 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCONVIQT: Contrastive Video Quality Estimator
Jun 29, 2022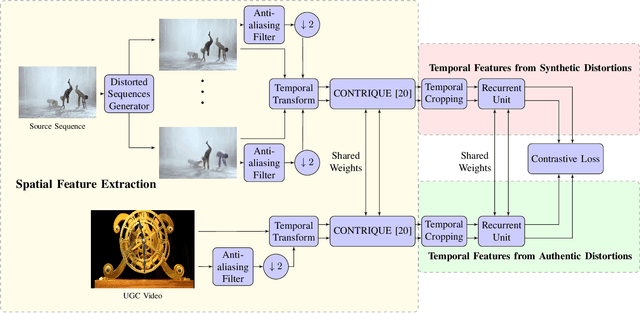


Perceptual video quality assessment (VQA) is an integral component of many streaming and video sharing platforms. Here we consider the problem of learning perceptually relevant video quality representations in a self-supervised manner. Distortion type identification and degradation level determination is employed as an auxiliary task to train a deep learning model containing a deep Convolutional Neural Network (CNN) that extracts spatial features, as well as a recurrent unit that captures temporal information. The model is trained using a contrastive loss and we therefore refer to this training framework and resulting model as CONtrastive VIdeo Quality EstimaTor (CONVIQT). During testing, the weights of the trained model are frozen, and a linear regressor maps the learned features to quality scores in a no-reference (NR) setting. We conduct comprehensive evaluations of the proposed model on multiple VQA databases by analyzing the correlations between model predictions and ground-truth quality ratings, and achieve competitive performance when compared to state-of-the-art NR-VQA models, even though it is not trained on those databases. Our ablation experiments demonstrate that the learned representations are highly robust and generalize well across synthetic and realistic distortions. Our results indicate that compelling representations with perceptual bearing can be obtained using self-supervised learning. The implementations used in this work have been made available at https://github.com/pavancm/CONVIQT.
Making Video Quality Assessment Models Sensitive to Frame Rate Distortions
May 21, 2022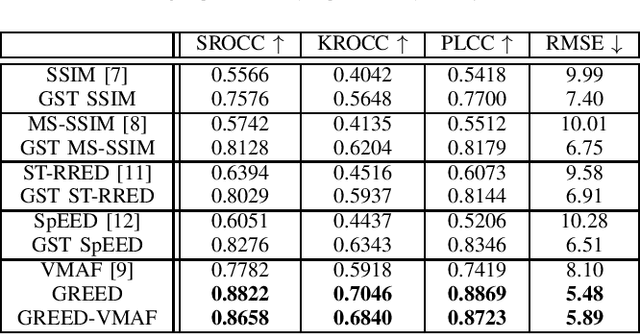
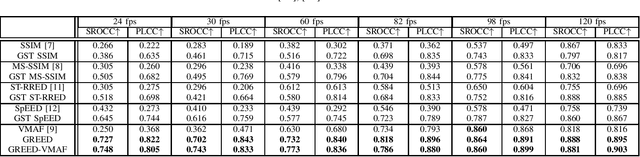
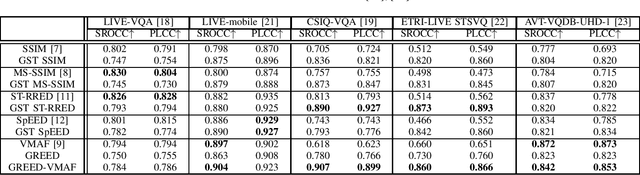
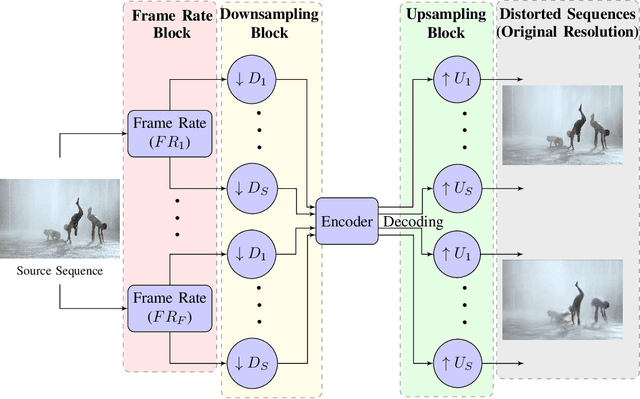
We consider the problem of capturing distortions arising from changes in frame rate as part of Video Quality Assessment (VQA). Variable frame rate (VFR) videos have become much more common, and streamed videos commonly range from 30 frames per second (fps) up to 120 fps. VFR-VQA offers unique challenges in terms of distortion types as well as in making non-uniform comparisons of reference and distorted videos having different frame rates. The majority of current VQA models require compared videos to be of the same frame rate, but are unable to adequately account for frame rate artifacts. The recently proposed Generalized Entropic Difference (GREED) VQA model succeeds at this task, using natural video statistics models of entropic differences of temporal band-pass coefficients, delivering superior performance on predicting video quality changes arising from frame rate distortions. Here we propose a simple fusion framework, whereby temporal features from GREED are combined with existing VQA models, towards improving model sensitivity towards frame rate distortions. We find through extensive experiments that this feature fusion significantly boosts model performance on both HFR/VFR datasets as well as fixed frame rate (FFR) VQA databases. Our results suggest that employing efficient temporal representations can result much more robust and accurate VQA models when frame rate variations can occur.
FAVER: Blind Quality Prediction of Variable Frame Rate Videos
Jan 05, 2022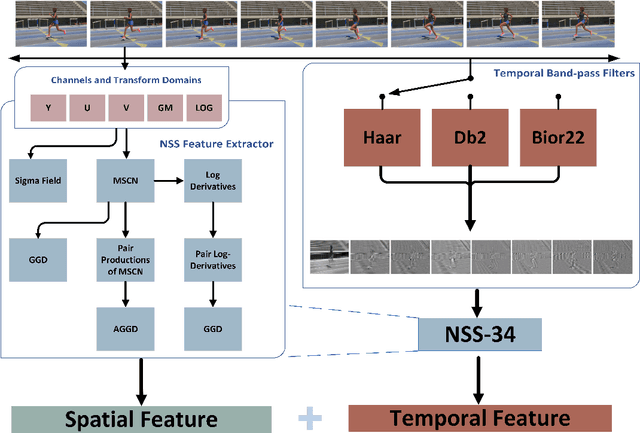
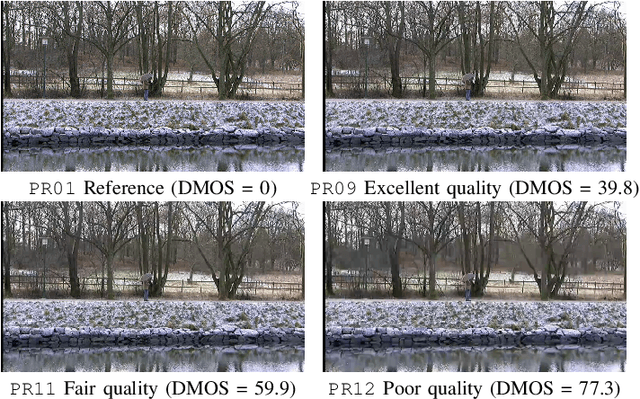
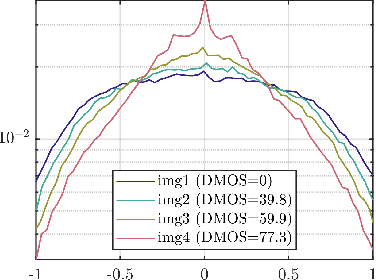
Video quality assessment (VQA) remains an important and challenging problem that affects many applications at the widest scales. Recent advances in mobile devices and cloud computing techniques have made it possible to capture, process, and share high resolution, high frame rate (HFR) videos across the Internet nearly instantaneously. Being able to monitor and control the quality of these streamed videos can enable the delivery of more enjoyable content and perceptually optimized rate control. Accordingly, there is a pressing need to develop VQA models that can be deployed at enormous scales. While some recent effects have been applied to full-reference (FR) analysis of variable frame rate and HFR video quality, the development of no-reference (NR) VQA algorithms targeting frame rate variations has been little studied. Here, we propose a first-of-a-kind blind VQA model for evaluating HFR videos, which we dub the Framerate-Aware Video Evaluator w/o Reference (FAVER). FAVER uses extended models of spatial natural scene statistics that encompass space-time wavelet-decomposed video signals, to conduct efficient frame rate sensitive quality prediction. Our extensive experiments on several HFR video quality datasets show that FAVER outperforms other blind VQA algorithms at a reasonable computational cost. To facilitate reproducible research and public evaluation, an implementation of FAVER is being made freely available online: \url{https://github.com/uniqzheng/HFR-BVQA}.
Image Quality Assessment using Contrastive Learning
Oct 25, 2021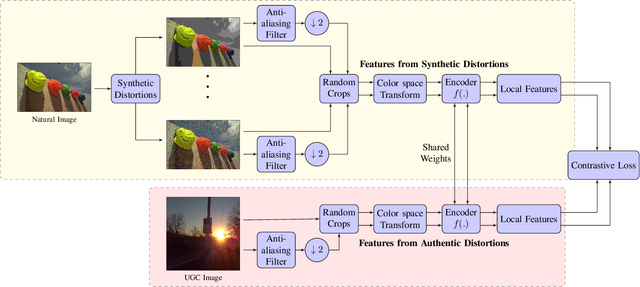
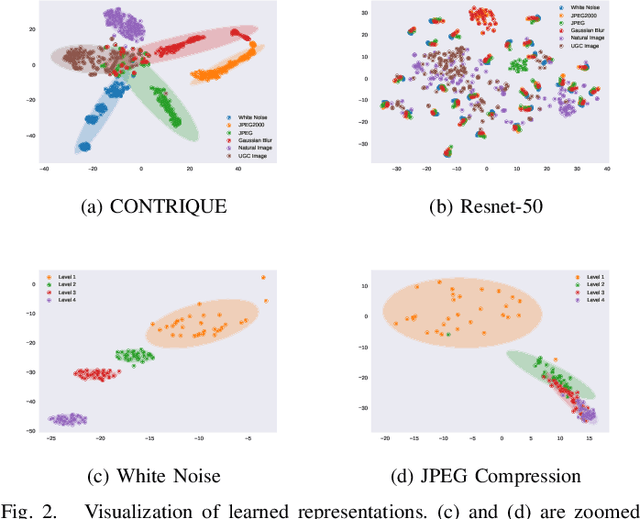
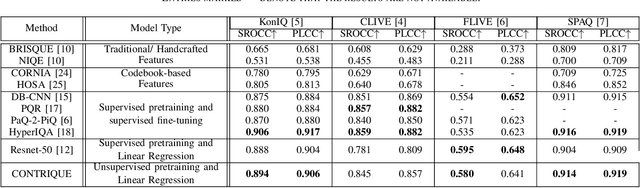
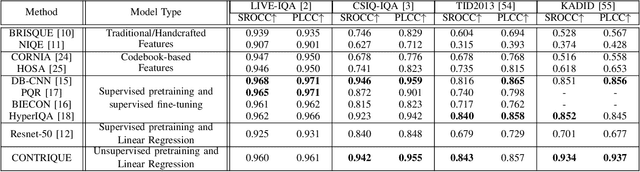
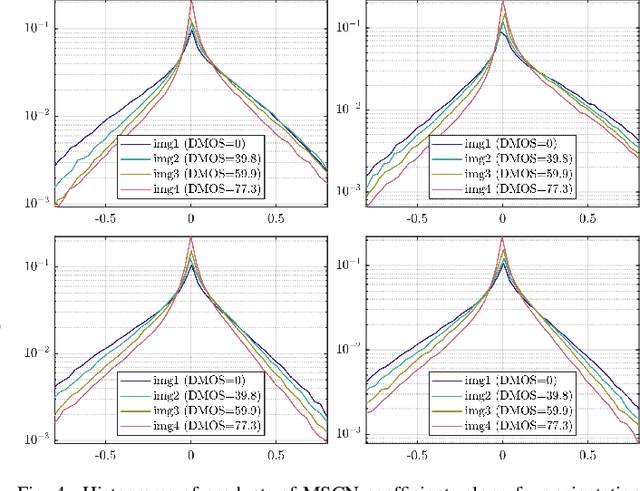
We consider the problem of obtaining image quality representations in a self-supervised manner. We use prediction of distortion type and degree as an auxiliary task to learn features from an unlabeled image dataset containing a mixture of synthetic and realistic distortions. We then train a deep Convolutional Neural Network (CNN) using a contrastive pairwise objective to solve the auxiliary problem. We refer to the proposed training framework and resulting deep IQA model as the CONTRastive Image QUality Evaluator (CONTRIQUE). During evaluation, the CNN weights are frozen and a linear regressor maps the learned representations to quality scores in a No-Reference (NR) setting. We show through extensive experiments that CONTRIQUE achieves competitive performance when compared to state-of-the-art NR image quality models, even without any additional fine-tuning of the CNN backbone. The learned representations are highly robust and generalize well across images afflicted by either synthetic or authentic distortions. Our results suggest that powerful quality representations with perceptual relevance can be obtained without requiring large labeled subjective image quality datasets. The implementations used in this paper are available at \url{https://github.com/pavancm/CONTRIQUE}.
ST-GREED: Space-Time Generalized Entropic Differences for Frame Rate Dependent Video Quality Prediction
Oct 26, 2020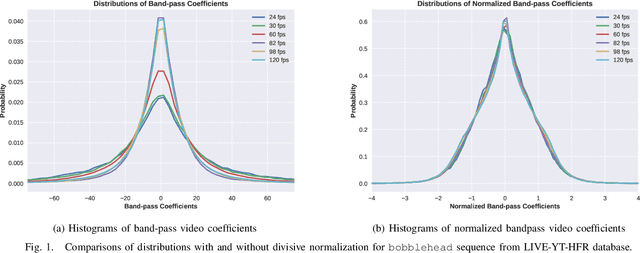
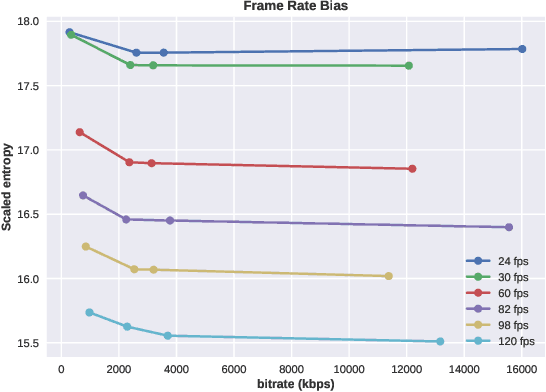
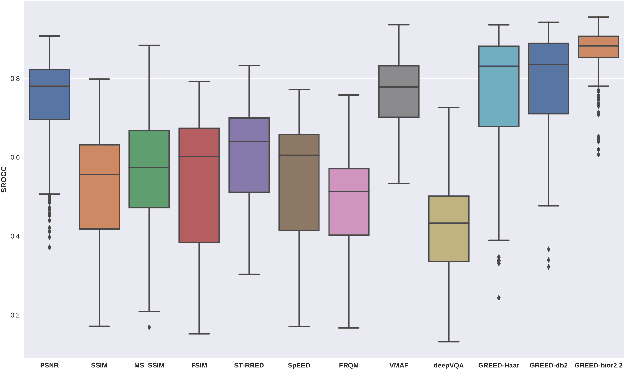
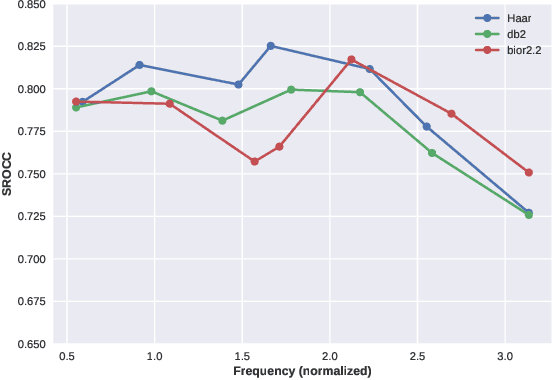
We consider the problem of conducting frame rate dependent video quality assessment (VQA) on videos of diverse frame rates, including high frame rate (HFR) videos. More generally, we study how perceptual quality is affected by frame rate, and how frame rate and compression combine to affect perceived quality. We devise an objective VQA model called Space-Time GeneRalized Entropic Difference (GREED) which analyzes the statistics of spatial and temporal band-pass video coefficients. A generalized Gaussian distribution (GGD) is used to model band-pass responses, while entropy variations between reference and distorted videos under the GGD model are used to capture video quality variations arising from frame rate changes. The entropic differences are calculated across multiple temporal and spatial subbands, and merged using a learned regressor. We show through extensive experiments that GREED achieves state-of-the-art performance on the LIVE-YT-HFR Database when compared with existing VQA models. The features used in GREED are highly generalizable and obtain competitive performance even on standard, non-HFR VQA databases. The implementation of GREED has been made available online: https://github.com/pavancm/GREED
Subjective and Objective Quality Assessment of High Frame Rate Videos
Jul 22, 2020
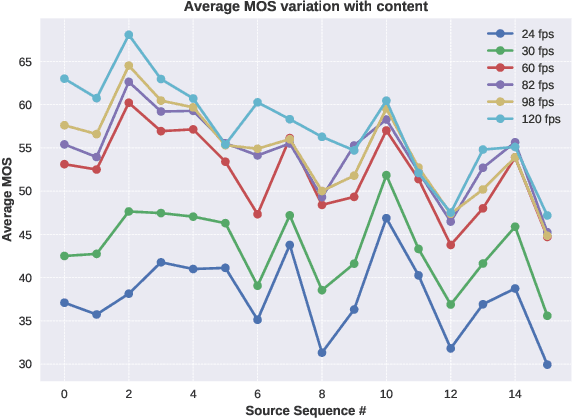
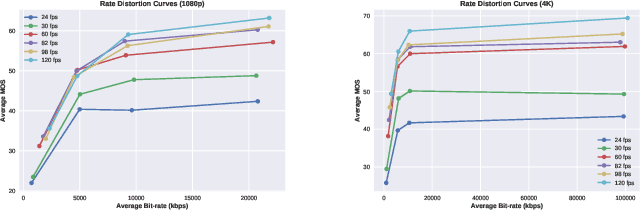
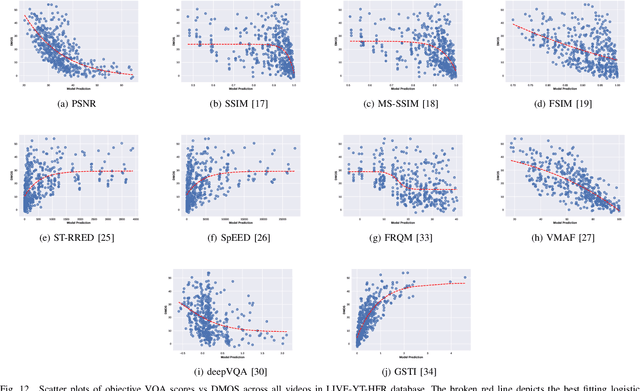
High frame rate (HFR) videos are becoming increasingly common with the tremendous popularity of live, high-action streaming content such as sports. Although HFR contents are generally of very high quality, high bandwidth requirements make them challenging to deliver efficiently, while simultaneously maintaining their quality. To optimize trade-offs between bandwidth requirements and video quality, in terms of frame rate adaptation, it is imperative to understand the intricate relationship between frame rate and perceptual video quality. Towards advancing progression in this direction we designed a new subjective resource, called the LIVE-YouTube-HFR (LIVE-YT-HFR) dataset, which is comprised of 480 videos having 6 different frame rates, obtained from 16 diverse contents. In order to understand the combined effects of compression and frame rate adjustment, we also processed videos at 5 compression levels at each frame rate. To obtain subjective labels on the videos, we conducted a human study yielding 19,000 human quality ratings obtained from a pool of 85 human subjects. We also conducted a holistic evaluation of existing state-of-the-art Full and No-Reference video quality algorithms, and statistically benchmarked their performance on the new database. The LIVE-YT-HFR database has been made available online for public use and evaluation purposes, with hopes that it will help advance research in this exciting video technology direction. It may be obtained at \url{https://live.ece.utexas.edu/research/LIVE_YT_HFR/LIVE_YT_HFR/index.html}
Capturing Video Frame Rate Variations through Entropic Differencing
Jun 19, 2020
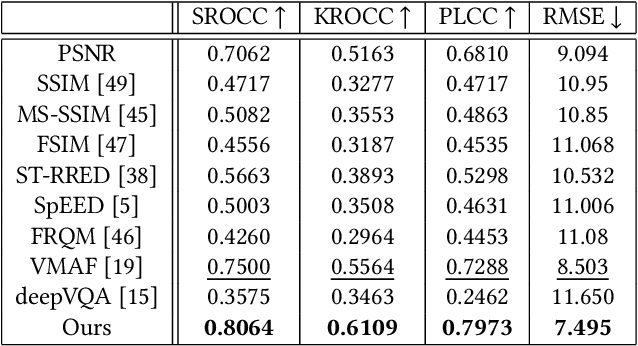
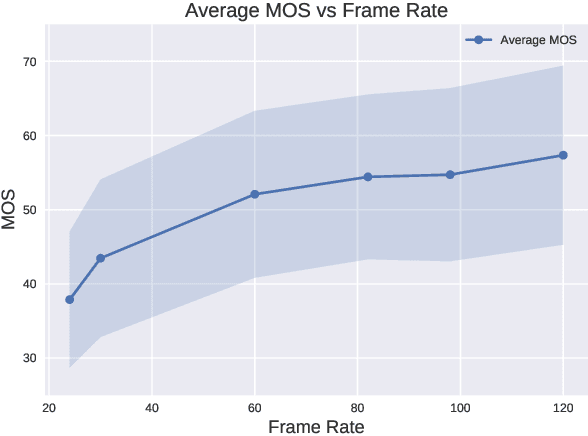

High frame rate videos are increasingly getting popular in recent years majorly driven by strong requirements by the entertainment and streaming industries to provide high quality of experiences to consumers. To achieve the best trade-off between the bandwidth requirements and video quality in terms of frame rate adaptation, it is imperative to understand the effects of frame rate on video quality. In this direction, we make two contributions: firstly we design a High Frame Rate (HFR) video database consisting of 480 videos and around 19,000 human quality ratings. We then devise a novel statistical entropic differencing method based on Generalized Gaussian Distribution model in spatial and temporal band-pass domain, which measures the difference in quality between the reference and distorted videos. The proposed design is highly generalizable and can be employed when the reference and distorted sequences have different frame rates, without any need of temporal upsampling. We show through extensive experiments that our model correlates very well with subjective scores in the HFR database and achieves state of the art performance when compared with existing methodologies.