 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated deep reinforcement learning for real-time scheduling strategy of multi-energy system integrated with post-carbon and direct-air carbon captured system
Jan 18, 2023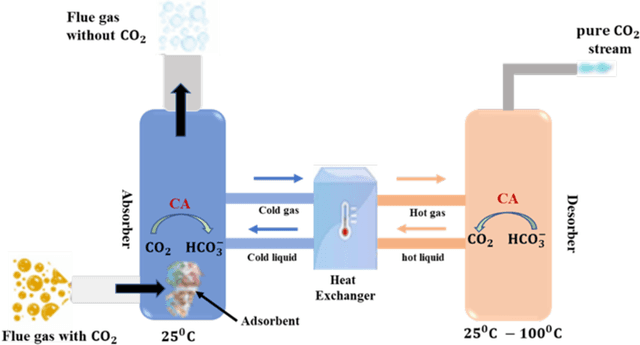
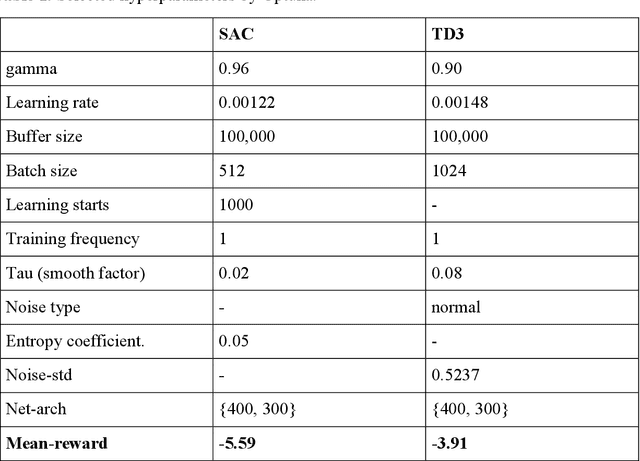
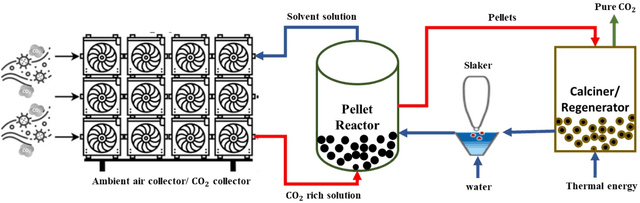
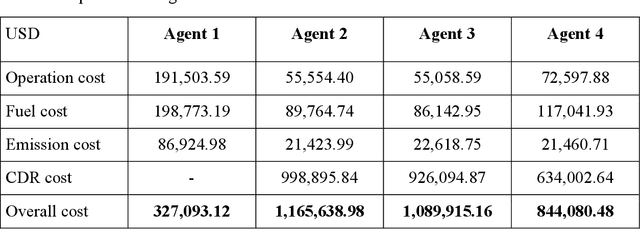
The carbon-capturing process with the aid of CO2 removal technology (CDRT) has been recognised as an alternative and a prominent approach to deep decarbonisation. However, the main hindrance is the enormous energy demand and the economic implication of CDRT if not effectively managed. Hence, a novel deep reinforcement learning agent (DRL), integrated with an automated hyperparameter selection feature, is proposed in this study for the real-time scheduling of a multi-energy system coupled with CDRT. Post-carbon capture systems (PCCS) and direct-air capture systems (DACS) are considered CDRT. Various possible configurations are evaluated using real-time multi-energy data of a district in Arizona and CDRT parameters from manufacturers' catalogues and pilot project documentation. The simulation results validate that an optimised soft-actor critic (SAC) algorithm outperformed the TD3 algorithm due to its maximum entropy feature. We then trained four (4) SAC agents, equivalent to the number of considered case studies, using optimised hyperparameter values and deployed them in real time for evaluation. The results show that the proposed DRL agent can meet the prosumers' multi-energy demand and schedule the CDRT energy demand economically without specified constraints violation. Also, the proposed DRL agent outperformed rule-based scheduling by 23.65%. However, the configuration with PCCS and solid-sorbent DACS is considered the most suitable configuration with a high CO2 captured-released ratio of 38.54, low CO2 released indicator value of 2.53, and a 36.5% reduction in CDR cost due to waste heat utilisation and high absorption capacity of the selected sorbent. However, the adoption of CDRT is not economically viable at the current carbon price. Finally, we showed that CDRT would be attractive at a carbon price of 400-450USD/ton with the provision of tax incentives by the policymakers.
* 39 pages; postprint
Optimal Estimator Design and Properties Analysis for Interconnected Systems with Asymmetric Information Structure
May 27, 2021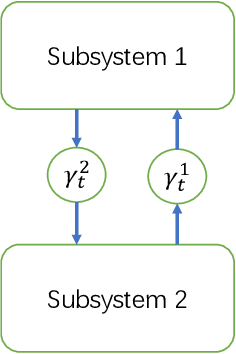
This paper studies the optimal state estimation problem for interconnected systems. Each subsystem can obtain its own measurement in real time, while, the measurements transmitted between the subsystems suffer from random delay. The optimal estimator is analytically designed for minimizing the conditional error covariance. Due to the random delay, the error covariance of the estimation is random. The boundedness of the expected error covariance (EEC) is analyzed. In particular, a new condition that is easy to verify is established for the boundedness of EEC. Further, the properties about EEC with respect to the delay probability is studied. We found that there exists a critical probability such that the EEC is bounded if the delay probability is below the critical probability. Also, a lower and upper bound of the critical probability is effectively computed. Finally, the proposed results are applied to a power system, and the effectiveness of the designed methods is illustrated by simulations.
Finite-Sample Analysis of Decentralized Temporal-Difference Learning with Linear Function Approximation
Nov 03, 2019
Motivated by the emerging use of multi-agent reinforcement learning (MARL) in engineering applications such as networked robotics, swarming drones, and sensor networks, we investigate the policy evaluation problem in a fully decentralized setting, using temporal-difference (TD) learning with linear function approximation to handle large state spaces in practice. The goal of a group of agents is to collaboratively learn the value function of a given policy from locally private rewards observed in a shared environment, through exchanging local estimates with neighbors. Despite their simplicity and widespread use, our theoretical understanding of such decentralized TD learning algorithms remains limited. Existing results were obtained based on i.i.d. data samples, or by imposing an `additional' projection step to control the `gradient' bias incurred by the Markovian observations. In this paper, we provide a finite-sample analysis of the fully decentralized TD(0) learning under both i.i.d. as well as Markovian samples, and prove that all local estimates converge linearly to a small neighborhood of the optimum. The resultant error bounds are the first of its type---in the sense that they hold under the most practical assumptions ---which is made possible by means of a novel multi-step Lyapunov analysis.
Communication-Efficient Distributed Learning via Lazily Aggregated Quantized Gradients
Sep 17, 2019
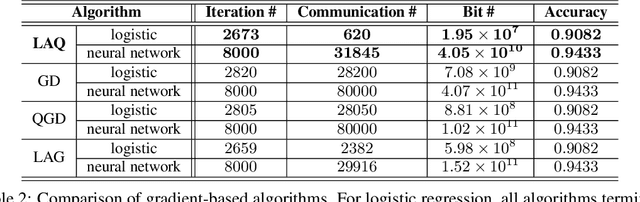

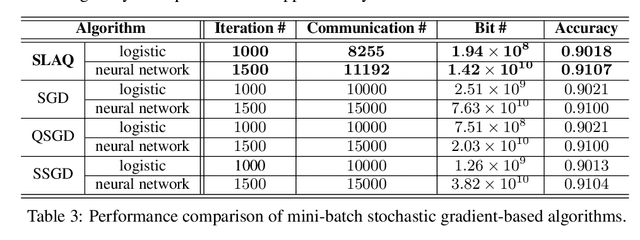
The present paper develops a novel aggregated gradient approach for distributed machine learning that adaptively compresses the gradient communication. The key idea is to first quantize the computed gradients, and then skip less informative quantized gradient communications by reusing outdated gradients. Quantizing and skipping result in `lazy' worker-server communications, which justifies the term Lazily Aggregated Quantized gradient that is henceforth abbreviated as LAQ. Our LAQ can provably attain the same linear convergence rate as the gradient descent in the strongly convex case, while effecting major savings in the communication overhead both in transmitted bits as well as in communication rounds. Empirically, experiments with real data corroborate a significant communication reduction compared to existing gradient- and stochastic gradient-based algorithms.