 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Horizon Plan Execution in Large Tool Spaces through Entropy-Guided Branching
Apr 13, 2026Large Language Models (LLMs) have significantly advanced tool-augmented agents, enabling autonomous reasoning via API interactions. However, executing multi-step tasks within massive tool libraries remains challenging due to two critical bottlenecks: (1) the absence of rigorous, plan-level evaluation frameworks and (2) the computational demand of exploring vast decision spaces stemming from large toolsets and long-horizon planning. To bridge these gaps, we first introduce SLATE (Synthetic Large-scale API Toolkit for E-commerce), a large-scale context-aware benchmark designed for the automated assessment of tool-integrated agents. Unlike static metrics, SLATE accommodates diverse yet functionally valid execution trajectories, revealing that current agents struggle with self-correction and search efficiency. Motivated by these findings, we next propose Entropy-Guided Branching (EGB), an uncertainty-aware search algorithm that dynamically expands decision branches where predictive entropy is high. EGB optimizes the exploration-exploitation trade-off, significantly enhancing both task success rates and computational efficiency. Extensive experiments on SLATE demonstrate that our dual contribution provides a robust foundation for developing reliable and scalable LLM agents in tool-rich environments.
CharacterFlywheel: Scaling Iterative Improvement of Engaging and Steerable LLMs in Production
Mar 02, 2026This report presents CharacterFlywheel, an iterative flywheel process for improving large language models (LLMs) in production social chat applications across Instagram, WhatsApp, and Messenger. Starting from LLaMA 3.1, we refined models across 15 generations using data from both internal and external real-user traffic. Through continuous deployments from July 2024 to April 2025, we conducted controlled 7-day A/B tests showing consistent engagement improvements: 7 of 8 newly deployed models demonstrated positive lift over the baseline, with the strongest performers achieving up to 8.8% improvement in engagement breadth and 19.4% in engagement depth. We also observed substantial gains in steerability, with instruction following increasing from 59.2% to 84.8% and instruction violations decreasing from 26.6% to 5.8%. We detail the CharacterFlywheel process which integrates data curation, reward modeling to estimate and interpolate the landscape of engagement metrics, supervised fine-tuning (SFT), reinforcement learning (RL), and both offline and online evaluation to ensure reliable progress at each optimization step. We also discuss our methods for overfitting prevention and navigating production dynamics at scale. These contributions advance the scientific rigor and understanding of LLMs in social applications serving millions of users.
Paying Less Generalization Tax: A Cross-Domain Generalization Study of RL Training for LLM Agents
Jan 26, 2026Generalist LLM agents are often post-trained on a narrow set of environments but deployed across far broader, unseen domains. In this work, we investigate the challenge of agentic post-training when the eventual test domains are unknown. Specifically, we analyze which properties of reinforcement learning (RL) environments and modeling choices have the greatest influence on out-of-domain performance. First, we identify two environment axes that strongly correlate with cross-domain generalization: (i) state information richness, i.e., the amount of information for the agent to process from the state, and (ii) planning complexity, estimated via goal reachability and trajectory length under a base policy. Notably, domain realism and text-level similarity are not the primary factors; for instance, the simple grid-world domain Sokoban leads to even stronger generalization in SciWorld than the more realistic ALFWorld. Motivated by these findings, we further show that increasing state information richness alone can already effectively improve cross-domain robustness. We propose a randomization technique, which is low-overhead and broadly applicable: add small amounts of distractive goal-irrelevant features to the state to make it richer without altering the task. Beyond environment-side properties, we also examine several modeling choices: (a) SFT warmup or mid-training helps prevent catastrophic forgetting during RL but undermines generalization to domains that are not included in the mid-training datamix; and (b) turning on step-by-step thinking during RL, while not always improving in-domain performance, plays a crucial role in preserving generalization.
Rotate Your Character: Revisiting Video Diffusion Models for High-Quality 3D Character Generation
Jan 09, 2026Generating high-quality 3D characters from single images remains a significant challenge in digital content creation, particularly due to complex body poses and self-occlusion. In this paper, we present RCM (Rotate your Character Model), an advanced image-to-video diffusion framework tailored for high-quality novel view synthesis (NVS) and 3D character generation. Compared to existing diffusion-based approaches, RCM offers several key advantages: (1) transferring characters with any complex poses into a canonical pose, enabling consistent novel view synthesis across the entire viewing orbit, (2) high-resolution orbital video generation at 1024x1024 resolution, (3) controllable observation positions given different initial camera poses, and (4) multi-view conditioning supporting up to 4 input images, accommodating diverse user scenarios. Extensive experiments demonstrate that RCM outperforms state-of-the-art methods in both novel view synthesis and 3D generation quality.
Underwater target 6D State Estimation via UUV Attitude Enhance Observability
Jun 16, 2025Accurate relative state observation of Unmanned Underwater Vehicles (UUVs) for tracking uncooperative targets remains a significant challenge due to the absence of GPS, complex underwater dynamics, and sensor limitations. Existing localization approaches rely on either global positioning infrastructure or multi-UUV collaboration, both of which are impractical for a single UUV operating in large or unknown environments. To address this, we propose a novel persistent relative 6D state estimation framework that enables a single UUV to estimate its relative motion to a non-cooperative target using only successive noisy range measurements from two monostatic sonar sensors. Our key contribution is an observability-enhanced attitude control strategy, which optimally adjusts the UUV's orientation to improve the observability of relative state estimation using a Kalman filter, effectively mitigating the impact of sensor noise and drift accumulation. Additionally, we introduce a rigorously proven Lyapunov-based tracking control strategy that guarantees long-term stability by ensuring that the UUV maintains an optimal measurement range, preventing localization errors from diverging over time. Through theoretical analysis and simulations, we demonstrate that our method significantly improves 6D relative state estimation accuracy and robustness compared to conventional approaches. This work provides a scalable, infrastructure-free solution for UUVs tracking uncooperative targets underwater.
Consistency-aware Fake Videos Detection on Short Video Platforms
Apr 30, 2025This paper focuses to detect the fake news on the short video platforms. While significant research efforts have been devoted to this task with notable progress in recent years, current detection accuracy remains suboptimal due to the rapid evolution of content manipulation and generation technologies. Existing approaches typically employ a cross-modal fusion strategy that directly combines raw video data with metadata inputs before applying a classification layer. However, our empirical observations reveal a critical oversight: manipulated content frequently exhibits inter-modal inconsistencies that could serve as valuable discriminative features, yet remain underutilized in contemporary detection frameworks. Motivated by this insight, we propose a novel detection paradigm that explicitly identifies and leverages cross-modal contradictions as discriminative cues. Our approach consists of two core modules: Cross-modal Consistency Learning (CMCL) and Multi-modal Collaborative Diagnosis (MMCD). CMCL includes Pseudo-label Generation (PLG) and Cross-modal Consistency Diagnosis (CMCD). In PLG, a Multimodal Large Language Model is used to generate pseudo-labels for evaluating cross-modal semantic consistency. Then, CMCD extracts [CLS] tokens and computes cosine loss to quantify cross-modal inconsistencies. MMCD further integrates multimodal features through Multimodal Feature Fusion (MFF) and Probability Scores Fusion (PSF). MFF employs a co-attention mechanism to enhance semantic interactions across different modalities, while a Transformer is utilized for comprehensive feature fusion. Meanwhile, PSF further integrates the fake news probability scores obtained in the previous step. Extensive experiments on established benchmarks (FakeSV and FakeTT) demonstrate our model exhibits outstanding performance in Fake videos detection.
Stably unactivated neurons in ReLU neural networks
Dec 06, 2024



The choice of architecture of a neural network influences which functions will be realizable by that neural network and, as a result, studying the expressiveness of a chosen architecture has received much attention. In ReLU neural networks, the presence of stably unactivated neurons can reduce the network's expressiveness. In this work, we investigate the probability of a neuron in the second hidden layer of such neural networks being stably unactivated when the weights and biases are initialized from symmetric probability distributions. For networks with input dimension $n_0$, we prove that if the first hidden layer has $n_0+1$ neurons then this probability is exactly $\frac{2^{n_0}+1}{4^{n_0+1}}$, and if the first hidden layer has $n_1$ neurons, $n_1 \le n_0$, then the probability is $\frac{1}{2^{n_1+1}}$. Finally, for the case when the first hidden layer has more neurons than $n_0+1$, a conjecture is proposed along with the rationale. Computational evidence is presented to support the conjecture.
IPMix: Label-Preserving Data Augmentation Method for Training Robust Classifiers
Oct 17, 2023
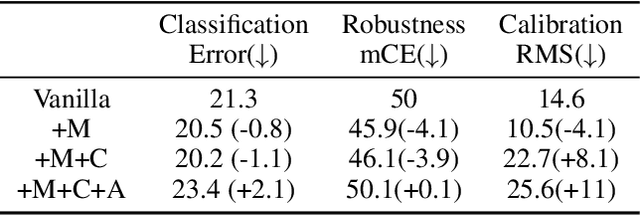

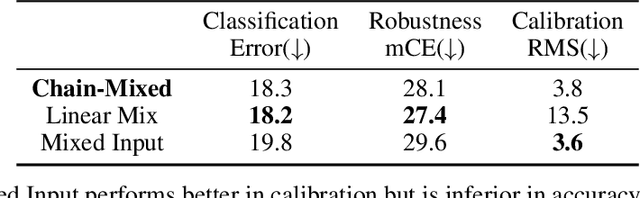
Data augmentation has been proven effective for training high-accuracy convolutional neural network classifiers by preventing overfitting. However, building deep neural networks in real-world scenarios requires not only high accuracy on clean data but also robustness when data distributions shift. While prior methods have proposed that there is a trade-off between accuracy and robustness, we propose IPMix, a simple data augmentation approach to improve robustness without hurting clean accuracy. IPMix integrates three levels of data augmentation (image-level, patch-level, and pixel-level) into a coherent and label-preserving technique to increase the diversity of training data with limited computational overhead. To further improve the robustness, IPMix introduces structural complexity at different levels to generate more diverse images and adopts the random mixing method for multi-scale information fusion. Experiments demonstrate that IPMix outperforms state-of-the-art corruption robustness on CIFAR-C and ImageNet-C. In addition, we show that IPMix also significantly improves the other safety measures, including robustness to adversarial perturbations, calibration, prediction consistency, and anomaly detection, achieving state-of-the-art or comparable results on several benchmarks, including ImageNet-R, ImageNet-A, and ImageNet-O.
Evaluating the Generation Capabilities of Large Chinese Language Models
Aug 11, 2023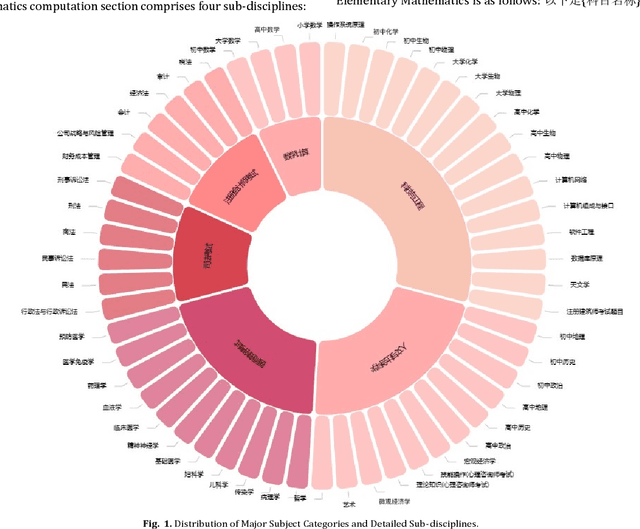

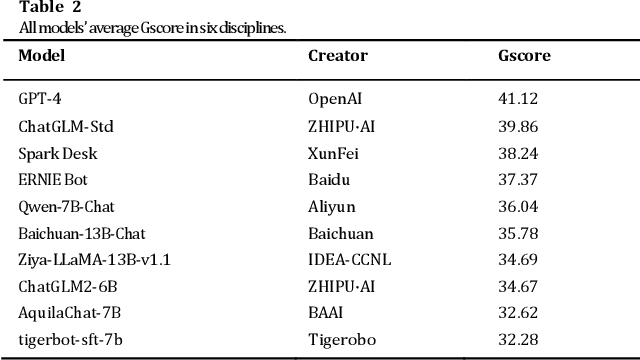
This paper presents CG-Eval, the first comprehensive evaluation of the generation capabilities of large Chinese language models across a wide range of academic disciplines. The models' performance was assessed based on their ability to generate accurate and relevant responses to different types of questions in six disciplines, namely, Science and Engineering, Humanities and Social Sciences, Mathematical Calculations, Medical Practitioner Qualification Examination, Judicial Examination, and Certified Public Accountant Examination. This paper also presents Gscore, a composite index derived from the weighted sum of multiple metrics to measure the quality of model's generation against a reference. The test data and test results can be found at http://cgeval.besteasy.com/.
Face Image Quality Enhancement Study for Face Recognition
Jul 08, 2023Unconstrained face recognition is an active research area among computer vision and biometric researchers for many years now. Still the problem of face recognition in low quality photos has not been well-studied so far. In this paper, we explore the face recognition performance on low quality photos, and we try to improve the accuracy in dealing with low quality face images. We assemble a large database with low quality photos, and examine the performance of face recognition algorithms for three different quality sets. Using state-of-the-art facial image enhancement approaches, we explore the face recognition performance for the enhanced face images. To perform this without experimental bias, we have developed a new protocol for recognition with low quality face photos and validate the performance experimentally. Our designed protocol for face recognition with low quality face images can be useful to other researchers. Moreover, experiment results show some of the challenging aspects of this problem.