 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Drift-Aware Predictive Transfer: Toward Durable Clinical AI
Jan 21, 2026Clinical AI systems frequently suffer performance decay post-deployment due to temporal data shifts, such as evolving populations, diagnostic coding updates (e.g., ICD-9 to ICD-10), and systemic shocks like the COVID-19 pandemic. Addressing this ``aging'' effect via frequent retraining is often impractical due to computational costs and privacy constraints. To overcome these hurdles, we introduce Adversarial Drift-Aware Predictive Transfer (ADAPT), a novel framework designed to confer durability against temporal drift with minimal retraining. ADAPT innovatively constructs an uncertainty set of plausible future models by combining historical source models and limited current data. By optimizing worst-case performance over this set, it balances current accuracy with robustness against degradation due to future drifts. Crucially, ADAPT requires only summary-level model estimators from historical periods, preserving data privacy and ensuring operational simplicity. Validated on longitudinal suicide risk prediction using electronic health records from Mass General Brigham (2005--2021) and Duke University Health Systems, ADAPT demonstrated superior stability across coding transitions and pandemic-induced shifts. By minimizing annual performance decay without labeling or retraining future data, ADAPT offers a scalable pathway for sustaining reliable AI in high-stakes healthcare environments.
Rate-Distortion Optimization with Non-Reference Metrics for UGC Compression
May 21, 2025Service providers must encode a large volume of noisy videos to meet the demand for user-generated content (UGC) in online video-sharing platforms. However, low-quality UGC challenges conventional codecs based on rate-distortion optimization (RDO) with full-reference metrics (FRMs). While effective for pristine videos, FRMs drive codecs to preserve artifacts when the input is degraded, resulting in suboptimal compression. A more suitable approach used to assess UGC quality is based on non-reference metrics (NRMs). However, RDO with NRMs as a measure of distortion requires an iterative workflow of encoding, decoding, and metric evaluation, which is computationally impractical. This paper overcomes this limitation by linearizing the NRM around the uncompressed video. The resulting cost function enables block-wise bit allocation in the transform domain by estimating the alignment of the quantization error with the gradient of the NRM. To avoid large deviations from the input, we add sum of squared errors (SSE) regularization. We derive expressions for both the SSE regularization parameter and the Lagrangian, akin to the relationship used for SSE-RDO. Experiments with images and videos show bitrate savings of more than 30\% over SSE-RDO using the target NRM, with no decoder complexity overhead and minimal encoder complexity increase.
Representation Learning to Advance Multi-institutional Studies with Electronic Health Record Data
Feb 12, 2025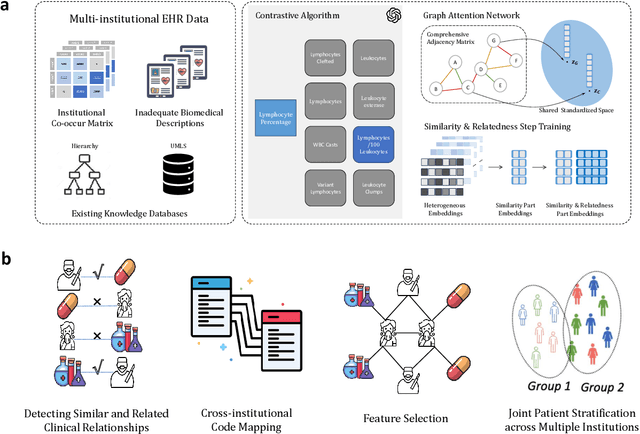
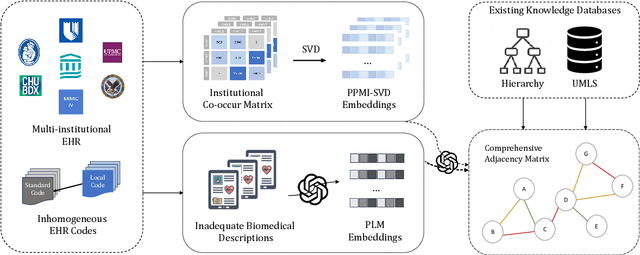

The adoption of EHRs has expanded opportunities to leverage data-driven algorithms in clinical care and research. A major bottleneck in effectively conducting multi-institutional EHR studies is the data heterogeneity across systems with numerous codes that either do not exist or represent different clinical concepts across institutions. The need for data privacy further limits the feasibility of including multi-institutional patient-level data required to study similarities and differences across patient subgroups. To address these challenges, we developed the GAME algorithm. Tested and validated across 7 institutions and 2 languages, GAME integrates data in several levels: (1) at the institutional level with knowledge graphs to establish relationships between codes and existing knowledge sources, providing the medical context for standard codes and their relationship to each other; (2) between institutions, leveraging language models to determine the relationships between institution-specific codes with established standard codes; and (3) quantifying the strength of the relationships between codes using a graph attention network. Jointly trained embeddings are created using transfer and federated learning to preserve data privacy. In this study, we demonstrate the applicability of GAME in selecting relevant features as inputs for AI-driven algorithms in a range of conditions, e.g., heart failure, rheumatoid arthritis. We then highlight the application of GAME harmonized multi-institutional EHR data in a study of Alzheimer's disease outcomes and suicide risk among patients with mental health disorders, without sharing patient-level data outside individual institutions.
Federated One-Shot Ensemble Clustering
Sep 12, 2024Cluster analysis across multiple institutions poses significant challenges due to data-sharing restrictions. To overcome these limitations, we introduce the Federated One-shot Ensemble Clustering (FONT) algorithm, a novel solution tailored for multi-site analyses under such constraints. FONT requires only a single round of communication between sites and ensures privacy by exchanging only fitted model parameters and class labels. The algorithm combines locally fitted clustering models into a data-adaptive ensemble, making it broadly applicable to various clustering techniques and robust to differences in cluster proportions across sites. Our theoretical analysis validates the effectiveness of the data-adaptive weights learned by FONT, and simulation studies demonstrate its superior performance compared to existing benchmark methods. We applied FONT to identify subgroups of patients with rheumatoid arthritis across two health systems, revealing improved consistency of patient clusters across sites, while locally fitted clusters proved less transferable. FONT is particularly well-suited for real-world applications with stringent communication and privacy constraints, offering a scalable and practical solution for multi-site clustering.
AdaAugment: A Tuning-Free and Adaptive Approach to Enhance Data Augmentation
May 23, 2024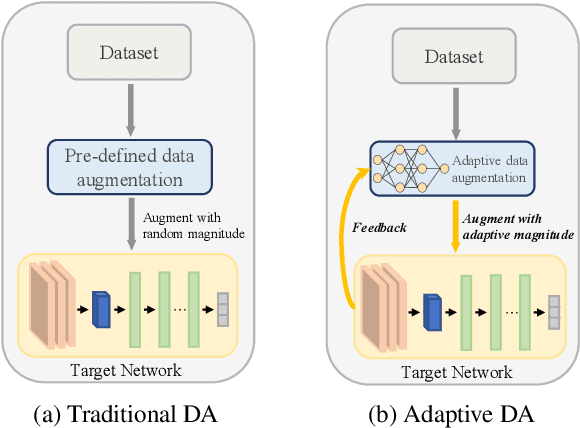

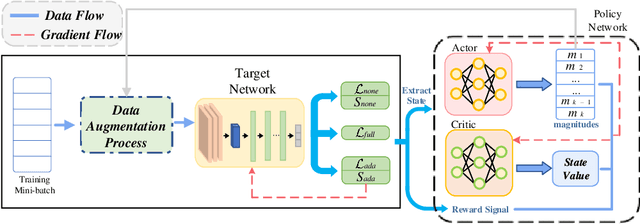

Data augmentation (DA) is widely employed to improve the generalization performance of deep models. However, most existing DA methods use augmentation operations with random magnitudes throughout training. While this fosters diversity, it can also inevitably introduce uncontrolled variability in augmented data, which may cause misalignment with the evolving training status of the target models. Both theoretical and empirical findings suggest that this misalignment increases the risks of underfitting and overfitting. To address these limitations, we propose AdaAugment, an innovative and tuning-free Adaptive Augmentation method that utilizes reinforcement learning to dynamically adjust augmentation magnitudes for individual training samples based on real-time feedback from the target network. Specifically, AdaAugment features a dual-model architecture consisting of a policy network and a target network, which are jointly optimized to effectively adapt augmentation magnitudes. The policy network optimizes the variability within the augmented data, while the target network utilizes the adaptively augmented samples for training. Extensive experiments across benchmark datasets and deep architectures demonstrate that AdaAugment consistently outperforms other state-of-the-art DA methods in effectiveness while maintaining remarkable efficiency.
Spatiotemporal Disentanglement of Arteriovenous Malformations in Digital Subtraction Angiography
Feb 15, 2024Although Digital Subtraction Angiography (DSA) is the most important imaging for visualizing cerebrovascular anatomy, its interpretation by clinicians remains difficult. This is particularly true when treating arteriovenous malformations (AVMs), where entangled vasculature connecting arteries and veins needs to be carefully identified.The presented method aims to enhance DSA image series by highlighting critical information via automatic classification of vessels using a combination of two learning models: An unsupervised machine learning method based on Independent Component Analysis that decomposes the phases of flow and a convolutional neural network that automatically delineates the vessels in image space. The proposed method was tested on clinical DSA images series and demonstrated efficient differentiation between arteries and veins that provides a viable solution to enhance visualizations for clinical use.
Distributionally Robust Transfer Learning
Sep 12, 2023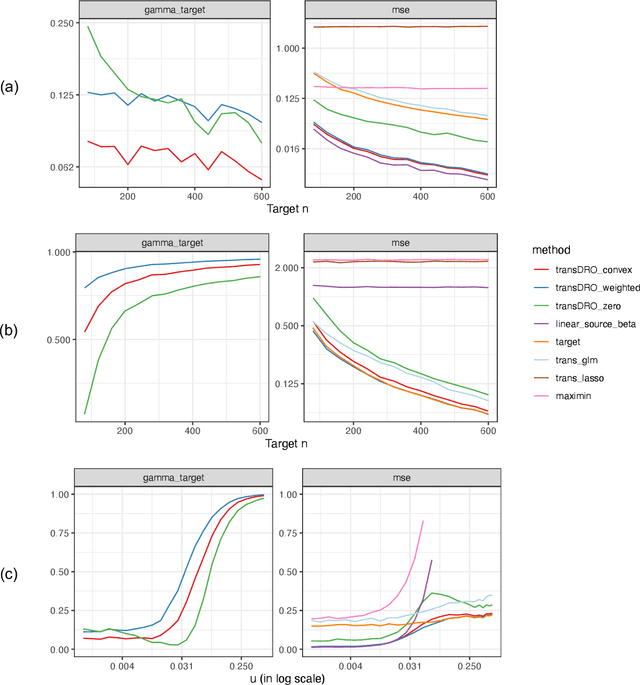
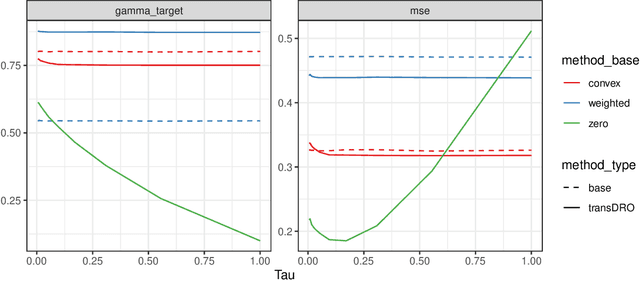
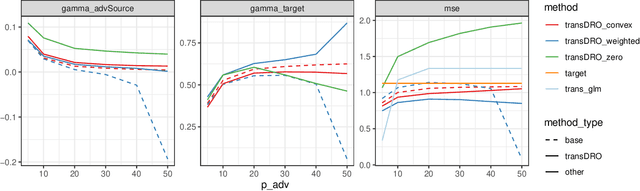
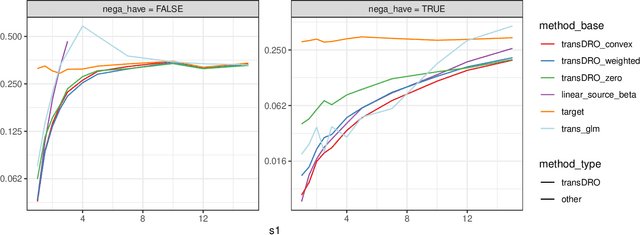
Many existing transfer learning methods rely on leveraging information from source data that closely resembles the target data. However, this approach often overlooks valuable knowledge that may be present in different yet potentially related auxiliary samples. When dealing with a limited amount of target data and a diverse range of source models, our paper introduces a novel approach, Distributionally Robust Optimization for Transfer Learning (TransDRO), that breaks free from strict similarity constraints. TransDRO is designed to optimize the most adversarial loss within an uncertainty set, defined as a collection of target populations generated as a convex combination of source distributions that guarantee excellent prediction performances for the target data. TransDRO effectively bridges the realms of transfer learning and distributional robustness prediction models. We establish the identifiability of TransDRO and its interpretation as a weighted average of source models closest to the baseline model. We also show that TransDRO achieves a faster convergence rate than the model fitted with the target data. Our comprehensive numerical studies and analysis of multi-institutional electronic health records data using TransDRO further substantiate the robustness and accuracy of TransDRO, highlighting its potential as a powerful tool in transfer learning applications.
GIMM: InfoMin-Max for Automated Graph Contrastive Learning
May 27, 2023Graph contrastive learning (GCL) shows great potential in unsupervised graph representation learning. Data augmentation plays a vital role in GCL, and its optimal choice heavily depends on the downstream task. Many GCL methods with automated data augmentation face the risk of insufficient information as they fail to preserve the essential information necessary for the downstream task. To solve this problem, we propose InfoMin-Max for automated Graph contrastive learning (GIMM), which prevents GCL from encoding redundant information and losing essential information. GIMM consists of two major modules: (1) automated graph view generator, which acquires the approximation of InfoMin's optimal views through adversarial training without requiring task-relevant information; (2) view comparison, which learns an excellent encoder by applying InfoMax to view representations. To the best of our knowledge, GIMM is the first method that combines the InfoMin and InfoMax principles in GCL. Besides, GIMM introduces randomness to augmentation, thus stabilizing the model against perturbations. Extensive experiments on unsupervised and semi-supervised learning for node and graph classification demonstrate the superiority of our GIMM over state-of-the-art GCL methods with automated and manual data augmentation.
Rate-Distortion Optimization With Alternative References For UGC Video Compression
Mar 11, 2023

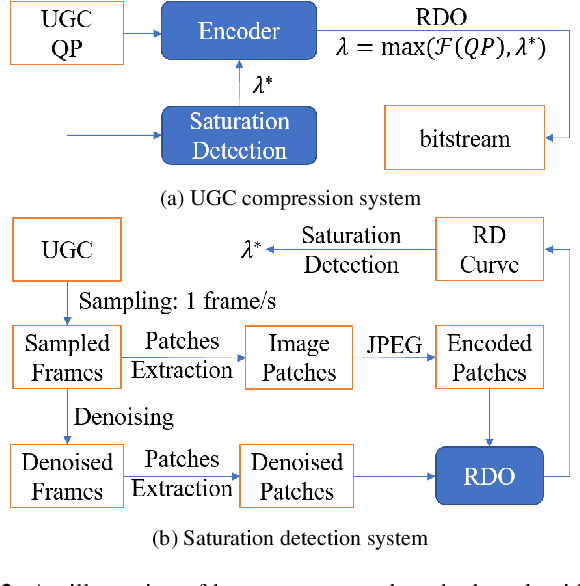

User generated content (UGC) refers to videos that are uploaded by users and shared over the Internet. UGC may have low quality due to noise and previous compression. When re-encoding UGC for streaming or downloading, a traditional video coding pipeline will perform rate-distortion (RD) optimization to choose coding parameters. However, in the UGC video coding case, since the input is not pristine, quality ``saturation'' (or even degradation) can be observed, i.e., increased bitrate only leads to improved representation of coding artifacts and noise present in the UGC input. In this paper, we study the saturation problem in UGC compression, where the goal is to identify and avoid during encoding, the coding parameters and rates that lead to quality saturation. We proposed a geometric criterion for saturation detection that works with rate-distortion optimization, and only requires a few frames from the UGC video. In addition, we show how to combine the proposed saturation detection method with existing video coding systems that implement rate-distortion optimization for efficient compression of UGC videos.
Compression of user generated content using denoised references
Mar 07, 2022
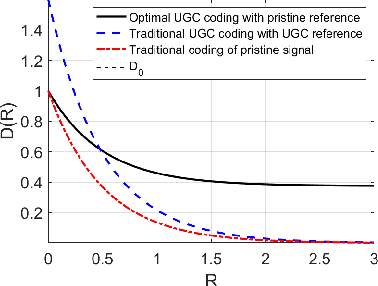
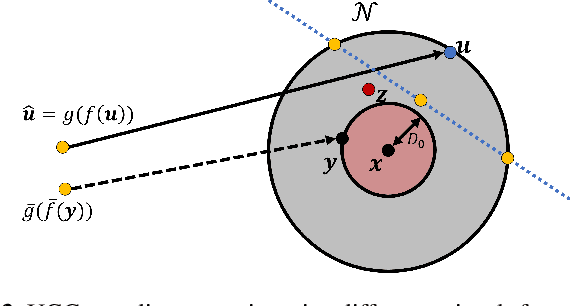

Video shared over the internet is commonly referred to as user generated content (UGC). UGC video may have low quality due to various factors including previous compression. UGC video is uploaded by users, and then it is re encoded to be made available at various levels of quality and resolution. In a traditional video coding pipeline the encoder parameters are optimized to minimize a rate-distortion criteria, but when the input signal has low quality, this results in sub-optimal coding parameters optimized to preserve undesirable artifacts. In this paper we formulate the UGC compression problem as that of compression of a noisy/corrupted source. The noisy source coding theorem reveals that an optimal UGC compression system is comprised of optimal denoising of the UGC signal, followed by compression of the denoised signal. Since optimal denoising is unattainable and users may be against modification of their content, we propose using denoised references to compute distortion, so the encoding process can be guided towards perceptually better solutions. We demonstrate the effectiveness of the proposed strategy for JPEG compression of UGC images and videos.