 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Point-wise Neural Collapse: A Topology-Aware Hierarchical Classifier for Class-Incremental Learning
May 12, 2026The Nearest Class Mean (NCM) classifier is widely favored in Class-Incremental Learning (CIL) for its superior resistance to catastrophic forgetting compared to Fully Connected layers. While Neural Collapse (NC) theory supports NCM's optimality by assuming features collapse into single points, non-linear feature drift and insufficient training in CIL often prevent this ideal state. Consequently, classes manifest as complex manifolds rather than collapsed points, rendering the single-point NCM suboptimal. To address this, we propose Hierarchical-Cluster SOINN (HC-SOINN), a novel classifier that captures the topological structure of these manifolds via a ``local-to-global'' representation. Furthermore, we introduce Structure-Topology Alignment via Residuals (STAR) method, which employs a fine-grained pointwise trajectory tracking mechanism to actively deform the learned topology, allowing it to adapt precisely to complex non-linear feature drift. Theoretical analysis and Procrustes distance experiments validate our framework's resilience to manifold deformations. We integrated HC-SOINN into seven state-of-the-art methods by replacing their original classifiers, achieving consistent improvements that highlight the effectiveness and robustness of our approach. Code is available at https://github.com/yhyet/HC_SOINN.
Towards Realistic Class-Incremental Learning with Free-Flow Increments
Apr 03, 2026Class-incremental learning (CIL) is typically evaluated under predefined schedules with equal-sized tasks, leaving more realistic and complex cases unexplored. However, a practical CIL system should learns immediately when any number of new classes arrive, without forcing fixed-size tasks. We formalize this setting as Free-Flow Class-Incremental Learning (FFCIL), where data arrives as a more realistic stream with a highly variable number of unseen classes each step. It will make many existing CIL methods brittle and lead to clear performance degradation. We propose a model-agnostic framework for robust CIL learning under free-flow arrivals. It comprises a class-wise mean (CWM) objective that replaces sample frequency weighted loss with uniformly aggregated class-conditional supervision, thereby stabilizing the learning signal across free-flow class increments, as well as method-wise adjustments that improve robustness for representative CIL paradigms. Specifically, we constrain distillation to replayed data, normalize the scale of contrastive and knowledge transfer losses, and introduce Dynamic Intervention Weight Alignment (DIWA) to prevent over-adjustment caused by unstable statistics from small class increments. Experiments confirm a clear performance degradation across various CIL baselines under FFCIL, while our strategies yield consistent gains.
Physics-inspired Energy Transition Neural Network for Sequence Learning
May 06, 2025Recently, the superior performance of Transformers has made them a more robust and scalable solution for sequence modeling than traditional recurrent neural networks (RNNs). However, the effectiveness of Transformer in capturing long-term dependencies is primarily attributed to their comprehensive pair-modeling process rather than inherent inductive biases toward sequence semantics. In this study, we explore the capabilities of pure RNNs and reassess their long-term learning mechanisms. Inspired by the physics energy transition models that track energy changes over time, we propose a effective recurrent structure called the``Physics-inspired Energy Transition Neural Network" (PETNN). We demonstrate that PETNN's memory mechanism effectively stores information over long-term dependencies. Experimental results indicate that PETNN outperforms transformer-based methods across various sequence tasks. Furthermore, owing to its recurrent nature, PETNN exhibits significantly lower complexity. Our study presents an optimal foundational recurrent architecture and highlights the potential for developing effective recurrent neural networks in fields currently dominated by Transformer.
Integrating Dual Prototypes for Task-Wise Adaption in Pre-Trained Model-Based Class-Incremental Learning
Nov 26, 2024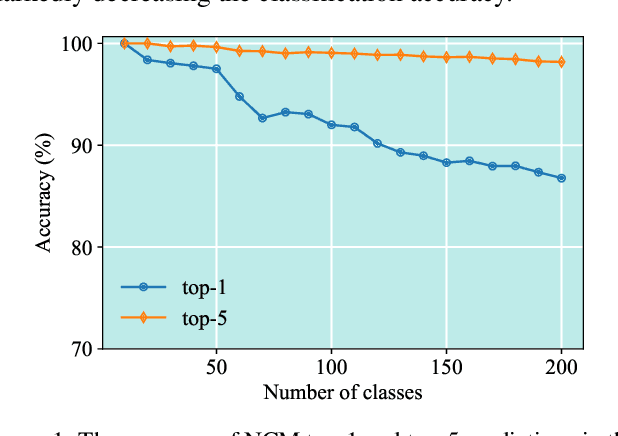
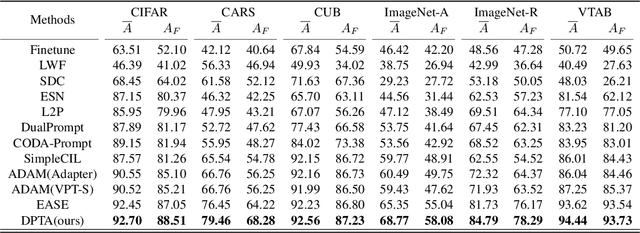
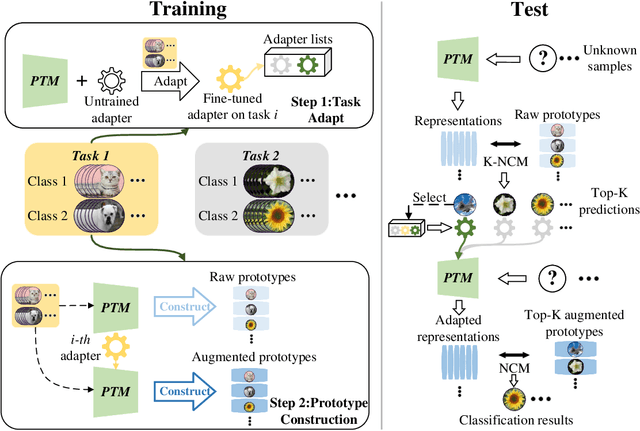
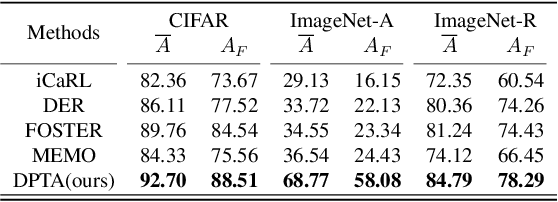
Class-incremental learning (CIL) aims to acquire new classes while conserving historical knowledge incrementally. Despite existing pre-trained model (PTM) based methods performing excellently in CIL, it is better to fine-tune them on downstream incremental tasks with massive patterns unknown to PTMs. However, using task streams for fine-tuning could lead to catastrophic forgetting that will erase the knowledge in PTMs. This paper proposes the Dual Prototype network for Task-wise Adaption (DPTA) of PTM-based CIL. For each incremental learning task, a task-wise adapter module is built to fine-tune the PTM, where the center-adapt loss forces the representation to be more centrally clustered and class separable. The dual prototype network improves the prediction process by enabling test-time adapter selection, where the raw prototypes deduce several possible task indexes of test samples to select suitable adapter modules for PTM, and the augmented prototypes that could separate highly correlated classes are utilized to determine the final result. Experiments on several benchmark datasets demonstrate the state-of-the-art performance of DPTA. The code will be open-sourced after the paper is published.
Faster and Simpler Siamese Network for Single Object Tracking
May 07, 2021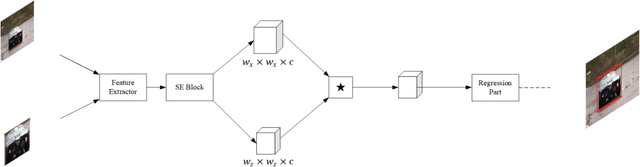
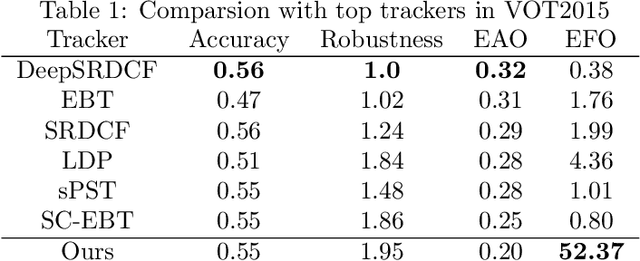
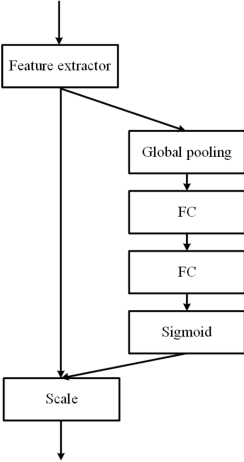
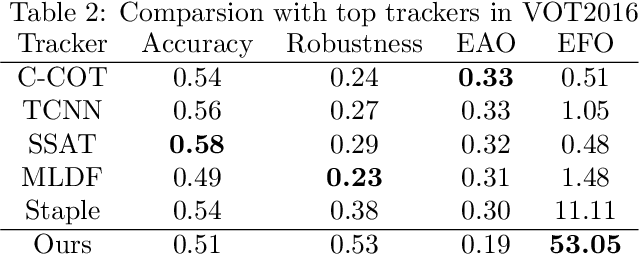
Single object tracking (SOT) is currently one of the most important tasks in computer vision. With the development of the deep network and the release for a series of large scale datasets for single object tracking, siamese networks have been proposed and perform better than most of the traditional methods. However, recent siamese networks get deeper and slower to obtain better performance. Most of these methods could only meet the needs of real-time object tracking in ideal environments. In order to achieve a better balance between efficiency and accuracy, we propose a simpler siamese network for single object tracking, which runs fast in poor hardware configurations while remaining an excellent accuracy. We use a more efficient regression method to compute the location of the tracked object in a shorter time without losing much precision. For improving the accuracy and speeding up the training progress, we introduce the Squeeze-and-excitation (SE) network into the feature extractor. In this paper, we compare the proposed method with some state-of-the-art trackers and analysis their performances. Using our method, a siamese network could be trained with shorter time and less data. The fast processing speed enables combining object tracking with object detection or other tasks in real time.
Super Interaction Neural Network
May 29, 2019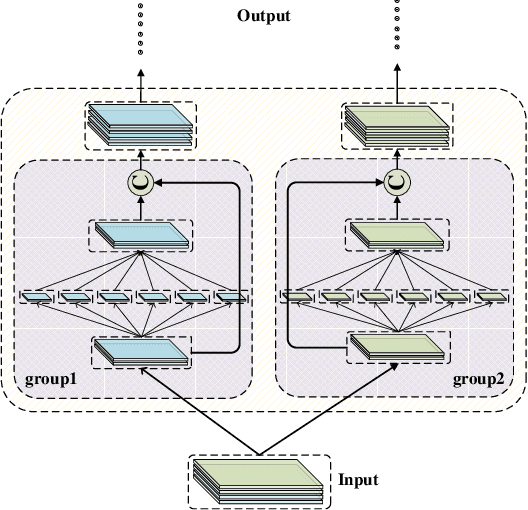
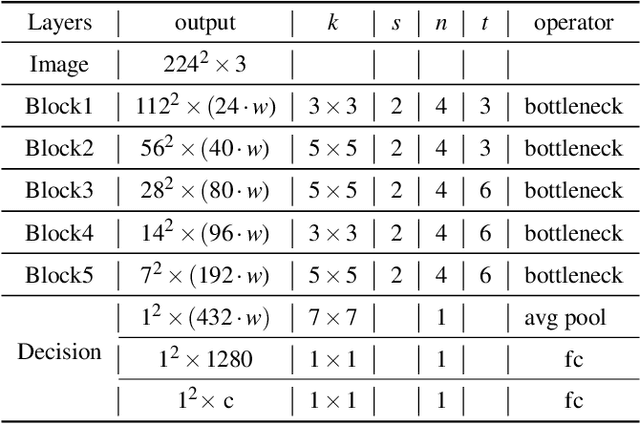
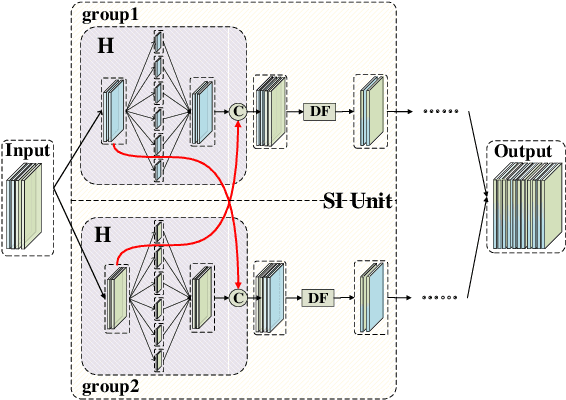

Recent studies have demonstrated that the convolutional networks heavily rely on the quality and quantity of generated features. However, in lightweight networks, there are limited available feature information because these networks tend to be shallower and thinner due to the efficiency consideration. For farther improving the performance and accuracy of lightweight networks, we develop Super Interaction Neural Networks (SINet) model from a novel point of view: enhancing the information interaction in neural networks. In order to achieve information interaction along the width of the deep network, we propose Exchange Shortcut Connection, which can integrate the information from different convolution groups without any extra computation cost. And then, in order to achieve information interaction along the depth of the network, we proposed Dense Funnel Layer and Attention based Hierarchical Joint Decision, which are able to make full use of middle layer features. Our experiments show that the superior performance of SINet over other state-of-the-art lightweight models in ImageNet dataset. Furthermore, we also exhibit the effectiveness and universality of our proposed components by ablation studies.
Label Mapping Neural Networks with Response Consolidation for Class Incremental Learning
May 20, 2019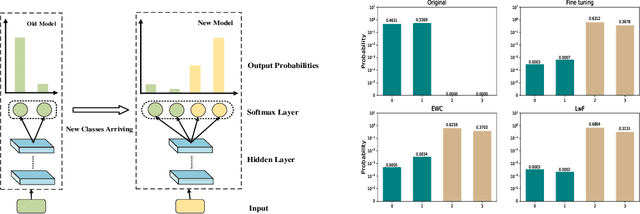
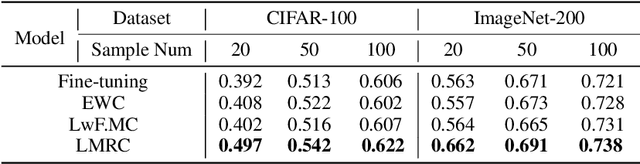
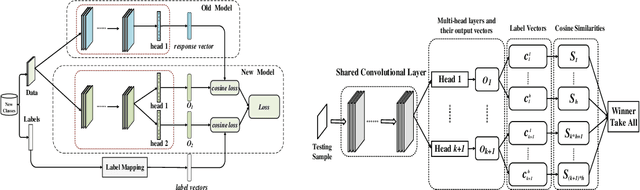
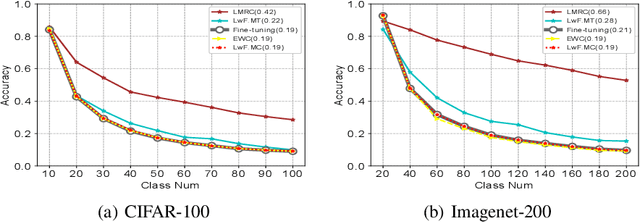
Class incremental learning refers to a special multi-class classification task, in which the number of classes is not fixed but is increasing with the continual arrival of new data. Existing researches mainly focused on solving catastrophic forgetting problem in class incremental learning. To this end, however, these models still require the old classes cached in the auxiliary data structure or models, which is inefficient in space or time. In this paper, it is the first time to discuss the difficulty without support of old classes in class incremental learning, which is called as softmax suppression problem. To address these challenges, we develop a new model named Label Mapping with Response Consolidation (LMRC), which need not access the old classes anymore. We propose the Label Mapping algorithm combined with the multi-head neural network for mitigating the softmax suppression problem, and propose the Response Consolidation method to overcome the catastrophic forgetting problem. Experimental results on the benchmark datasets show that our proposed method achieves much better performance compared to the related methods in different scenarios.
Operation-aware Neural Networks for User Response Prediction
Apr 02, 2019
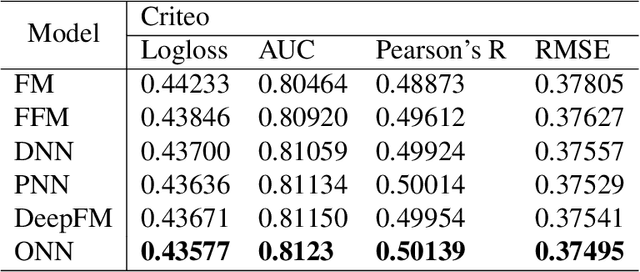
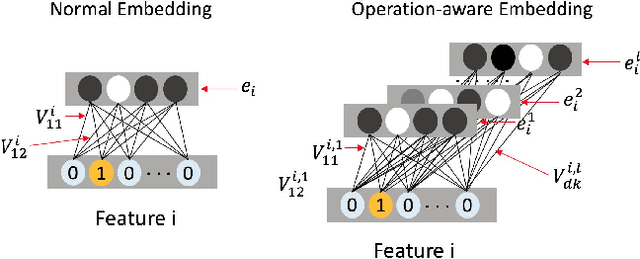
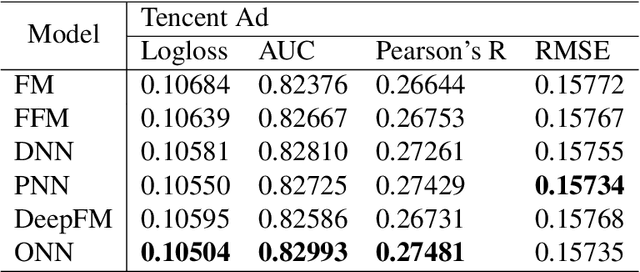
User response prediction makes a crucial contribution to the rapid development of online advertising system and recommendation system. The importance of learning feature interactions has been emphasized by many works. Many deep models are proposed to automatically learn high-order feature interactions. Since most features in advertising system and recommendation system are high-dimensional sparse features, deep models usually learn a low-dimensional distributed representation for each feature in the bottom layer. Besides traditional fully-connected architectures, some new operations, such as convolutional operations and product operations, are proposed to learn feature interactions better. In these models, the representation is shared among different operations. However, the best representation for different operations may be different. In this paper, we propose a new neural model named Operation-aware Neural Networks (ONN) which learns different representations for different operations. Our experimental results on two large-scale real-world ad click/conversion datasets demonstrate that ONN consistently outperforms the state-of-the-art models in both offline-training environment and online-training environment.