 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaAugment: A Tuning-Free and Adaptive Approach to Enhance Data Augmentation
Paper and Code
May 23, 2024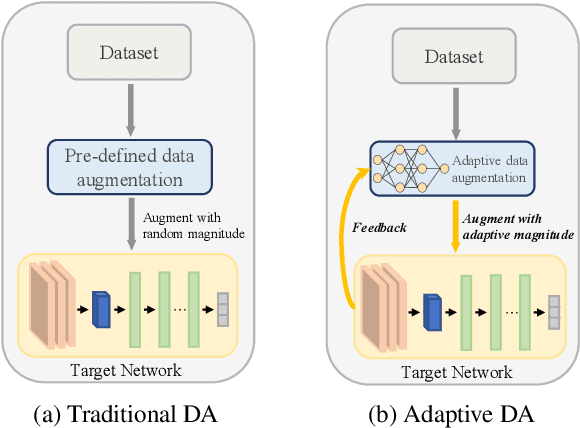

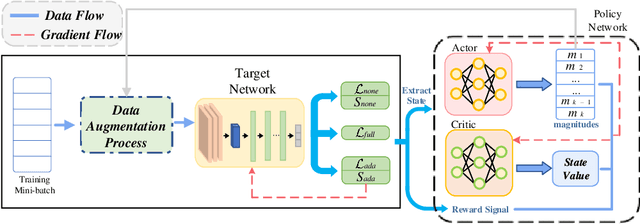

Data augmentation (DA) is widely employed to improve the generalization performance of deep models. However, most existing DA methods use augmentation operations with random magnitudes throughout training. While this fosters diversity, it can also inevitably introduce uncontrolled variability in augmented data, which may cause misalignment with the evolving training status of the target models. Both theoretical and empirical findings suggest that this misalignment increases the risks of underfitting and overfitting. To address these limitations, we propose AdaAugment, an innovative and tuning-free Adaptive Augmentation method that utilizes reinforcement learning to dynamically adjust augmentation magnitudes for individual training samples based on real-time feedback from the target network. Specifically, AdaAugment features a dual-model architecture consisting of a policy network and a target network, which are jointly optimized to effectively adapt augmentation magnitudes. The policy network optimizes the variability within the augmented data, while the target network utilizes the adaptively augmented samples for training. Extensive experiments across benchmark datasets and deep architectures demonstrate that AdaAugment consistently outperforms other state-of-the-art DA methods in effectiveness while maintaining remarkable efficiency.