 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumaFlux: Lifting 8-Bit Worlds to HDR Reality with Physically-Guided Diffusion Transformers
Apr 03, 2026The rapid adoption of HDR-capable devices has created a pressing need to convert the 8-bit Standard Dynamic Range (SDR) content into perceptually and physically accurate 10-bit High Dynamic Range (HDR). Existing inverse tone-mapping (ITM) methods often rely on fixed tone-mapping operators that struggle to generalize to real-world degradations, stylistic variations, and camera pipelines, frequently producing clipped highlights, desaturated colors, or unstable tone reproduction. We introduce LumaFlux, a first physically and perceptually guided diffusion transformer (DiT) for SDR-to-HDR reconstruction by adapting a large pretrained DiT. Our LumaFlux introduces (1) a Physically-Guided Adaptation (PGA) module that injects luminance, spatial descriptors, and frequency cues into attention through low-rank residuals; (2) a Perceptual Cross-Modulation (PCM) layer that stabilizes chroma and texture via FiLM conditioning from vision encoder features; and (3) an HDR Residual Coupler that fuses physical and perceptual signals under a timestep- and layer-adaptive modulation schedule. Finally, a lightweight Rational-Quadratic Spline decoder reconstructs smooth, interpretable tone fields for highlight and exposure expansion, enhancing the output of the VAE decoder to generate HDR. To enable robust HDR learning, we curate the first large-scale SDR-HDR training corpus. For fair and reproducible comparison, we further establish a new evaluation benchmark, comprising HDR references and corresponding expert-graded SDR versions. Across benchmarks, LumaFlux outperforms state-of-the-art baselines, achieving superior luminance reconstruction and perceptual color fidelity with minimal additional parameters.
Seeing Beyond 8bits: Subjective and Objective Quality Assessment of HDR-UGC Videos
Mar 01, 2026High Dynamic Range (HDR) user-generated (UGC) videos are rapidly proliferating across social platforms, yet most perceptual video quality assessment (VQA) systems remain tailored to Standard Dynamic Range (SDR). HDR has a higher bit depth, wide color gamut, and elevated luminance range, exposing distortions such as near-black crushing, highlight clipping, banding, and exposure flicker that amplify UGC artifacts and challenge SDR models. To catalyze progress, we curate Beyond8Bits, a large-scale subjective dataset of 44K videos from 6.5K sources with over 1.5M crowd ratings, spanning diverse scenes, capture conditions, and compression settings. We further introduce HDR-Q, the first Multimodal Large Language Model (MLLM) for HDR-UGC VQA. We propose (i) a novel HDR-aware vision encoder to produce HDR-sensitive embeddings, and (ii) HDR-Aware Policy Optimization (HAPO), an RL finetuning framework that anchors reasoning to HDR cues. HAPO augments GRPO via an HDR-SDR contrastive KL that encourages token reliance on HDR inputs and a Gaussian weighted regression reward for fine-grained MOS calibration. Across Beyond8Bits and public HDR-VQA benchmarks, HDR-Q delivers state-of-the-art performance.
Rate-Distortion Optimization for Ensembles of Non-Reference Metrics
Feb 17, 2026Non-reference metrics (NRMs) can assess the visual quality of images and videos without a reference, making them well-suited for the evaluation of user-generated content. Nonetheless, rate-distortion optimization (RDO) in video coding is still mainly driven by full-reference metrics, such as the sum of squared errors, which treat the input as an ideal target. A way to incorporate NRMs into RDO is through linearization (LNRM), where the gradient of the NRM with respect to the input guides bit allocation. While this strategy improves the quality predicted by some metrics, we show that it can yield limited gains or degradations when evaluated with other NRMs. We argue that NRMs are highly non-linear predictors with locally unstable gradients that can compromise the quality of the linearization; furthermore, optimizing a single metric may exploit model-specific biases that do not generalize across quality estimators. Motivated by this observation, we extend the LNRM framework to optimize ensembles of NRMs and, to further improve robustness, we introduce a smoothing-based formulation that stabilizes NRM gradients prior to linearization. Our framework is well-suited to hybrid codecs, and we advocate for its use with overfitted codecs, where it avoids iterative evaluations and backpropagation of neural network-based NRMs, reducing encoder complexity relative to direct NRM optimization. We validate the proposed approach on AVC and Cool-chic, using the YouTube UGC dataset. Experiments demonstrate consistent bitrate savings across multiple NRMs with no decoder complexity overhead and, for Cool-chic, a substantial reduction in encoding runtime compared to direct NRM optimization.
TABES: Trajectory-Aware Backward-on-Entropy Steering for Masked Diffusion Models
Jan 30, 2026Masked Diffusion Models (MDMs) have emerged as a promising non-autoregressive paradigm for generative tasks, offering parallel decoding and bidirectional context utilization. However, current sampling methods rely on simple confidence-based heuristics that ignore the long-term impact of local decisions, leading to trajectory lock-in where early hallucinations cascade into global incoherence. While search-based methods mitigate this, they incur prohibitive computational costs ($O(K)$ forward passes per step). In this work, we propose Backward-on-Entropy (BoE) Steering, a gradient-guided inference framework that approximates infinite-horizon lookahead via a single backward pass. We formally derive the Token Influence Score (TIS) from a first-order expansion of the trajectory cost functional, proving that the gradient of future entropy with respect to input embeddings serves as an optimal control signal for minimizing uncertainty. To ensure scalability, we introduce \texttt{ActiveQueryAttention}, a sparse adjoint primitive that exploits the structure of the masking objective to reduce backward pass complexity. BoE achieves a superior Pareto frontier for inference-time scaling compared to existing unmasking methods, demonstrating that gradient-guided steering offers a mathematically principled and efficient path to robust non-autoregressive generation. We will release the code.
CP-LLM: Context and Pixel Aware Large Language Model for Video Quality Assessment
May 21, 2025Video quality assessment (VQA) is a challenging research topic with broad applications. Effective VQA necessitates sensitivity to pixel-level distortions and a comprehensive understanding of video context to accurately determine the perceptual impact of distortions. Traditional hand-crafted and learning-based VQA models mainly focus on pixel-level distortions and lack contextual understanding, while recent LLM-based models struggle with sensitivity to small distortions or handle quality scoring and description as separate tasks. To address these shortcomings, we introduce CP-LLM: a Context and Pixel aware Large Language Model. CP-LLM is a novel multimodal LLM architecture featuring dual vision encoders designed to independently analyze perceptual quality at both high-level (video context) and low-level (pixel distortion) granularity, along with a language decoder subsequently reasons about the interplay between these aspects. This design enables CP-LLM to simultaneously produce robust quality scores and interpretable quality descriptions, with enhanced sensitivity to pixel distortions (e.g. compression artifacts). The model is trained via a multi-task pipeline optimizing for score prediction, description generation, and pairwise comparisons. Experiment results demonstrate that CP-LLM achieves state-of-the-art cross-dataset performance on established VQA benchmarks and superior robustness to pixel distortions, confirming its efficacy for comprehensive and practical video quality assessment in real-world scenarios.
Rate-Distortion Optimization with Non-Reference Metrics for UGC Compression
May 21, 2025Service providers must encode a large volume of noisy videos to meet the demand for user-generated content (UGC) in online video-sharing platforms. However, low-quality UGC challenges conventional codecs based on rate-distortion optimization (RDO) with full-reference metrics (FRMs). While effective for pristine videos, FRMs drive codecs to preserve artifacts when the input is degraded, resulting in suboptimal compression. A more suitable approach used to assess UGC quality is based on non-reference metrics (NRMs). However, RDO with NRMs as a measure of distortion requires an iterative workflow of encoding, decoding, and metric evaluation, which is computationally impractical. This paper overcomes this limitation by linearizing the NRM around the uncompressed video. The resulting cost function enables block-wise bit allocation in the transform domain by estimating the alignment of the quantization error with the gradient of the NRM. To avoid large deviations from the input, we add sum of squared errors (SSE) regularization. We derive expressions for both the SSE regularization parameter and the Lagrangian, akin to the relationship used for SSE-RDO. Experiments with images and videos show bitrate savings of more than 30\% over SSE-RDO using the target NRM, with no decoder complexity overhead and minimal encoder complexity increase.
An Ensemble Approach to Short-form Video Quality Assessment Using Multimodal LLM
Dec 24, 2024
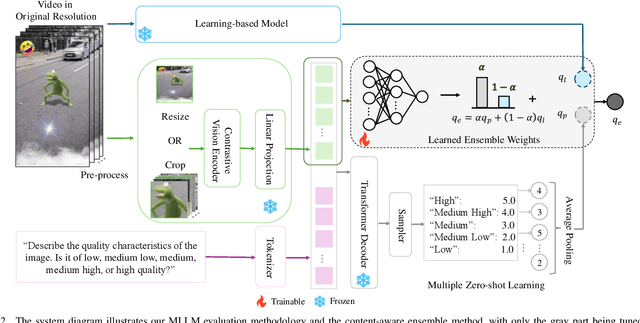
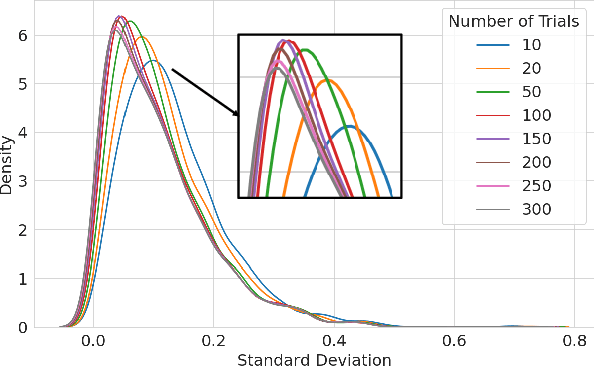

The rise of short-form videos, characterized by diverse content, editing styles, and artifacts, poses substantial challenges for learning-based blind video quality assessment (BVQA) models. Multimodal large language models (MLLMs), renowned for their superior generalization capabilities, present a promising solution. This paper focuses on effectively leveraging a pretrained MLLM for short-form video quality assessment, regarding the impacts of pre-processing and response variability, and insights on combining the MLLM with BVQA models. We first investigated how frame pre-processing and sampling techniques influence the MLLM's performance. Then, we introduced a lightweight learning-based ensemble method that adaptively integrates predictions from the MLLM and state-of-the-art BVQA models. Our results demonstrated superior generalization performance with the proposed ensemble approach. Furthermore, the analysis of content-aware ensemble weights highlighted that some video characteristics are not fully represented by existing BVQA models, revealing potential directions to improve BVQA models further.
YouTube SFV+HDR Quality Dataset
Jun 08, 2024
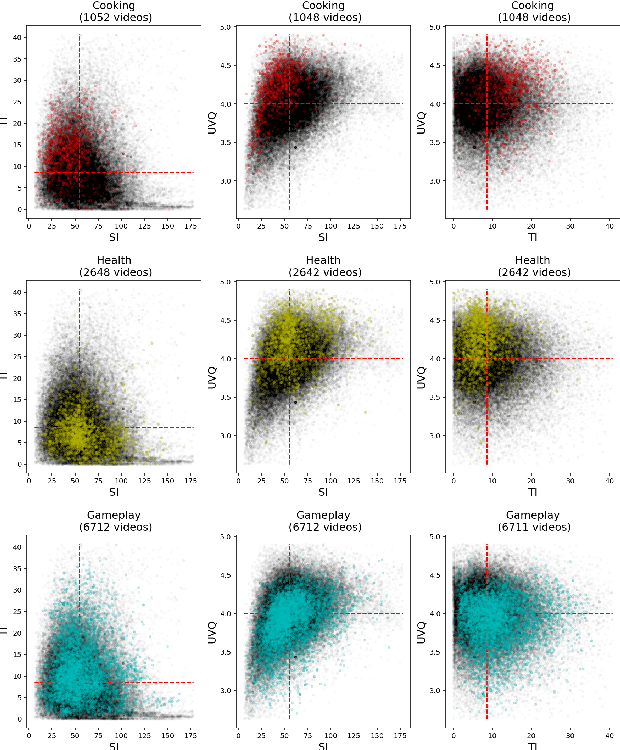


The popularity of Short form videos (SFV) has grown dramatically in the past few years, and has become a phenomenal video category with billions of viewers. Meanwhile, High Dynamic Range (HDR) as an advanced feature also becomes more and more popular on video sharing platforms. As a hot topic with huge impact, SFV and HDR bring new questions to video quality research: 1) is SFV+HDR quality assessment significantly different from traditional User Generated Content (UGC) quality assessment? 2) do objective quality metrics designed for traditional UGC still work well for SFV+HDR? To answer the above questions, we created the first large scale SFV+HDR dataset with reliable subjective quality scores, covering 10 popular content categories. Further, we also introduce a general sampling framework to maximize the representativeness of the dataset. We provided a comprehensive analysis of subjective quality scores for Short form SDR and HDR videos, and discuss the reliability of state-of-the-art UGC quality metrics and potential improvements.
Direct Optimisation of $\boldsymbolλ$ for HDR Content Adaptive Transcoding in AV1
Aug 23, 2022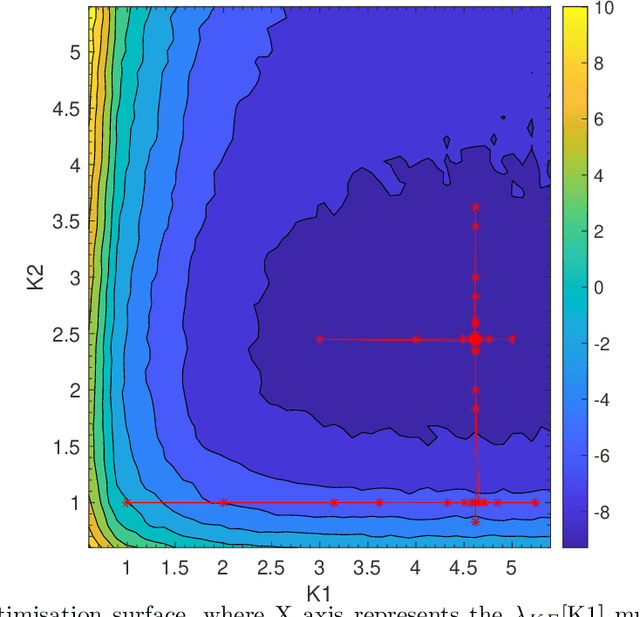



Since the adoption of VP9 by Netflix in 2016, royalty-free coding standards continued to gain prominence through the activities of the AOMedia consortium. AV1, the latest open source standard, is now widely supported. In the early years after standardisation, HDR video tends to be under served in open source encoders for a variety of reasons including the relatively small amount of true HDR content being broadcast and the challenges in RD optimisation with that material. AV1 codec optimisation has been ongoing since 2020 including consideration of the computational load. In this paper, we explore the idea of direct optimisation of the Lagrangian $\lambda$ parameter used in the rate control of the encoders to estimate the optimal Rate-Distortion trade-off achievable for a High Dynamic Range signalled video clip. We show that by adjusting the Lagrange multiplier in the RD optimisation process on a frame-hierarchy basis, we are able to increase the Bjontegaard difference rate gains by more than 3.98$\times$ on average without visually affecting the quality.
CONVIQT: Contrastive Video Quality Estimator
Jun 29, 2022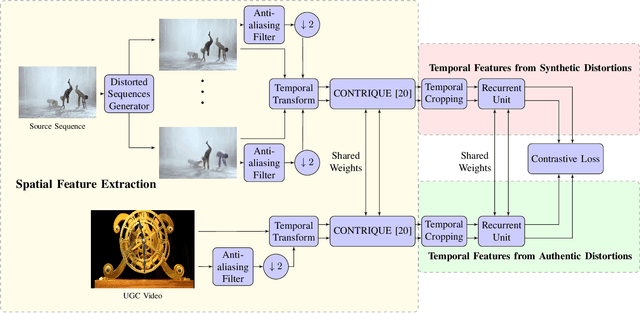
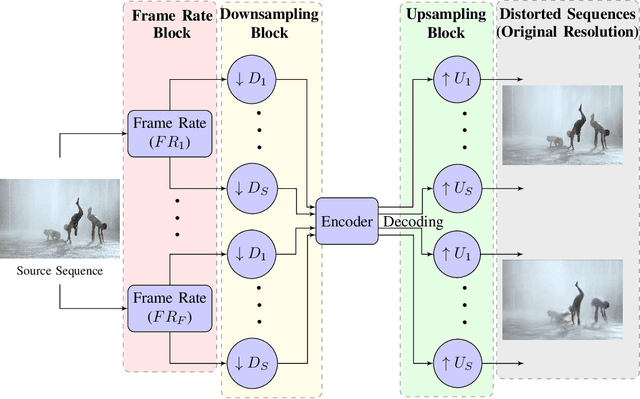


Perceptual video quality assessment (VQA) is an integral component of many streaming and video sharing platforms. Here we consider the problem of learning perceptually relevant video quality representations in a self-supervised manner. Distortion type identification and degradation level determination is employed as an auxiliary task to train a deep learning model containing a deep Convolutional Neural Network (CNN) that extracts spatial features, as well as a recurrent unit that captures temporal information. The model is trained using a contrastive loss and we therefore refer to this training framework and resulting model as CONtrastive VIdeo Quality EstimaTor (CONVIQT). During testing, the weights of the trained model are frozen, and a linear regressor maps the learned features to quality scores in a no-reference (NR) setting. We conduct comprehensive evaluations of the proposed model on multiple VQA databases by analyzing the correlations between model predictions and ground-truth quality ratings, and achieve competitive performance when compared to state-of-the-art NR-VQA models, even though it is not trained on those databases. Our ablation experiments demonstrate that the learned representations are highly robust and generalize well across synthetic and realistic distortions. Our results indicate that compelling representations with perceptual bearing can be obtained using self-supervised learning. The implementations used in this work have been made available at https://github.com/pavancm/CONVIQT.