 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedirecting the Flow: Image Customization through Attention Distribution Shift
Jun 15, 2026Subject-driven image customization aims to generate images that not only follow textual instructions but also preserve the identity of a given reference subject. Existing approaches, including test-time fine-tuning, encoder-based methods, and token competition in shared attention spaces, suffer from limited efficiency, misalignment between extracted reference features and the generative process, and interference from irrelevant information. To address these limitations, we formulate the customization task as a distribution shift induced by incorporating reference images into text-to-image generation, and derive a Conditional Attention Distribution Shift formulation grounded in maximum entropy theory. Building on this formulation, we propose CustomShift, a dual-branch architecture based on Stable Diffusion 3. The Reference-Alignment Branch leverages self-attention between reference images and subject names to achieve layer-wise alignment with latent representations, while the Cross-Guidance Branch integrates textual and reference cues to guide generation. Experiments on the DreamBooth and Custom101 benchmarks demonstrate that our method consistently outperforms state-of-the-art approaches, achieving a better balance between semantic fidelity and subject consistency.
A Geometric Measure of Linear Separability for Neural Representations
Jun 07, 2026Modern neural classifiers commonly rely on linear readouts, yet predictive metrics alone do not characterize the class-wise geometry of the representations on which such readouts operate. We introduce the directional linear separability measure (LSM), a finite-sample diagnostic for one-sided affine separability. For a target class A and a competing set B, LSM searches over affine halfspaces that contain all samples in A and measures the smallest competing-sample intrusion that must remain on the target side, normalized by |A|. The resulting quantity is asymmetric, class-wise, target-normalized, and applicable to finite representations extracted from neural networks. We establish its supporting-hyperplane characterization, relate it to optimal affine classification accuracy, and prove invariance under full-rank linear embeddings. These results separate changes caused by linear reparameterization from those caused by information loss or nonlinear geometric transformations. We also give a penalty-based affine search for estimating class-wise LSM in high-dimensional features, with reported values computed from the original discrete preservation and violation criterion. Finally, we analyze coordinatewise gated nonlinearities as finite-sample geometric operators and empirically use LSM to diagnose class-wise intrusion across common deep-learning components and architectures.
Beyond What to Select: A Plug-and-play Oscillatory Data-Volume Scheduling for Efficient Model Training
May 14, 2026Data selection accelerates training by identifying representative training data while preserving model performance. However, existing methods mainly focus on designing sample-importance criteria, i.e., deciding what to select, while typically fixing the selected data volume as the target ratio throughout training. Thus, they are often dynamic in sample identity but static in data volume. In this work, we revisit data selection from an optimization perspective and show that selected-data training induces an implicit regularization effect modulated by the instantaneous selection ratio. This reveals a key trade-off: lower ratios amplify selection-induced regularization, whereas higher ratios preserve data coverage and optimization fidelity. Motivated by this insight, we propose PODS, a Plug-and-play Oscillatory Data-volume Scheduling framework. Rather than introducing another sample-scoring metric, PODS serves as a lightweight module that dynamically schedules how much data to select over training. Under the target selection ratio, PODS alternates between low-ratio regularization phases and high-ratio recovery phases to exploit selection-induced regularization without sacrificing optimization stability. With its lightweight, ratio-level, and task-agnostic design, PODS is compatible with existing static and dynamic selection methods and broadly applicable across training paradigms. Experiments across various datasets, architectures, and tasks show that PODS consistently improves the efficiency-generalization trade-off, e.g., reducing ImageNet-1k training cost by 50% with improved accuracy and accelerating LLM instruction tuning by over 2x without performance degradation.
Beyond Point-wise Neural Collapse: A Topology-Aware Hierarchical Classifier for Class-Incremental Learning
May 12, 2026The Nearest Class Mean (NCM) classifier is widely favored in Class-Incremental Learning (CIL) for its superior resistance to catastrophic forgetting compared to Fully Connected layers. While Neural Collapse (NC) theory supports NCM's optimality by assuming features collapse into single points, non-linear feature drift and insufficient training in CIL often prevent this ideal state. Consequently, classes manifest as complex manifolds rather than collapsed points, rendering the single-point NCM suboptimal. To address this, we propose Hierarchical-Cluster SOINN (HC-SOINN), a novel classifier that captures the topological structure of these manifolds via a ``local-to-global'' representation. Furthermore, we introduce Structure-Topology Alignment via Residuals (STAR) method, which employs a fine-grained pointwise trajectory tracking mechanism to actively deform the learned topology, allowing it to adapt precisely to complex non-linear feature drift. Theoretical analysis and Procrustes distance experiments validate our framework's resilience to manifold deformations. We integrated HC-SOINN into seven state-of-the-art methods by replacing their original classifiers, achieving consistent improvements that highlight the effectiveness and robustness of our approach. Code is available at https://github.com/yhyet/HC_SOINN.
Region Seeding via Pre-Activation Regularization: A Geometric View from Piecewise Affine Nerual Networks
May 07, 2026Deep networks with continuous piecewise affine activations induce polyhedral partitions of the input space, making the number of realized affine regions a natural measure of expressive capacity and a key determinant of how well the model can approximate nonlinear target functions. In practice, standard training realizes far fewer region refinements in data-visited neighborhoods than the architecture could in principle support, while existing region-count theory is primarily architectural and offers little guidance on how optimization shapes the realized partition near the data. Our theory provides a sufficient condition under which bringing neuron switching surfaces sufficiently close to data points ensures their intersection with local neighborhoods, which in turn implies a strict increase in the local affine-region count, yielding a principled training-time handle for seeding data-relevant partitions early in optimization. Guided by these results, we propose a plug-and-play region-seeding regularizer that encourages early partitioning while allowing task-driven refinement to dominate later in training. Experiments show that the regularizer increases the number of realized affine regions via exact enumeration and improves overall performance on toy datasets, while also improving early-stage accuracy and achieving comparable (or slightly improved) final accuracy on ImageNet-1k for classical models.
Towards Realistic Class-Incremental Learning with Free-Flow Increments
Apr 03, 2026Class-incremental learning (CIL) is typically evaluated under predefined schedules with equal-sized tasks, leaving more realistic and complex cases unexplored. However, a practical CIL system should learns immediately when any number of new classes arrive, without forcing fixed-size tasks. We formalize this setting as Free-Flow Class-Incremental Learning (FFCIL), where data arrives as a more realistic stream with a highly variable number of unseen classes each step. It will make many existing CIL methods brittle and lead to clear performance degradation. We propose a model-agnostic framework for robust CIL learning under free-flow arrivals. It comprises a class-wise mean (CWM) objective that replaces sample frequency weighted loss with uniformly aggregated class-conditional supervision, thereby stabilizing the learning signal across free-flow class increments, as well as method-wise adjustments that improve robustness for representative CIL paradigms. Specifically, we constrain distillation to replayed data, normalize the scale of contrastive and knowledge transfer losses, and introduce Dynamic Intervention Weight Alignment (DIWA) to prevent over-adjustment caused by unstable statistics from small class increments. Experiments confirm a clear performance degradation across various CIL baselines under FFCIL, while our strategies yield consistent gains.
ScaleEnv: Scaling Environment Synthesis from Scratch for Generalist Interactive Tool-Use Agent Training
Feb 06, 2026Training generalist agents capable of adapting to diverse scenarios requires interactive environments for self-exploration. However, interactive environments remain critically scarce, and existing synthesis methods suffer from significant limitations regarding environmental diversity and scalability. To address these challenges, we introduce ScaleEnv, a framework that constructs fully interactive environments and verifiable tasks entirely from scratch. Specifically, ScaleEnv ensures environment reliability through procedural testing, and guarantees task completeness and solvability via tool dependency graph expansion and executable action verification. By enabling agents to learn through exploration within ScaleEnv, we demonstrate significant performance improvements on unseen, multi-turn tool-use benchmarks such as $τ^2$-Bench and VitaBench, highlighting strong generalization capabilities. Furthermore, we investigate the relationship between increasing number of domains and model generalization performance, providing empirical evidence that scaling environmental diversity is critical for robust agent learning.
T-LLM: Teaching Large Language Models to Forecast Time Series via Temporal Distillation
Feb 02, 2026Time series forecasting plays a critical role in decision-making across many real-world applications. Unlike data in vision and language domains, time series data is inherently tied to the evolution of underlying processes and can only accumulate as real-world time progresses, limiting the effectiveness of scale-driven pretraining alone. This time-bound constraint poses a challenge for enabling large language models (LLMs) to acquire forecasting capability, as existing approaches primarily rely on representation-level alignment or inference-time temporal modules rather than explicitly teaching forecasting behavior to the LLM. We propose T-LLM, a temporal distillation framework that equips general-purpose LLMs with time series forecasting capability by transferring predictive behavior from a lightweight temporal teacher during training. The teacher combines trend modeling and frequency-domain analysis to provide structured temporal supervision, and is removed entirely at inference, leaving the LLM as the sole forecasting model. Experiments on benchmark datasets and infectious disease forecasting tasks demonstrate that T-LLM consistently outperforms existing LLM-based forecasting methods under full-shot, few-shot, and zero-shot settings, while enabling a simple and efficient deployment pipeline.
MiCA: A Mobility-Informed Causal Adapter for Lightweight Epidemic Forecasting
Jan 16, 2026Accurate forecasting of infectious disease dynamics is critical for public health planning and intervention. Human mobility plays a central role in shaping the spatial spread of epidemics, but mobility data are noisy, indirect, and difficult to integrate reliably with disease records. Meanwhile, epidemic case time series are typically short and reported at coarse temporal resolution. These conditions limit the effectiveness of parameter-heavy mobility-aware forecasters that rely on clean and abundant data. In this work, we propose the Mobility-Informed Causal Adapter (MiCA), a lightweight and architecture-agnostic module for epidemic forecasting. MiCA infers mobility relations through causal discovery and integrates them into temporal forecasting models via gated residual mixing. This design allows lightweight forecasters to selectively exploit mobility-derived spatial structure while remaining robust under noisy and data-limited conditions, without introducing heavy relational components such as graph neural networks or full attention. Extensive experiments on four real-world epidemic datasets, including COVID-19 incidence, COVID-19 mortality, influenza, and dengue, show that MiCA consistently improves lightweight temporal backbones, achieving an average relative error reduction of 7.5\% across forecasting horizons. Moreover, MiCA attains performance competitive with SOTA spatio-temporal models while remaining lightweight.
RL-Selector: Reinforcement Learning-Guided Data Selection via Redundancy Assessment
Jun 26, 2025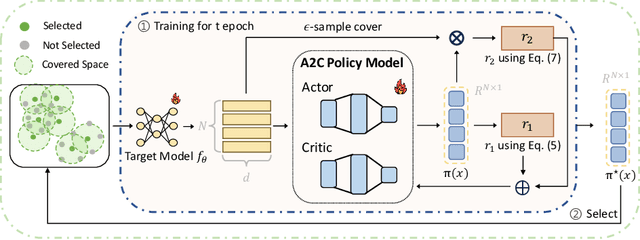
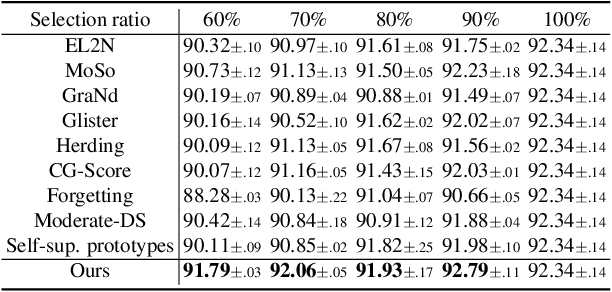
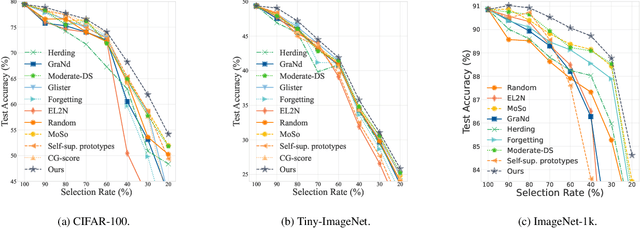
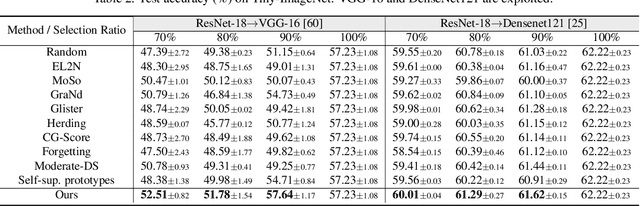
Modern deep architectures often rely on large-scale datasets, but training on these datasets incurs high computational and storage overhead. Real-world datasets often contain substantial redundancies, prompting the need for more data-efficient training paradigms. Data selection has shown promise to mitigate redundancy by identifying the most representative samples, thereby reducing training costs without compromising performance. Existing methods typically rely on static scoring metrics or pretrained models, overlooking the combined effect of selected samples and their evolving dynamics during training. We introduce the concept of epsilon-sample cover, which quantifies sample redundancy based on inter-sample relationships, capturing the intrinsic structure of the dataset. Based on this, we reformulate data selection as a reinforcement learning (RL) process and propose RL-Selector, where a lightweight RL agent optimizes the selection policy by leveraging epsilon-sample cover derived from evolving dataset distribution as a reward signal. Extensive experiments across benchmark datasets and diverse architectures demonstrate that our method consistently outperforms existing state-of-the-art baselines. Models trained with our selected datasets show enhanced generalization performance with improved training efficiency.
* ICCV 2025