 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-based Analysis Reveals Atypical Social Gaze in People with Autism Spectrum Disorder
Sep 01, 2024

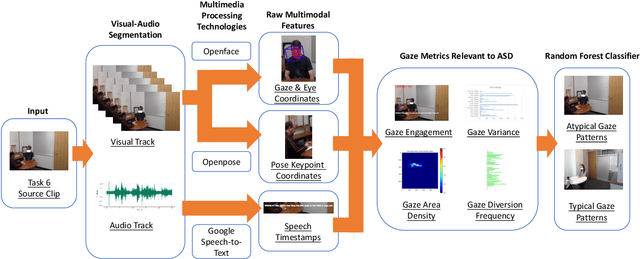

In this study, we present a quantitative and comprehensive analysis of social gaze in people with autism spectrum disorder (ASD). Diverging from traditional first-person camera perspectives based on eye-tracking technologies, this study utilizes a third-person perspective database from the Autism Diagnostic Observation Schedule, 2nd Edition (ADOS-2) interview videos, encompassing ASD participants and neurotypical individuals as a reference group. Employing computational models, we extracted and processed gaze-related features from the videos of both participants and examiners. The experimental samples were divided into three groups based on the presence of social gaze abnormalities and ASD diagnosis. This study quantitatively analyzed four gaze features: gaze engagement, gaze variance, gaze density map, and gaze diversion frequency. Furthermore, we developed a classifier trained on these features to identify gaze abnormalities in ASD participants. Together, we demonstrated the effectiveness of analyzing social gaze in people with ASD in naturalistic settings, showcasing the potential of third-person video perspectives in enhancing ASD diagnosis through gaze analysis.
Exploiting ChatGPT for Diagnosing Autism-Associated Language Disorders and Identifying Distinct Features
May 03, 2024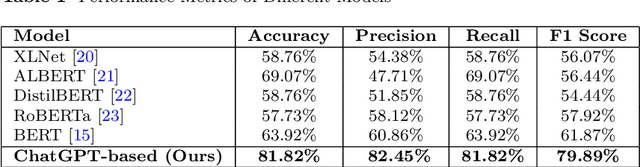
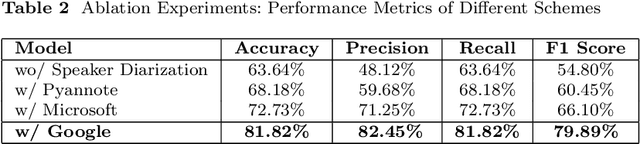
Diagnosing language disorders associated with autism is a complex and nuanced challenge, often hindered by the subjective nature and variability of traditional assessment methods. Traditional diagnostic methods not only require intensive human effort but also often result in delayed interventions due to their lack of speed and specificity. In this study, we explored the application of ChatGPT, a state of the art large language model, to overcome these obstacles by enhancing diagnostic accuracy and profiling specific linguistic features indicative of autism. Leveraging ChatGPT advanced natural language processing capabilities, this research aims to streamline and refine the diagnostic process. Specifically, we compared ChatGPT's performance with that of conventional supervised learning models, including BERT, a model acclaimed for its effectiveness in various natural language processing tasks. We showed that ChatGPT substantially outperformed these models, achieving over 13% improvement in both accuracy and F1 score in a zero shot learning configuration. This marked enhancement highlights the model potential as a superior tool for neurological diagnostics. Additionally, we identified ten distinct features of autism associated language disorders that vary significantly across different experimental scenarios. These features, which included echolalia, pronoun reversal, and atypical language usage, were crucial for accurately diagnosing ASD and customizing treatment plans. Together, our findings advocate for adopting sophisticated AI tools like ChatGPT in clinical settings to assess and diagnose developmental disorders. Our approach not only promises greater diagnostic precision but also aligns with the goals of personalized medicine, potentially transforming the evaluation landscape for autism and similar neurological conditions.
Exploring Speech Pattern Disorders in Autism using Machine Learning
May 03, 2024
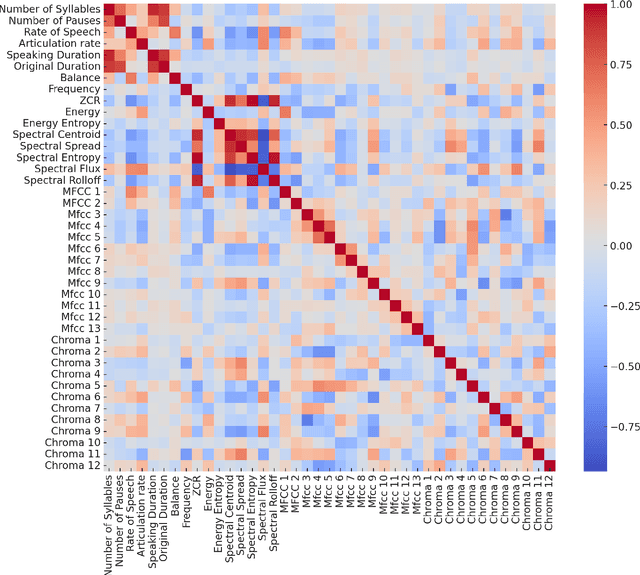
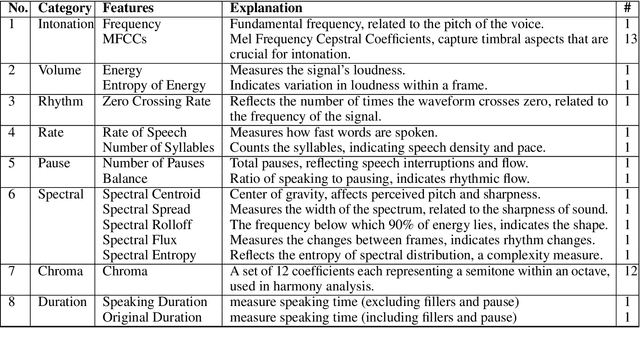
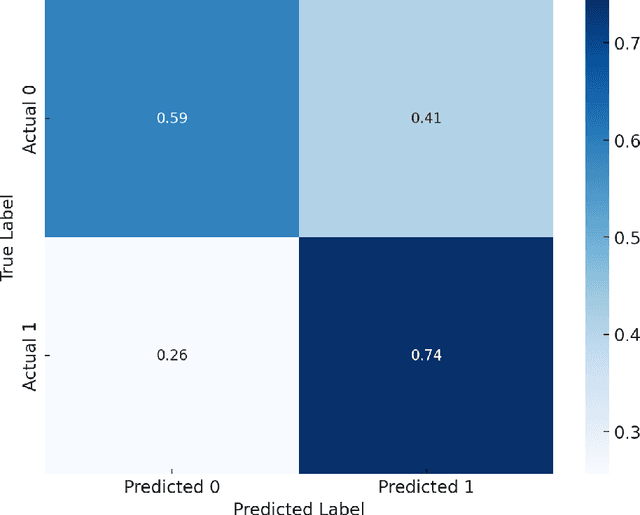
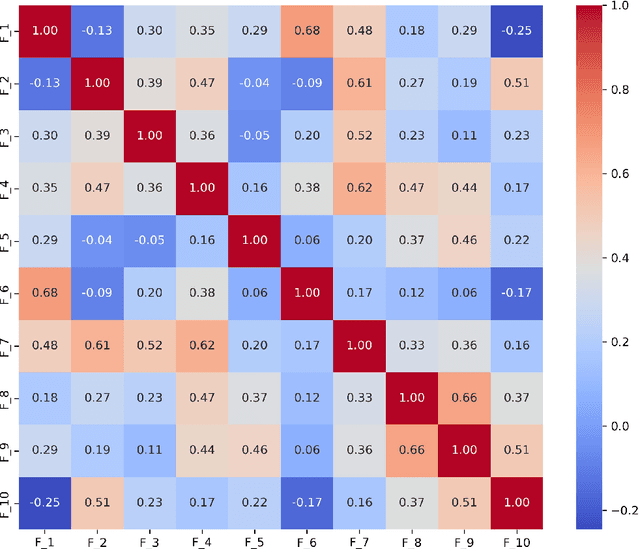
Diagnosing autism spectrum disorder (ASD) by identifying abnormal speech patterns from examiner-patient dialogues presents significant challenges due to the subtle and diverse manifestations of speech-related symptoms in affected individuals. This study presents a comprehensive approach to identify distinctive speech patterns through the analysis of examiner-patient dialogues. Utilizing a dataset of recorded dialogues, we extracted 40 speech-related features, categorized into frequency, zero-crossing rate, energy, spectral characteristics, Mel Frequency Cepstral Coefficients (MFCCs), and balance. These features encompass various aspects of speech such as intonation, volume, rhythm, and speech rate, reflecting the complex nature of communicative behaviors in ASD. We employed machine learning for both classification and regression tasks to analyze these speech features. The classification model aimed to differentiate between ASD and non-ASD cases, achieving an accuracy of 87.75%. Regression models were developed to predict speech pattern related variables and a composite score from all variables, facilitating a deeper understanding of the speech dynamics associated with ASD. The effectiveness of machine learning in interpreting intricate speech patterns and the high classification accuracy underscore the potential of computational methods in supporting the diagnostic processes for ASD. This approach not only aids in early detection but also contributes to personalized treatment planning by providing insights into the speech and communication profiles of individuals with ASD.
Video-based Contrastive Learning on Decision Trees: from Action Recognition to Autism Diagnosis
Apr 21, 2023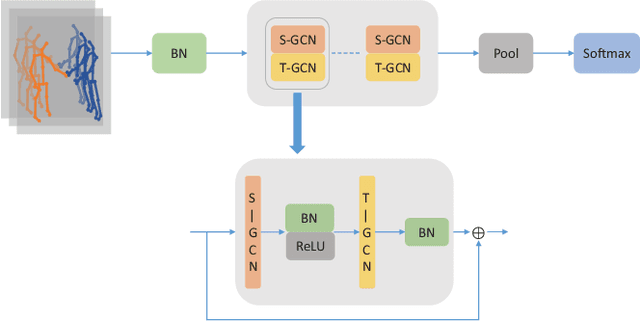
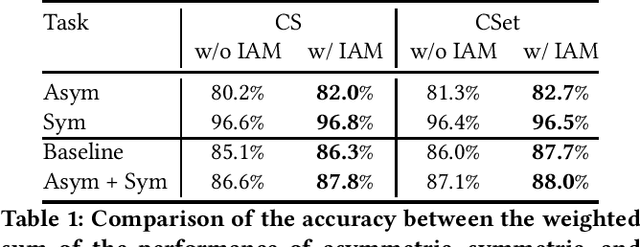
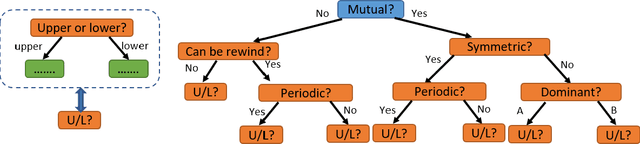
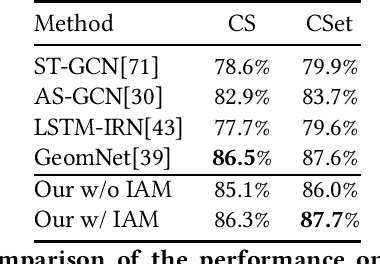
How can we teach a computer to recognize 10,000 different actions? Deep learning has evolved from supervised and unsupervised to self-supervised approaches. In this paper, we present a new contrastive learning-based framework for decision tree-based classification of actions, including human-human interactions (HHI) and human-object interactions (HOI). The key idea is to translate the original multi-class action recognition into a series of binary classification tasks on a pre-constructed decision tree. Under the new framework of contrastive learning, we present the design of an interaction adjacent matrix (IAM) with skeleton graphs as the backbone for modeling various action-related attributes such as periodicity and symmetry. Through the construction of various pretext tasks, we obtain a series of binary classification nodes on the decision tree that can be combined to support higher-level recognition tasks. Experimental justification for the potential of our approach in real-world applications ranges from interaction recognition to symmetry detection. In particular, we have demonstrated the promising performance of video-based autism spectrum disorder (ASD) diagnosis on the CalTech interview video database.
Perceptual Quality Assessment of UGC Gaming Videos
Apr 13, 2022
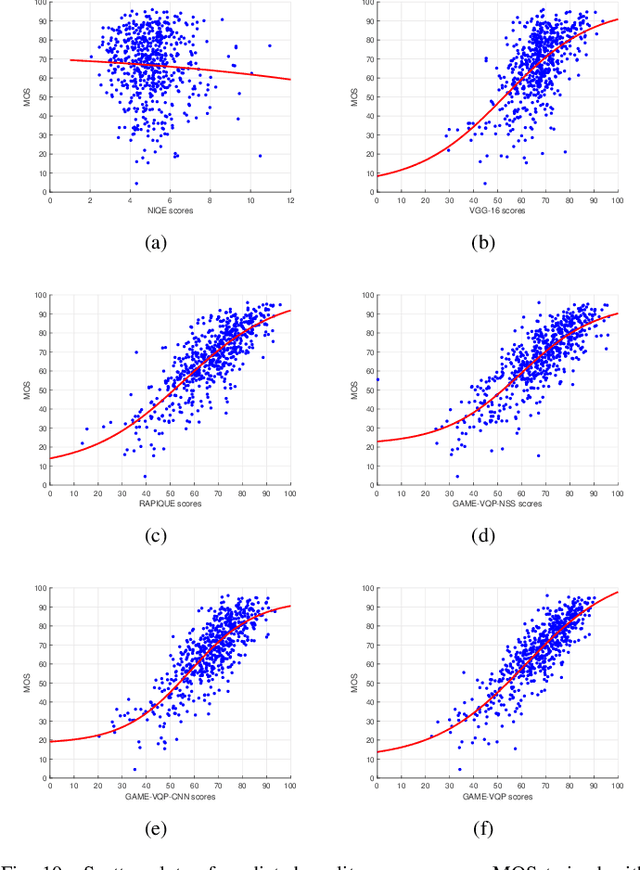
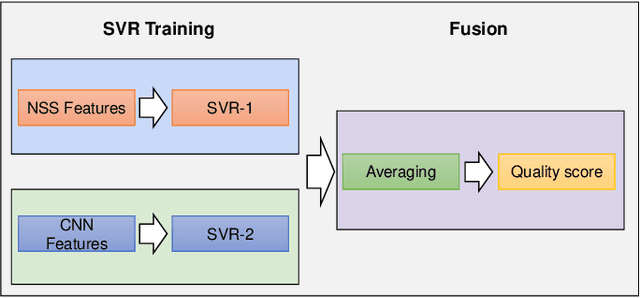
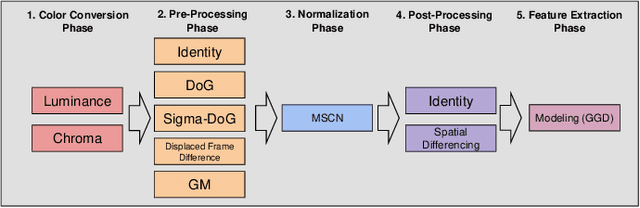
In recent years, with the vigorous development of the video game industry, the proportion of gaming videos on major video websites like YouTube has dramatically increased. However, relatively little research has been done on the automatic quality prediction of gaming videos, especially on those that fall in the category of "User-Generated-Content" (UGC). Since current leading general-purpose Video Quality Assessment (VQA) models do not perform well on this type of gaming videos, we have created a new VQA model specifically designed to succeed on UGC gaming videos, which we call the Gaming Video Quality Predictor (GAME-VQP). GAME-VQP successfully predicts the unique statistical characteristics of gaming videos by drawing upon features designed under modified natural scene statistics models, combined with gaming specific features learned by a Convolution Neural Network. We study the performance of GAME-VQP on a very recent large UGC gaming video database called LIVE-YT-Gaming, and find that it both outperforms other mainstream general VQA models as well as VQA models specifically designed for gaming videos. The new model will be made public after paper being accepted.
Subjective and Objective Analysis of Streamed Gaming Videos
Mar 24, 2022
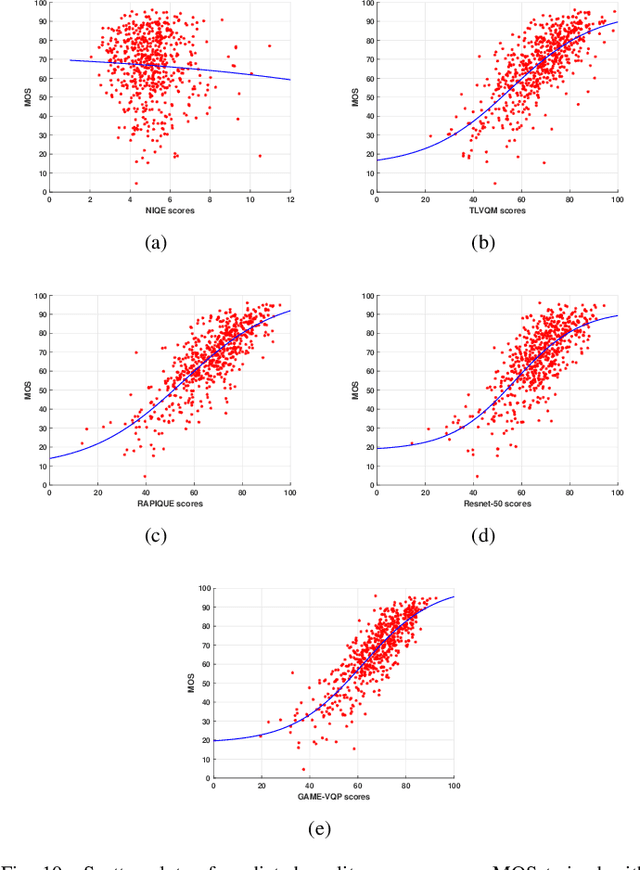
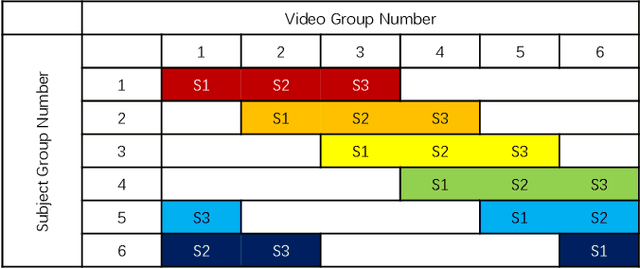
The rising popularity of online User-Generated-Content (UGC) in the form of streamed and shared videos, has hastened the development of perceptual Video Quality Assessment (VQA) models, which can be used to help optimize their delivery. Gaming videos, which are a relatively new type of UGC videos, are created when skilled gamers post videos of their gameplay. These kinds of screenshots of UGC gameplay videos have become extremely popular on major streaming platforms like YouTube and Twitch. Synthetically-generated gaming content presents challenges to existing VQA algorithms, including those based on natural scene/video statistics models. Synthetically generated gaming content presents different statistical behavior than naturalistic videos. A number of studies have been directed towards understanding the perceptual characteristics of professionally generated gaming videos arising in gaming video streaming, online gaming, and cloud gaming. However, little work has been done on understanding the quality of UGC gaming videos, and how it can be characterized and predicted. Towards boosting the progress of gaming video VQA model development, we conducted a comprehensive study of subjective and objective VQA models on UGC gaming videos. To do this, we created a novel UGC gaming video resource, called the LIVE-YouTube Gaming video quality (LIVE-YT-Gaming) database, comprised of 600 real UGC gaming videos. We conducted a subjective human study on this data, yielding 18,600 human quality ratings recorded by 61 human subjects. We also evaluated a number of state-of-the-art (SOTA) VQA models on the new database, including a new one, called GAME-VQP, based on both natural video statistics and CNN-learned features. To help support work in this field, we are making the new LIVE-YT-Gaming Database, publicly available through the link: https://live.ece.utexas.edu/research/LIVE-YT-Gaming/index.html .
RAPIQUE: Rapid and Accurate Video Quality Prediction of User Generated Content
Jan 26, 2021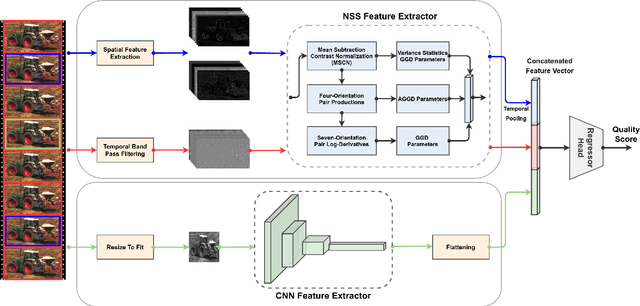
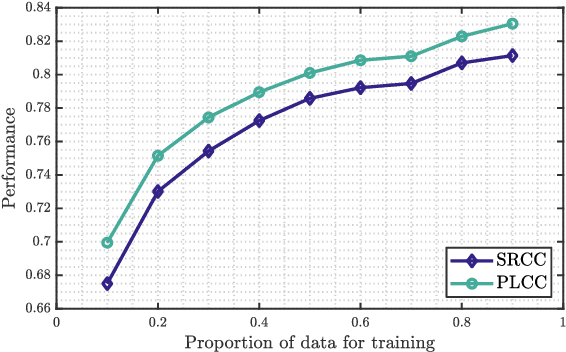
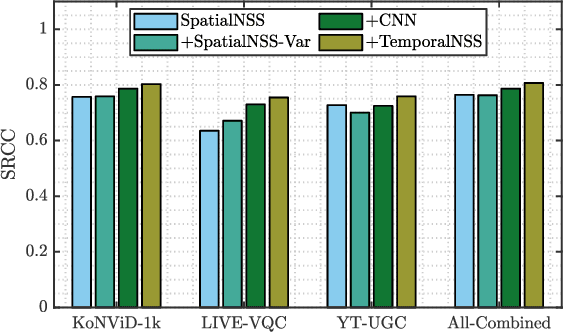
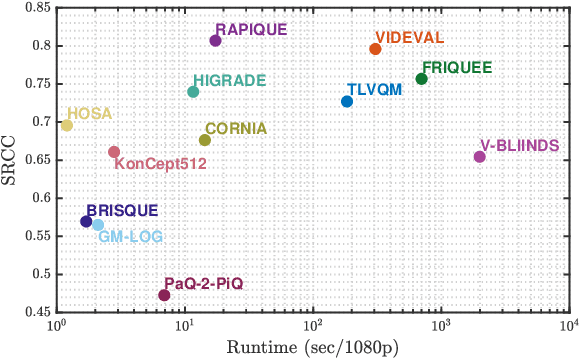
Blind or no-reference video quality assessment of user-generated content (UGC) has become a trending, challenging, unsolved problem. Accurate and efficient video quality predictors suitable for this content are thus in great demand to achieve more intelligent analysis and processing of UGC videos. Previous studies have shown that natural scene statistics and deep learning features are both sufficient to capture spatial distortions, which contribute to a significant aspect of UGC video quality issues. However, these models are either incapable or inefficient for predicting the quality of complex and diverse UGC videos in practical applications. Here we introduce an effective and efficient video quality model for UGC content, which we dub the Rapid and Accurate Video Quality Evaluator (RAPIQUE), which we show performs comparably to state-of-the-art (SOTA) models but with orders-of-magnitude faster runtime. RAPIQUE combines and leverages the advantages of both quality-aware scene statistics features and semantics-aware deep convolutional features, allowing us to design the first general and efficient spatial and temporal (space-time) bandpass statistics model for video quality modeling. Our experimental results on recent large-scale UGC video quality databases show that RAPIQUE delivers top performances on all the datasets at a considerably lower computational expense. We hope this work promotes and inspires further efforts towards practical modeling of video quality problems for potential real-time and low-latency applications. To promote public usage, an implementation of RAPIQUE has been made freely available online: \url{https://github.com/vztu/RAPIQUE}.
Subjective and Objective Quality Assessment of High Frame Rate Videos
Jul 22, 2020
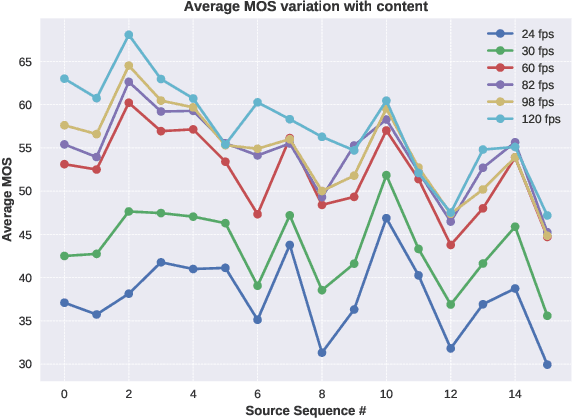
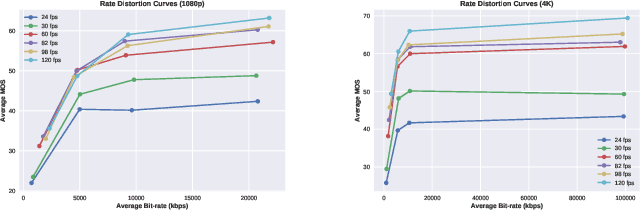
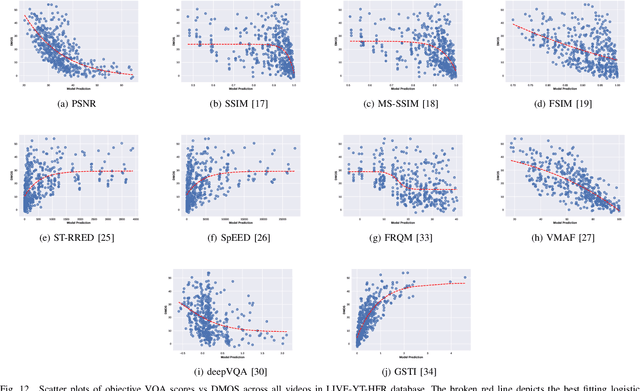
High frame rate (HFR) videos are becoming increasingly common with the tremendous popularity of live, high-action streaming content such as sports. Although HFR contents are generally of very high quality, high bandwidth requirements make them challenging to deliver efficiently, while simultaneously maintaining their quality. To optimize trade-offs between bandwidth requirements and video quality, in terms of frame rate adaptation, it is imperative to understand the intricate relationship between frame rate and perceptual video quality. Towards advancing progression in this direction we designed a new subjective resource, called the LIVE-YouTube-HFR (LIVE-YT-HFR) dataset, which is comprised of 480 videos having 6 different frame rates, obtained from 16 diverse contents. In order to understand the combined effects of compression and frame rate adjustment, we also processed videos at 5 compression levels at each frame rate. To obtain subjective labels on the videos, we conducted a human study yielding 19,000 human quality ratings obtained from a pool of 85 human subjects. We also conducted a holistic evaluation of existing state-of-the-art Full and No-Reference video quality algorithms, and statistically benchmarked their performance on the new database. The LIVE-YT-HFR database has been made available online for public use and evaluation purposes, with hopes that it will help advance research in this exciting video technology direction. It may be obtained at \url{https://live.ece.utexas.edu/research/LIVE_YT_HFR/LIVE_YT_HFR/index.html}