledge of the environment. Our method, Partial Knowledge Least Squares Policy Iteration (PLSPI), takes inspiration from both model-free RL and model-based control. It uses incomplete information from a partial model and retains RL's data-driven adaption towards optimal performance. The linear quadratic regulator provides a case study; numerical experiments demonstrate the effectiveness and resulting benefits of the proposed method.
A modular framework for stabilizing deep reinforcement learning control
Apr 07, 2023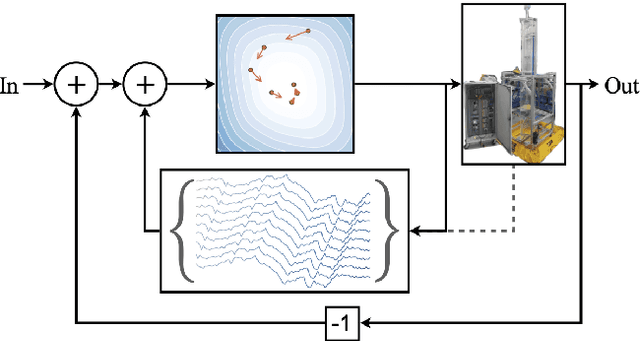
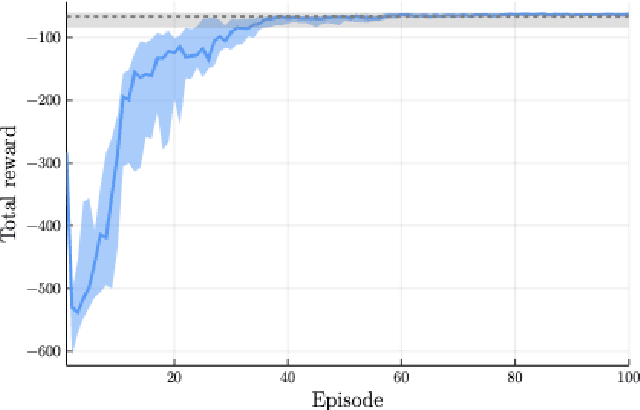
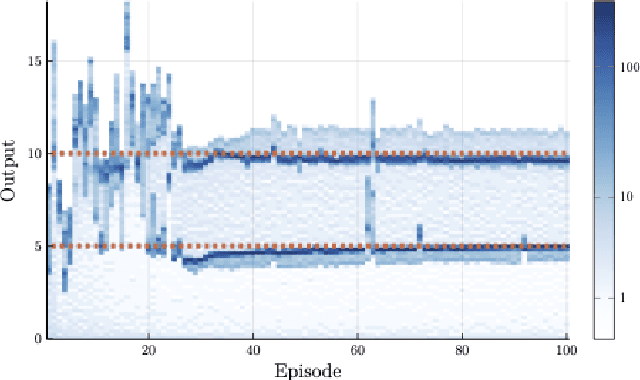
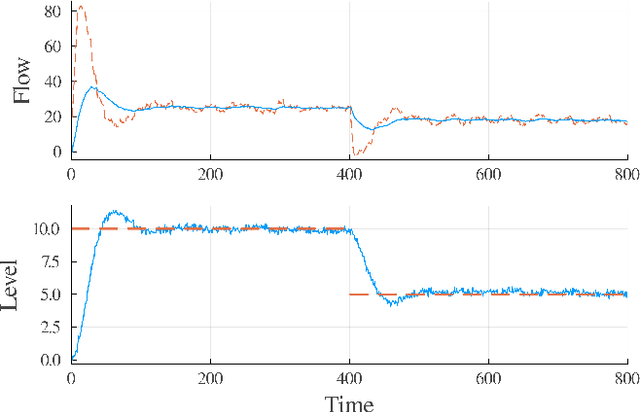
We propose a framework for the design of feedback controllers that combines the optimization-driven and model-free advantages of deep reinforcement learning with the stability guarantees provided by using the Youla-Kucera parameterization to define the search domain. Recent advances in behavioral systems allow us to construct a data-driven internal model; this enables an alternative realization of the Youla-Kucera parameterization based entirely on input-output exploration data. Using a neural network to express a parameterized set of nonlinear stable operators enables seamless integration with standard deep learning libraries. We demonstrate the approach on a realistic simulation of a two-tank system.
Automated deep reinforcement learning for real-time scheduling strategy of multi-energy system integrated with post-carbon and direct-air carbon captured system
Jan 18, 2023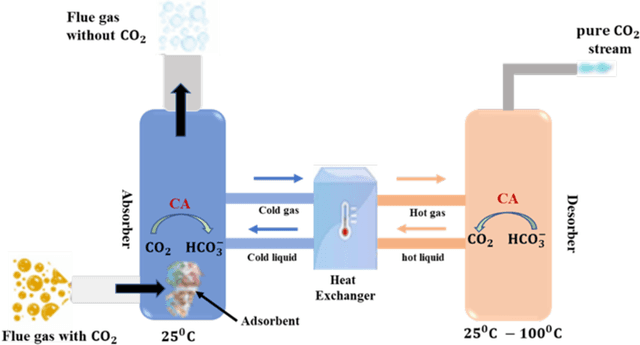
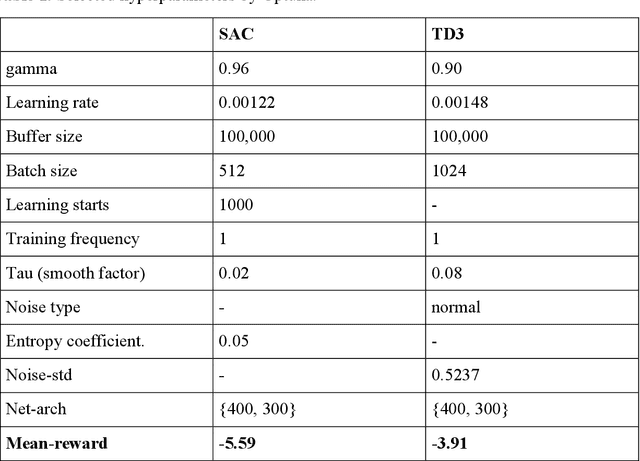
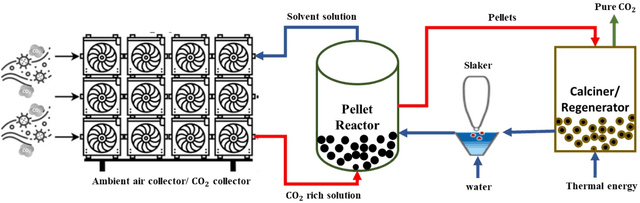
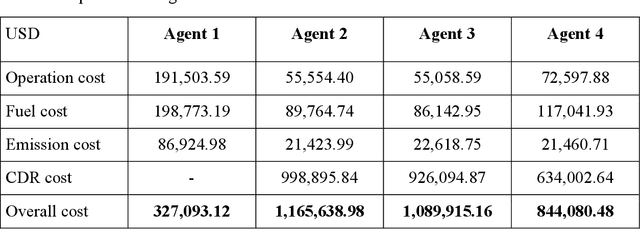
The carbon-capturing process with the aid of CO2 removal technology (CDRT) has been recognised as an alternative and a prominent approach to deep decarbonisation. However, the main hindrance is the enormous energy demand and the economic implication of CDRT if not effectively managed. Hence, a novel deep reinforcement learning agent (DRL), integrated with an automated hyperparameter selection feature, is proposed in this study for the real-time scheduling of a multi-energy system coupled with CDRT. Post-carbon capture systems (PCCS) and direct-air capture systems (DACS) are considered CDRT. Various possible configurations are evaluated using real-time multi-energy data of a district in Arizona and CDRT parameters from manufacturers' catalogues and pilot project documentation. The simulation results validate that an optimised soft-actor critic (SAC) algorithm outperformed the TD3 algorithm due to its maximum entropy feature. We then trained four (4) SAC agents, equivalent to the number of considered case studies, using optimised hyperparameter values and deployed them in real time for evaluation. The results show that the proposed DRL agent can meet the prosumers' multi-energy demand and schedule the CDRT energy demand economically without specified constraints violation. Also, the proposed DRL agent outperformed rule-based scheduling by 23.65%. However, the configuration with PCCS and solid-sorbent DACS is considered the most suitable configuration with a high CO2 captured-released ratio of 38.54, low CO2 released indicator value of 2.53, and a 36.5% reduction in CDR cost due to waste heat utilisation and high absorption capacity of the selected sorbent. However, the adoption of CDRT is not economically viable at the current carbon price. Finally, we showed that CDRT would be attractive at a carbon price of 400-450USD/ton with the provision of tax incentives by the policymakers.
* 39 pages; postprint
Data Quality Over Quantity: Pitfalls and Guidelines for Process Analytics
Nov 11, 2022



A significant portion of the effort involved in advanced process control, process analytics, and machine learning involves acquiring and preparing data. The published literature often emphasizes increasingly complex modeling techniques with incremental performance improvements. However, when industrial case studies are published they often lack important details on data acquisition and preparation. Although data pre-processing is often unfairly maligned as trivial and technically uninteresting, in practice it has an out-sized influence on the success of real-world artificial intelligence applications. This work describes best practices for acquiring and preparing operating data to pursue data-driven modelling and control opportunities in industrial processes. We present practical considerations for pre-processing industrial time series data to inform the efficient development of reliable soft sensors that provide valuable process insights.
Modern Machine Learning Tools for Monitoring and Control of Industrial Processes: A Survey
Sep 22, 2022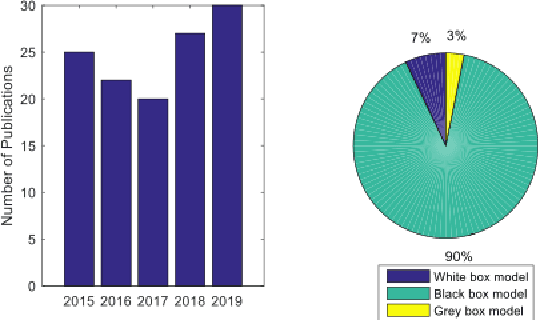
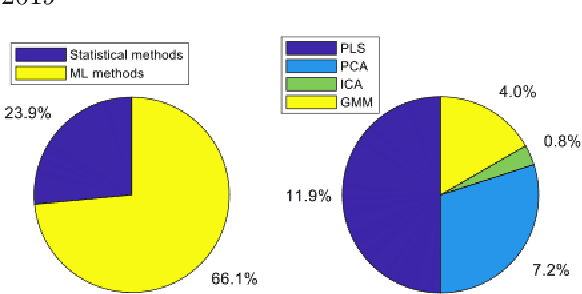
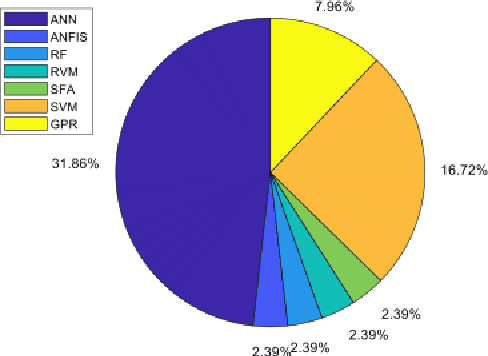
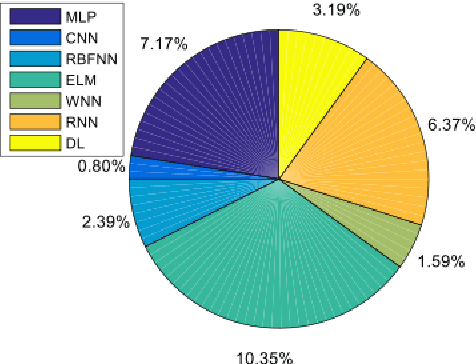
Over the last ten years, we have seen a significant increase in industrial data, tremendous improvement in computational power, and major theoretical advances in machine learning. This opens up an opportunity to use modern machine learning tools on large-scale nonlinear monitoring and control problems. This article provides a survey of recent results with applications in the process industry.
Meta-Reinforcement Learning for Adaptive Control of Second Order Systems
Sep 19, 2022
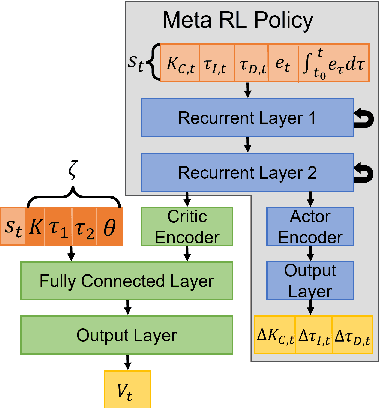
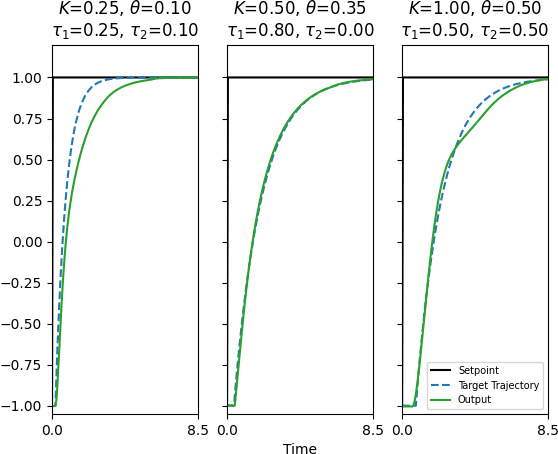
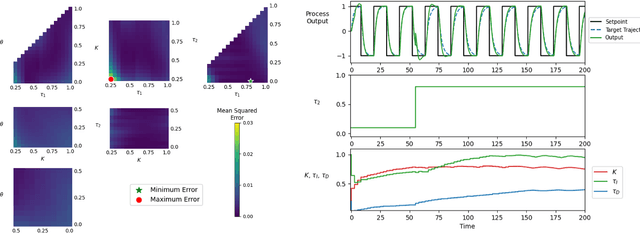
Meta-learning is a branch of machine learning which aims to synthesize data from a distribution of related tasks to efficiently solve new ones. In process control, many systems have similar and well-understood dynamics, which suggests it is feasible to create a generalizable controller through meta-learning. In this work, we formulate a meta reinforcement learning (meta-RL) control strategy that takes advantage of known, offline information for training, such as a model structure. The meta-RL agent is trained over a distribution of model parameters, rather than a single model, enabling the agent to automatically adapt to changes in the process dynamics while maintaining performance. A key design element is the ability to leverage model-based information offline during training, while maintaining a model-free policy structure for interacting with new environments. Our previous work has demonstrated how this approach can be applied to the industrially-relevant problem of tuning proportional-integral controllers to control first order processes. In this work, we briefly reintroduce our methodology and demonstrate how it can be extended to proportional-integral-derivative controllers and second order systems.
Meta Reinforcement Learning for Adaptive Control: An Offline Approach
Mar 17, 2022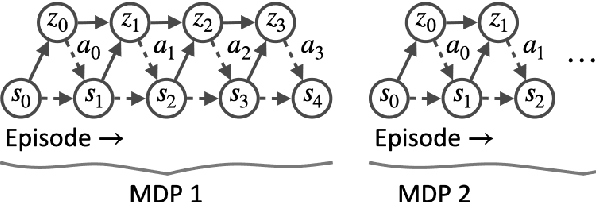
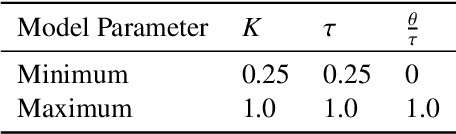
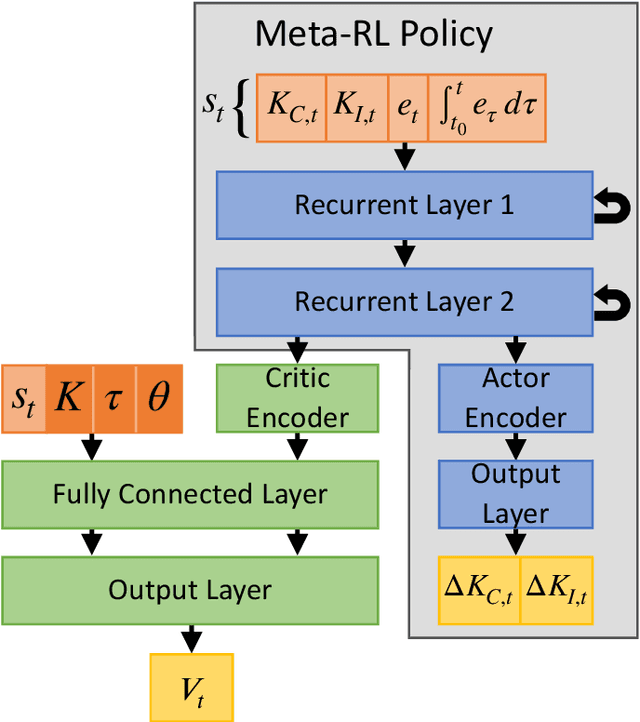
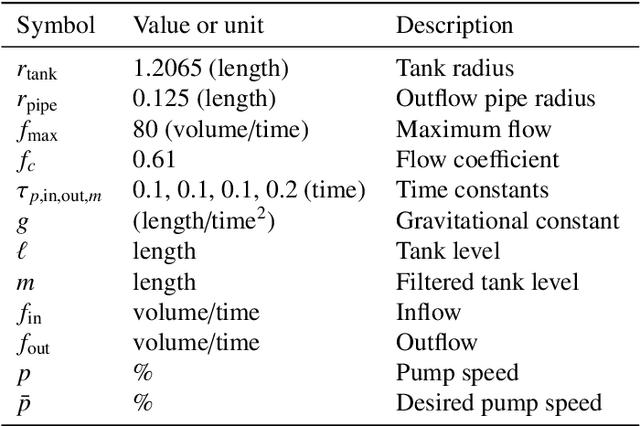
Meta-learning is a branch of machine learning which trains neural network models to synthesize a wide variety of data in order to rapidly solve new problems. In process control, many systems have similar and well-understood dynamics, which suggests it is feasible to create a generalizable controller through meta-learning. In this work, we formulate a meta reinforcement learning (meta-RL) control strategy that takes advantage of known, offline information for training, such as the system gain or time constant, yet efficiently controls novel systems in a completely model-free fashion. Our meta-RL agent has a recurrent structure that accumulates "context" for its current dynamics through a hidden state variable. This end-to-end architecture enables the agent to automatically adapt to changes in the process dynamics. Moreover, the same agent can be deployed on systems with previously unseen nonlinearities and timescales. In tests reported here, the meta-RL agent was trained entirely offline, yet produced excellent results in novel settings. A key design element is the ability to leverage model-based information offline during training, while maintaining a model-free policy structure for interacting with novel environments. To illustrate the approach, we take the actions proposed by the meta-RL agent to be changes to gains of a proportional-integral controller, resulting in a generalized, adaptive, closed-loop tuning strategy. Meta-learning is a promising approach for constructing sample-efficient intelligent controllers.