 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELIQ: A Label-Free Framework for Quality Assessment of Evolving AI-Generated Images
Feb 03, 2026Generative text-to-image models are advancing at an unprecedented pace, continuously shifting the perceptual quality ceiling and rendering previously collected labels unreliable for newer generations. To address this, we present ELIQ, a Label-free Framework for Quality Assessment of Evolving AI-generated Images. Specifically, ELIQ focuses on visual quality and prompt-image alignment, automatically constructs positive and aspect-specific negative pairs to cover both conventional distortions and AIGC-specific distortion modes, enabling transferable supervision without human annotations. Building on these pairs, ELIQ adapts a pre-trained multimodal model into a quality-aware critic via instruction tuning and predicts two-dimensional quality using lightweight gated fusion and a Quality Query Transformer. Experiments across multiple benchmarks demonstrate that ELIQ consistently outperforms existing label-free methods, generalizes from AI-generated content (AIGC) to user-generated content (UGC) scenarios without modification, and paves the way for scalable and label-free quality assessment under continuously evolving generative models. The code will be released upon publication.
Decoupling Perception and Calibration: Label-Efficient Image Quality Assessment Framework
Jan 28, 2026Recent multimodal large language models (MLLMs) have demonstrated strong capabilities in image quality assessment (IQA) tasks. However, adapting such large-scale models is computationally expensive and still relies on substantial Mean Opinion Score (MOS) annotations. We argue that for MLLM-based IQA, the core bottleneck lies not in the quality perception capacity of MLLMs, but in MOS scale calibration. Therefore, we propose LEAF, a Label-Efficient Image Quality Assessment Framework that distills perceptual quality priors from an MLLM teacher into a lightweight student regressor, enabling MOS calibration with minimal human supervision. Specifically, the teacher conducts dense supervision through point-wise judgments and pair-wise preferences, with an estimate of decision reliability. Guided by these signals, the student learns the teacher's quality perception patterns through joint distillation and is calibrated on a small MOS subset to align with human annotations. Experiments on both user-generated and AI-generated IQA benchmarks demonstrate that our method significantly reduces the need for human annotations while maintaining strong MOS-aligned correlations, making lightweight IQA practical under limited annotation budgets.
Efficient Whisper on Streaming Speech
Dec 15, 2024



Speech foundation models, exemplified by OpenAI's Whisper, have emerged as leaders in speech understanding thanks to their exceptional accuracy and adaptability. However, their usage largely focuses on processing pre-recorded audio, with the efficient handling of streaming speech still in its infancy. Several core challenges underlie this limitation: (1) These models are trained for long, fixed-length audio inputs (typically 30 seconds). (2) Encoding such inputs involves processing up to 1,500 tokens through numerous transformer layers. (3) Generating outputs requires an irregular and computationally heavy beam search. Consequently, streaming speech processing on edge devices with constrained resources is more demanding than many other AI tasks, including text generation. To address these challenges, we introduce Whisper-T, an innovative framework combining both model and system-level optimizations: (1) Hush words, short learnable audio segments appended to inputs, prevent over-processing and reduce hallucinations in the model. (2) Beam pruning aligns streaming audio buffers over time, leveraging intermediate decoding results to significantly speed up the process. (3) CPU/GPU pipelining dynamically distributes resources between encoding and decoding stages, optimizing performance by adapting to variations in audio input, model characteristics, and hardware. We evaluate Whisper-T on ARM-based platforms with 4-12 CPU cores and 10-30 GPU cores, demonstrating latency reductions of 1.6x-4.7x, achieving per-word delays as low as 0.5 seconds with minimal accuracy loss. Additionally, on a MacBook Air, Whisper-T maintains approximately 1-second latency per word while consuming just 7 Watts of total system power.
Integrating Dual Prototypes for Task-Wise Adaption in Pre-Trained Model-Based Class-Incremental Learning
Nov 26, 2024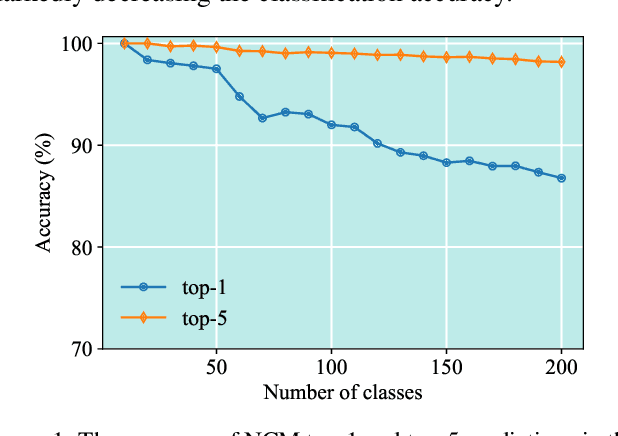
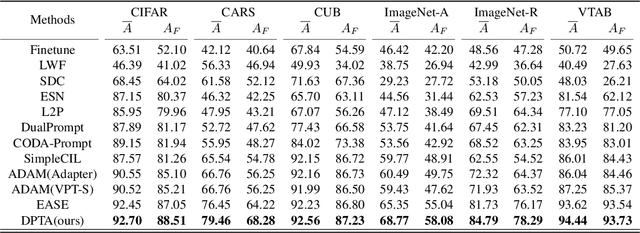
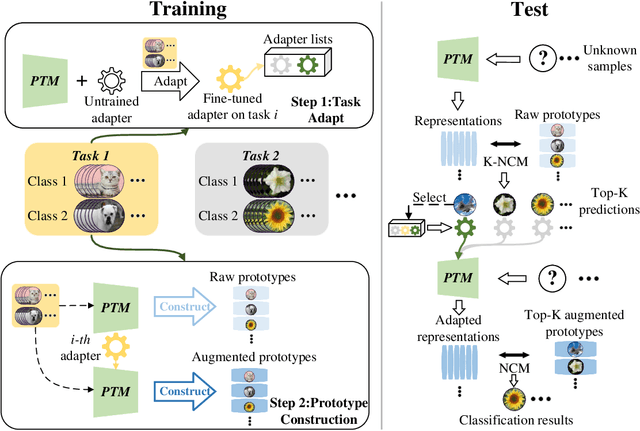
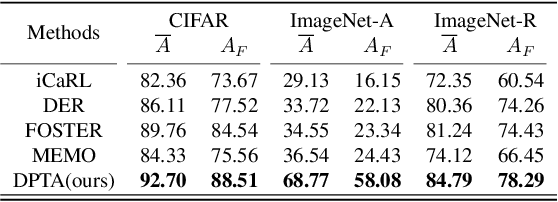
Class-incremental learning (CIL) aims to acquire new classes while conserving historical knowledge incrementally. Despite existing pre-trained model (PTM) based methods performing excellently in CIL, it is better to fine-tune them on downstream incremental tasks with massive patterns unknown to PTMs. However, using task streams for fine-tuning could lead to catastrophic forgetting that will erase the knowledge in PTMs. This paper proposes the Dual Prototype network for Task-wise Adaption (DPTA) of PTM-based CIL. For each incremental learning task, a task-wise adapter module is built to fine-tune the PTM, where the center-adapt loss forces the representation to be more centrally clustered and class separable. The dual prototype network improves the prediction process by enabling test-time adapter selection, where the raw prototypes deduce several possible task indexes of test samples to select suitable adapter modules for PTM, and the augmented prototypes that could separate highly correlated classes are utilized to determine the final result. Experiments on several benchmark datasets demonstrate the state-of-the-art performance of DPTA. The code will be open-sourced after the paper is published.
Leveraging cache to enable SLU on tiny devices
Nov 30, 2023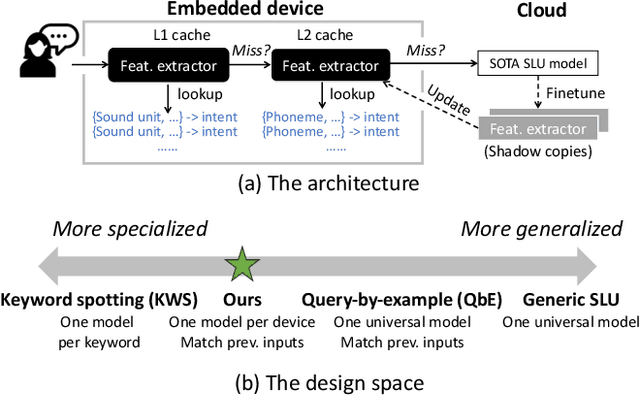
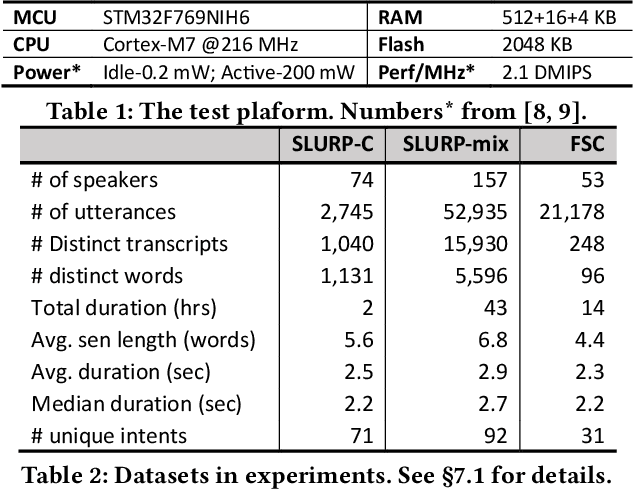
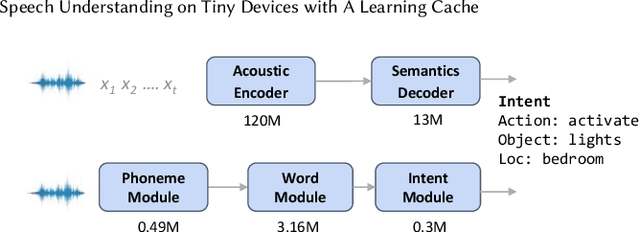
This paper addresses spoken language understanding (SLU) on microcontroller-like embedded devices, integrating on-device execution with cloud offloading in a novel fashion. We exploit temporal locality in a device's speech inputs and accordingly reuse recent SLU inferences. Our idea is simple: let the device match new inputs against cached results, and only offload unmatched inputs to the cloud for full inference. Realization of this idea, however, is non-trivial: the device needs to compare acoustic features in a robust, low-cost way. To this end, we present XYZ, a speech cache for tiny devices. It matches speech inputs at two levels of representations: first by clustered sequences of raw sound units, then as sequences of phonemes. Working in tandem, the two representations offer complementary cost/accuracy tradeoffs. To further boost accuracy, our cache is learning: with the mismatched and then offloaded inputs, it continuously finetunes the device's feature extractors (with the assistance of the cloud). We implement XYZ on an off-the-shelf STM32 microcontroller. The resultant implementation has a small memory footprint of 2MB. Evaluated on challenging speech benchmarks, our system resolves 45%--90% of inputs on device, reducing the average latency by up to 80% compared to offloading to popular cloud speech services. Our benefit is pronounced even in adversarial settings -- noisy environments, cold cache, or one device shared by a number of users.