 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemoTuner: Efficient DBMS Knobs Tuning via LLM-Assisted Demonstration Reinforcement Learning
Nov 13, 2025The performance of modern DBMSs such as MySQL and PostgreSQL heavily depends on the configuration of performance-critical knobs. Manual tuning these knobs is laborious and inefficient due to the complex and high-dimensional nature of the configuration space. Among the automated tuning methods, reinforcement learning (RL)-based methods have recently sought to improve the DBMS knobs tuning process from several different perspectives. However, they still encounter challenges with slow convergence speed during offline training. In this paper, we mainly focus on how to leverage the valuable tuning hints contained in various textual documents such as DBMS manuals and web forums to improve the offline training of RL-based methods. To this end, we propose an efficient DBMS knobs tuning framework named DemoTuner via a novel LLM-assisted demonstration reinforcement learning method. Specifically, to comprehensively and accurately mine tuning hints from documents, we design a structured chain of thought prompt to employ LLMs to conduct a condition-aware tuning hints extraction task. To effectively integrate the mined tuning hints into RL agent training, we propose a hint-aware demonstration reinforcement learning algorithm HA-DDPGfD in DemoTuner. As far as we know, DemoTuner is the first work to introduce the demonstration reinforcement learning algorithm for DBMS knobs tuning. Experimental evaluations conducted on MySQL and PostgreSQL across various workloads demonstrate the significant advantages of DemoTuner in both performance improvement and online tuning cost reduction over three representative baselines including DB-BERT, GPTuner and CDBTune. Additionally, DemoTuner also exhibits superior adaptability to application scenarios with unknown workloads.
Explaining Model Overfitting in CNNs via GMM Clustering
Dec 12, 2024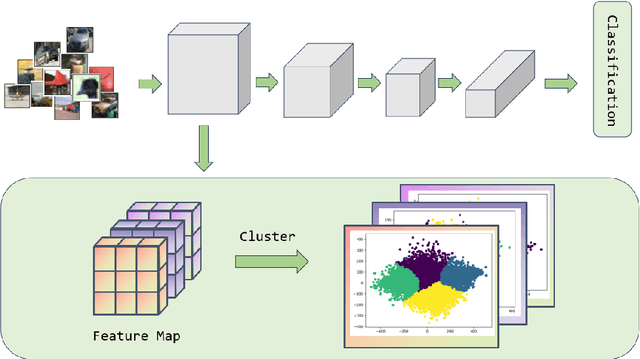

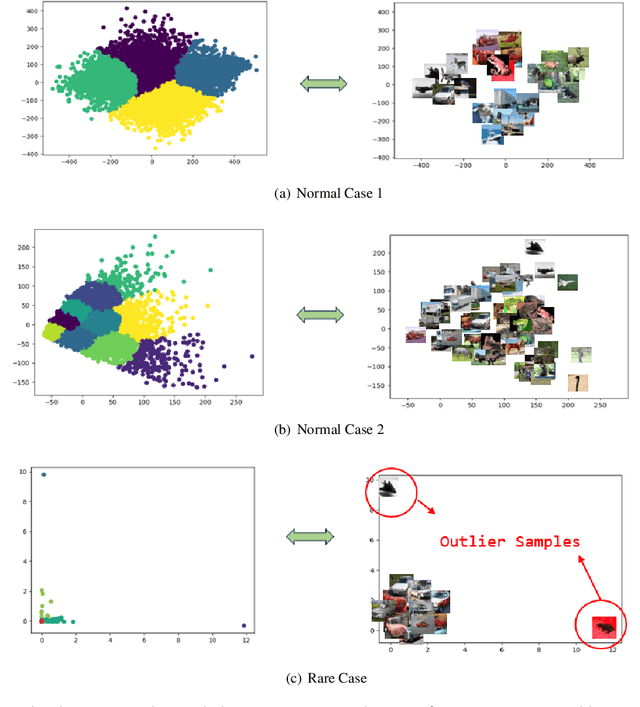

Convolutional Neural Networks (CNNs) have demonstrated remarkable prowess in the field of computer vision. However, their opaque decision-making processes pose significant challenges for practical applications. In this study, we provide quantitative metrics for assessing CNN filters by clustering the feature maps corresponding to individual filters in the model via Gaussian Mixture Model (GMM). By analyzing the clustering results, we screen out some anomaly filters associated with outlier samples. We further analyze the relationship between the anomaly filters and model overfitting, proposing three hypotheses. This method is universally applicable across diverse CNN architectures without modifications, as evidenced by its successful application to models like AlexNet and LeNet-5. We present three meticulously designed experiments demonstrating our hypotheses from the perspectives of model behavior, dataset characteristics, and filter impacts. Through this work, we offer a novel perspective for evaluating the CNN performance and gain new insights into the operational behavior of model overfitting.
Approximate attention with MLP: a pruning strategy for attention-based model in multivariate time series forecasting
Oct 31, 2024



Attention-based architectures have become ubiquitous in time series forecasting tasks, including spatio-temporal (STF) and long-term time series forecasting (LTSF). Yet, our understanding of the reasons for their effectiveness remains limited. This work proposes a new way to understand self-attention networks: we have shown empirically that the entire attention mechanism in the encoder can be reduced to an MLP formed by feedforward, skip-connection, and layer normalization operations for temporal and/or spatial modeling in multivariate time series forecasting. Specifically, the Q, K, and V projection, the attention score calculation, the dot-product between the attention score and the V, and the final projection can be removed from the attention-based networks without significantly degrading the performance that the given network remains the top-tier compared to other SOTA methods. For spatio-temporal networks, the MLP-replace-attention network achieves a reduction in FLOPS of $62.579\%$ with a loss in performance less than $2.5\%$; for LTSF, a reduction in FLOPs of $42.233\%$ with a loss in performance less than $2\%$.
HyperTuner: A Cross-Layer Multi-Objective Hyperparameter Auto-Tuning Framework for Data Analytic Services
Apr 20, 2023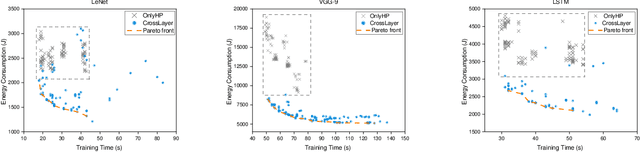

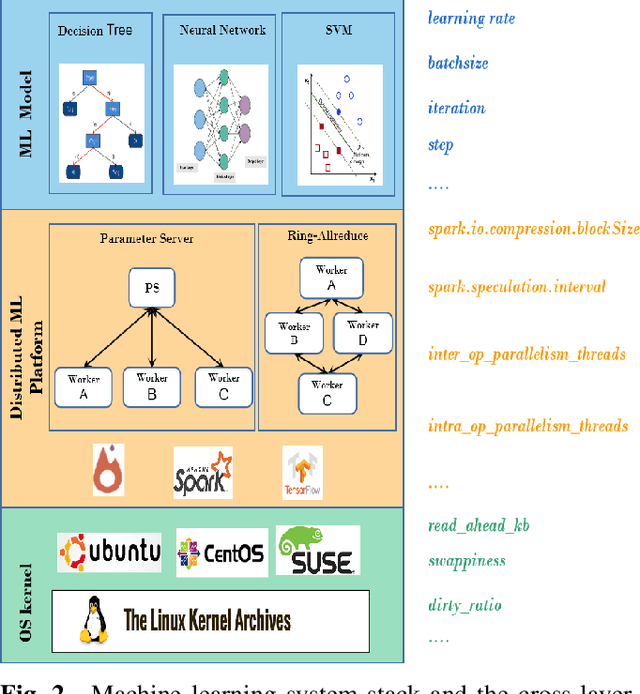
Hyper-parameters optimization (HPO) is vital for machine learning models. Besides model accuracy, other tuning intentions such as model training time and energy consumption are also worthy of attention from data analytic service providers. Hence, it is essential to take both model hyperparameters and system parameters into consideration to execute cross-layer multi-objective hyperparameter auto-tuning. Towards this challenging target, we propose HyperTuner in this paper. To address the formulated high-dimensional black-box multi-objective optimization problem, HyperTuner first conducts multi-objective parameter importance ranking with its MOPIR algorithm and then leverages the proposed ADUMBO algorithm to find the Pareto-optimal configuration set. During each iteration, ADUMBO selects the most promising configuration from the generated Pareto candidate set via maximizing a new well-designed metric, which can adaptively leverage the uncertainty as well as the predicted mean across all the surrogate models along with the iteration times. We evaluate HyperTuner on our local distributed TensorFlow cluster and experimental results show that it is always able to find a better Pareto configuration front superior in both convergence and diversity compared with the other four baseline algorithms. Besides, experiments with different training datasets, different optimization objectives and different machine learning platforms verify that HyperTuner can well adapt to various data analytic service scenarios.