 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderwater target 6D State Estimation via UUV Attitude Enhance Observability
Jun 16, 2025Accurate relative state observation of Unmanned Underwater Vehicles (UUVs) for tracking uncooperative targets remains a significant challenge due to the absence of GPS, complex underwater dynamics, and sensor limitations. Existing localization approaches rely on either global positioning infrastructure or multi-UUV collaboration, both of which are impractical for a single UUV operating in large or unknown environments. To address this, we propose a novel persistent relative 6D state estimation framework that enables a single UUV to estimate its relative motion to a non-cooperative target using only successive noisy range measurements from two monostatic sonar sensors. Our key contribution is an observability-enhanced attitude control strategy, which optimally adjusts the UUV's orientation to improve the observability of relative state estimation using a Kalman filter, effectively mitigating the impact of sensor noise and drift accumulation. Additionally, we introduce a rigorously proven Lyapunov-based tracking control strategy that guarantees long-term stability by ensuring that the UUV maintains an optimal measurement range, preventing localization errors from diverging over time. Through theoretical analysis and simulations, we demonstrate that our method significantly improves 6D relative state estimation accuracy and robustness compared to conventional approaches. This work provides a scalable, infrastructure-free solution for UUVs tracking uncooperative targets underwater.
Autonomous 3D Moving Target Encirclement and Interception with Range measurement
Jun 16, 2025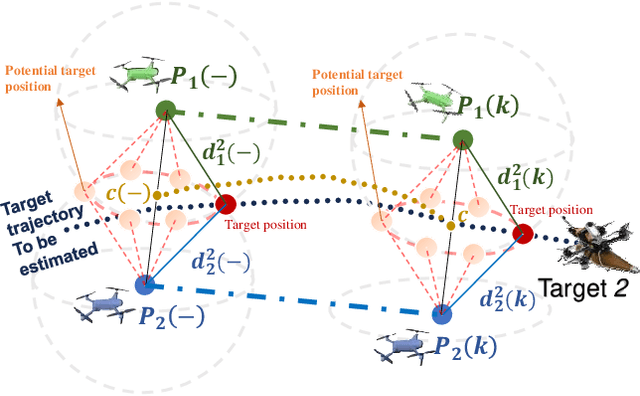
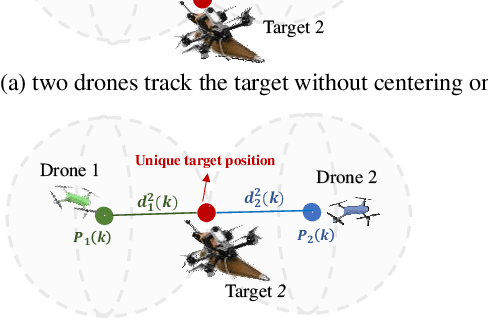
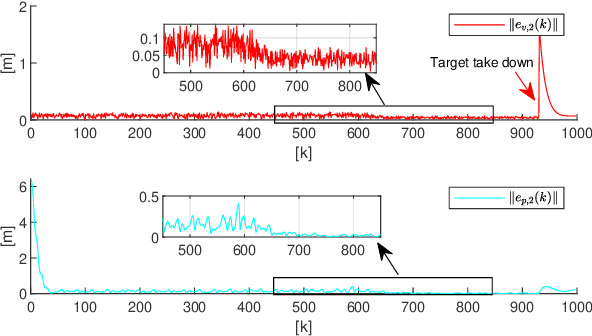
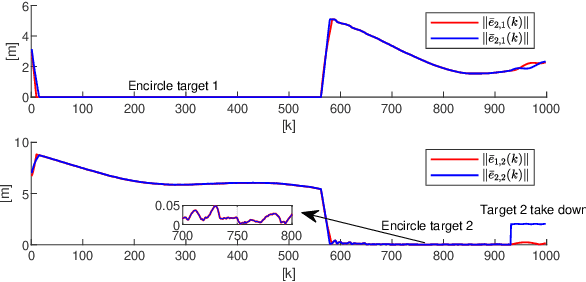
Commercial UAVs are an emerging security threat as they are capable of carrying hazardous payloads or disrupting air traffic. To counter UAVs, we introduce an autonomous 3D target encirclement and interception strategy. Unlike traditional ground-guided systems, this strategy employs autonomous drones to track and engage non-cooperative hostile UAVs, which is effective in non-line-of-sight conditions, GPS denial, and radar jamming, where conventional detection and neutralization from ground guidance fail. Using two noisy real-time distances measured by drones, guardian drones estimate the relative position from their own to the target using observation and velocity compensation methods, based on anti-synchronization (AS) and an X$-$Y circular motion combined with vertical jitter. An encirclement control mechanism is proposed to enable UAVs to adaptively transition from encircling and protecting a target to encircling and monitoring a hostile target. Upon breaching a warning threshold, the UAVs may even employ a suicide attack to neutralize the hostile target. We validate this strategy through real-world UAV experiments and simulated analysis in MATLAB, demonstrating its effectiveness in detecting, encircling, and intercepting hostile drones. More details: https://youtu.be/5eHW56lPVto.
A Centralized Planning and Distributed Execution Method for Shape Filling with Homogeneous Mobile Robots
Mar 28, 2025



Nature has inspired humans in different ways. The formation behavior of animals can perform tasks that exceed individual capability. For example, army ants could transverse gaps by forming bridges, and fishes could group up to protect themselves from predators. The pattern formation task is essential in a multiagent robotic system because it usually serves as the initial configuration of downstream tasks, such as collective manipulation and adaptation to various environments. The formation of complex shapes, especially hollow shapes, remains an open question. Traditional approaches either require global coordinates for each robot or are prone to failure when attempting to close the hole due to accumulated localization errors. Inspired by the ribbon idea introduced in the additive self-assembly algorithm by the Kilobot team, we develop a two-stage algorithm that does not require global coordinates information and effectively forms shapes with holes. In this paper, we investigate the partitioning of the shape using ribbons in a hexagonal lattice setting and propose the add-subtract algorithm based on the movement sequence induced by the ribbon structure. This advancement opens the door to tasks requiring complex pattern formations, such as the assembly of nanobots for medical applications involving intricate structures and the deployment of robots along the boundaries of areas of interest. We also provide simulation results on complex shapes, an analysis of the robustness as well as a proof of correctness of the proposed algorithm.
Non-cooperative Stochastic Target Encirclement by Anti-synchronization Control via Range-only Measurement
Feb 08, 2025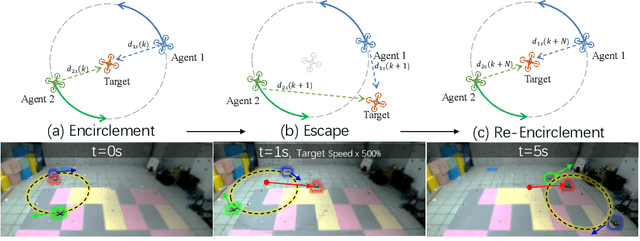
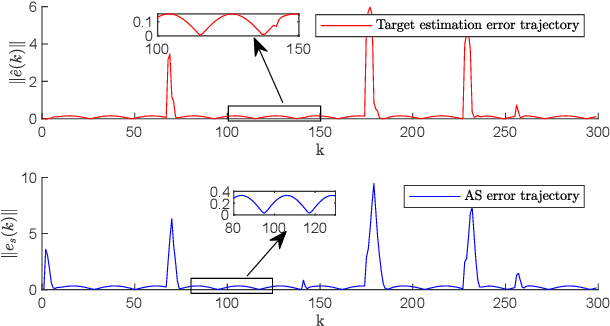
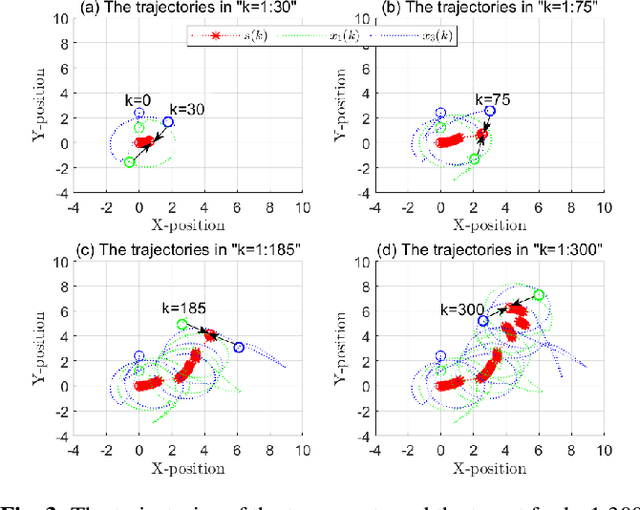
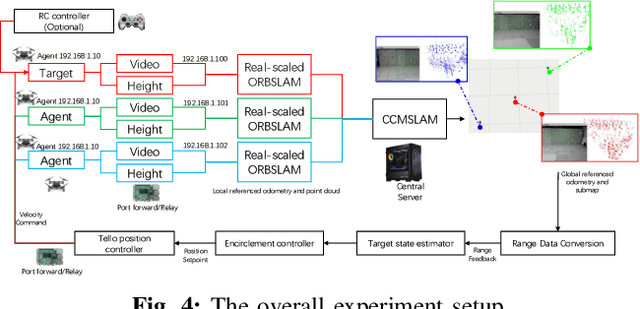
This paper investigates the stochastic moving target encirclement problem in a realistic setting. In contrast to typical assumptions in related works, the target in our work is non-cooperative and capable of escaping the circle containment by boosting its speed to maximum for a short duration. Considering the extreme environment, such as GPS denial, weight limit, and lack of ground guidance, two agents can only rely on their onboard single-modality perception tools to measure the distances to the target. The distance measurement allows for creating a position estimator by providing a target position-dependent variable. Furthermore, the construction of the unique distributed anti-synchronization controller (DASC) can guarantee that the two agents track and encircle the target swiftly. The convergence of the estimator and controller is rigorously evaluated using the Lyapunov technique. A real-world UAV-based experiment is conducted to illustrate the performance of the proposed methodology in addition to a simulated Matlab numerical sample. Our video demonstration can be found in the URL https://youtu.be/JXu1gib99yQ.
Multiple noncooperative targets encirclement by relative distance-based positioning and neural antisynchronization control
Nov 13, 2024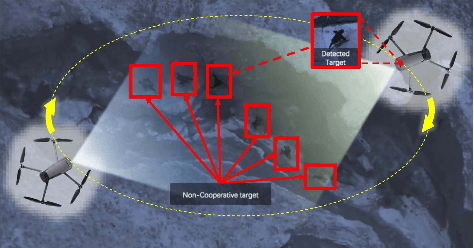
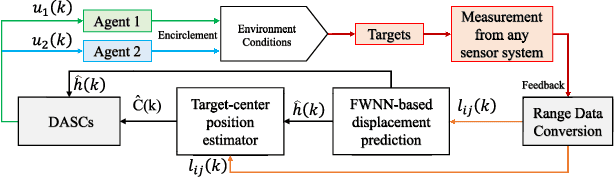
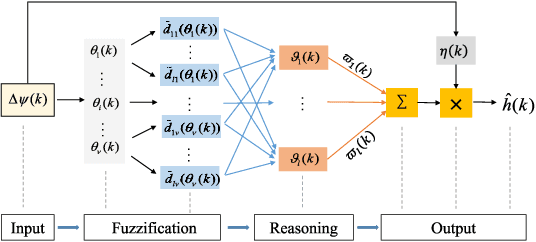
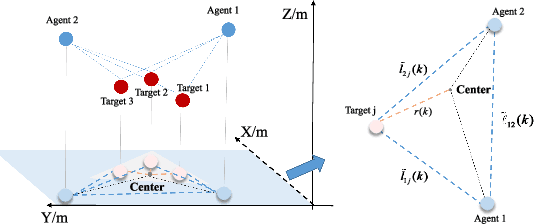
From prehistoric encirclement for hunting to GPS orbiting the earth for positioning, target encirclement has numerous real world applications. However, encircling multiple non-cooperative targets in GPS-denied environments remains challenging. In this work, multiple targets encirclement by using a minimum of two tasking agents, is considered where the relative distance measurements between the agents and the targets can be obtained by using onboard sensors. Based on the measurements, the center of all the targets is estimated directly by a fuzzy wavelet neural network (FWNN) and the least squares fit method. Then, a new distributed anti-synchronization controller (DASC) is designed so that the two tasking agents are able to encircle all targets while staying opposite to each other. In particular, the radius of the desired encirclement trajectory can be dynamically determined to avoid potential collisions between the two agents and all targets. Based on the Lyapunov stability analysis method, the convergence proofs of the neural network prediction error, the target-center position estimation error, and the controller error are addressed respectively. Finally, both numerical simulations and UAV flight experiments are conducted to demonstrate the validity of the encirclement algorithms. The flight tests recorded video and other simulation results can be found in https://youtu.be/B8uTorBNrl4.
Why Studying Cut-ins? Comparing Cut-ins and Other Lane Changes Based on Naturalistic Driving Data
Feb 13, 2024Extensive research has been conducted to explore vehicle lane changes, while the study on cut-ins has not received sufficient attention. The existing studies have not addressed the fundamental question of why studying cut-ins is crucial, despite the extensive investigation into lane changes. To tackle this issue, it is important to demonstrate how cut-ins, as a special type of lane change, differ from other lane changes. In this paper, we explore to compare driving characteristics of cut-ins and other lane changes based on naturalistic driving data. The highD dataset is employed to conduct the comparison. We extract all lane-change events from the dataset and exclude events that are not suitable for our comparison. Lane-change events are then categorized into the cut-in events and other lane-change events based on various gap-based rules. Several performance metrics are designed to measure the driving characteristics of the two types of events. We prove the significant differences between the cut-in behavior and other lane-change behavior by using the Wilcoxon rank-sum test. The results suggest the necessity of conducting specialized studies on cut-ins, offering valuable insights for future research in this field.
STGIN: A Spatial Temporal Graph-Informer Network for Long Sequence Traffic Speed Forecasting
Oct 01, 2022
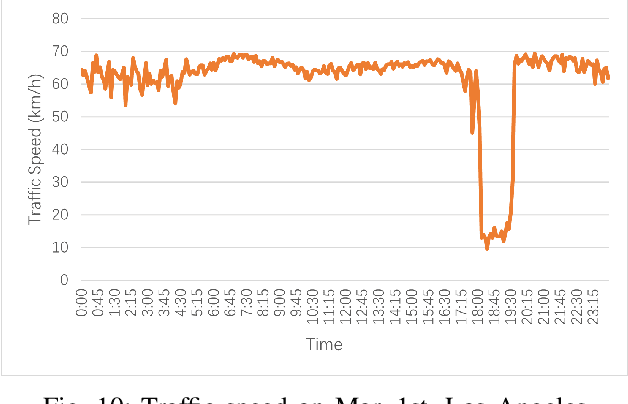
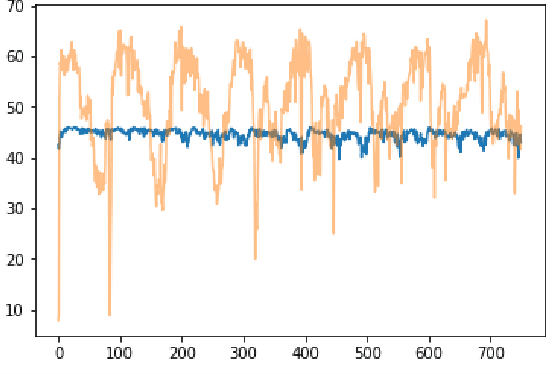
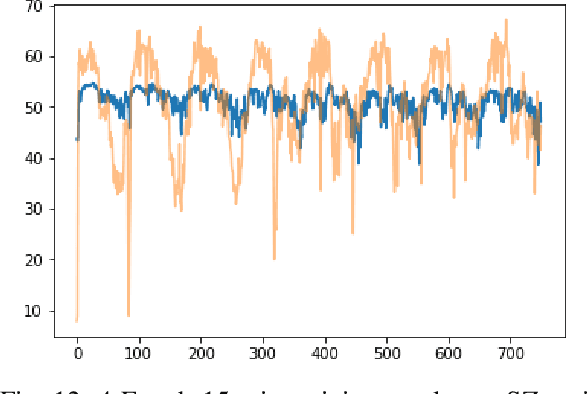
Accurate long series forecasting of traffic information is critical for the development of intelligent traffic systems. We may benefit from the rapid growth of neural network analysis technology to better understand the underlying functioning patterns of traffic networks as a result of this progress. Due to the fact that traffic data and facility utilization circumstances are sequentially dependent on past and present situations, several related neural network techniques based on temporal dependency extraction models have been developed to solve the problem. The complicated topological road structure, on the other hand, amplifies the effect of spatial interdependence, which cannot be captured by pure temporal extraction approaches. Additionally, the typical Deep Recurrent Neural Network (RNN) topology has a constraint on global information extraction, which is required for comprehensive long-term prediction. This study proposes a new spatial-temporal neural network architecture, called Spatial-Temporal Graph-Informer (STGIN), to handle the long-term traffic parameters forecasting issue by merging the Informer and Graph Attention Network (GAT) layers for spatial and temporal relationships extraction. The attention mechanism potentially guarantees long-term prediction performance without significant information loss from distant inputs. On two real-world traffic datasets with varying horizons, experimental findings validate the long sequence prediction abilities, and further interpretation is provided.
Dense-TNT: Efficient Vehicle Type Classification Neural Network Using Satellite Imagery
Sep 27, 2022
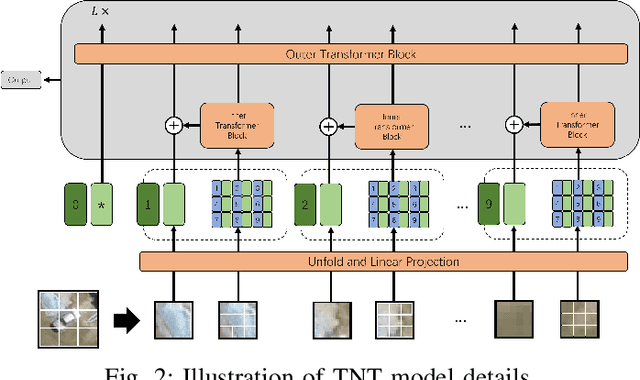
Accurate vehicle type classification serves a significant role in the intelligent transportation system. It is critical for ruler to understand the road conditions and usually contributive for the traffic light control system to response correspondingly to alleviate traffic congestion. New technologies and comprehensive data sources, such as aerial photos and remote sensing data, provide richer and high-dimensional information. Also, due to the rapid development of deep neural network technology, image based vehicle classification methods can better extract underlying objective features when processing data. Recently, several deep learning models have been proposed to solve the problem. However, traditional pure convolutional based approaches have constraints on global information extraction, and the complex environment, such as bad weather, seriously limits the recognition capability. To improve the vehicle type classification capability under complex environment, this study proposes a novel Densely Connected Convolutional Transformer in Transformer Neural Network (Dense-TNT) framework for the vehicle type classification by stacking Densely Connected Convolutional Network (DenseNet) and Transformer in Transformer (TNT) layers. Three-region vehicle data and four different weather conditions are deployed for recognition capability evaluation. Experimental findings validate the recognition ability of our proposed vehicle classification model with little decay, even under the heavy foggy weather condition.
AST-GIN: Attribute-Augmented Spatial-Temporal Graph Informer Network for Electric Vehicle Charging Station Availability Forecasting
Sep 07, 2022

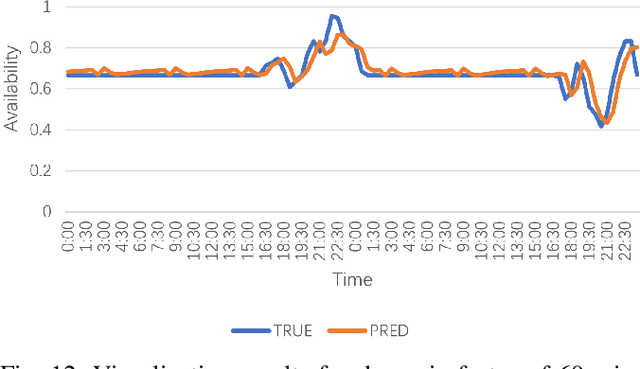
Electric Vehicle (EV) charging demand and charging station availability forecasting is one of the challenges in the intelligent transportation system. With the accurate EV station situation prediction, suitable charging behaviors could be scheduled in advance to relieve range anxiety. Many existing deep learning methods are proposed to address this issue, however, due to the complex road network structure and comprehensive external factors, such as point of interests (POIs) and weather effects, many commonly used algorithms could just extract the historical usage information without considering comprehensive influence of external factors. To enhance the prediction accuracy and interpretability, the Attribute-Augmented Spatial-Temporal Graph Informer (AST-GIN) structure is proposed in this study by combining the Graph Convolutional Network (GCN) layer and the Informer layer to extract both external and internal spatial-temporal dependence of relevant transportation data. And the external factors are modeled as dynamic attributes by the attribute-augmented encoder for training. AST-GIN model is tested on the data collected in Dundee City and experimental results show the effectiveness of our model considering external factors influence over various horizon settings compared with other baselines.
Interpretable Fault Diagnosis of Rolling Element Bearings with Temporal Logic Neural Network
Apr 19, 2022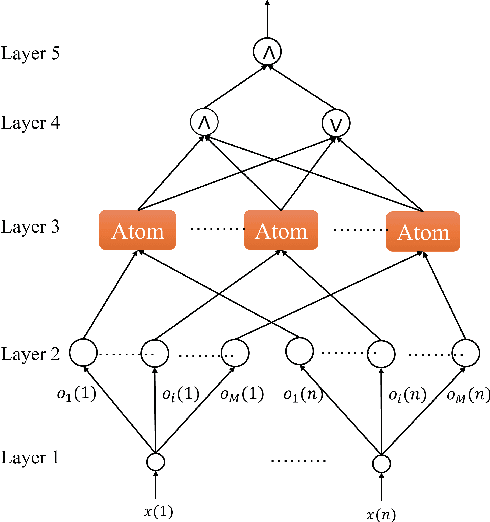
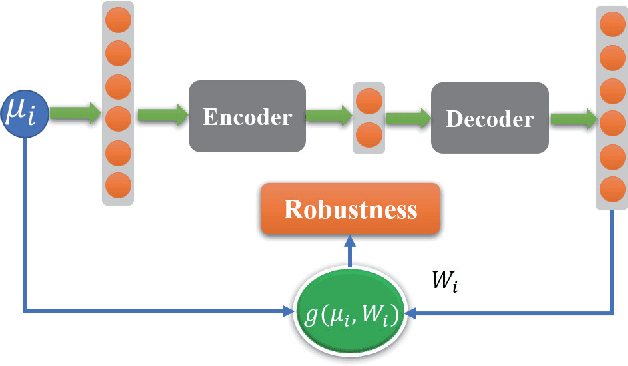

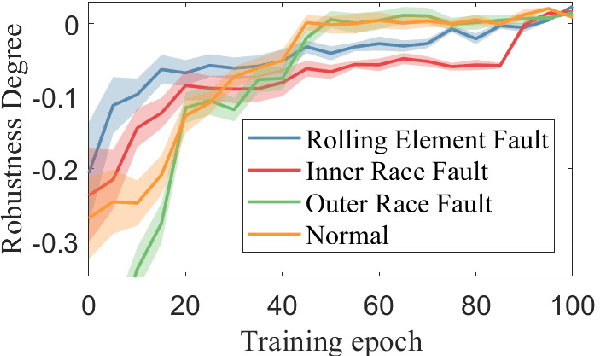
Machine learning-based methods have achieved successful applications in machinery fault diagnosis. However, the main limitation that exists for these methods is that they operate as a black box and are generally not interpretable. This paper proposes a novel neural network structure, called temporal logic neural network (TLNN), in which the neurons of the network are logic propositions. More importantly, the network can be described and interpreted as a weighted signal temporal logic. TLNN not only keeps the nice properties of traditional neuron networks but also provides a formal interpretation of itself with formal language. Experiments with real datasets show the proposed neural network can obtain highly accurate fault diagnosis results with good computation efficiency. Additionally, the embedded formal language of the neuron network can provide explanations about the decision process, thus achieve interpretable fault diagnosis.