 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignCoder: Aligning Retrieval with Target Intent for Repository-Level Code Completion
Jan 27, 2026Repository-level code completion remains a challenging task for existing code large language models (code LLMs) due to their limited understanding of repository-specific context and domain knowledge. While retrieval-augmented generation (RAG) approaches have shown promise by retrieving relevant code snippets as cross-file context, they suffer from two fundamental problems: misalignment between the query and the target code in the retrieval process, and the inability of existing retrieval methods to effectively utilize the inference information. To address these challenges, we propose AlignCoder, a repository-level code completion framework that introduces a query enhancement mechanism and a reinforcement learning based retriever training method. Our approach generates multiple candidate completions to construct an enhanced query that bridges the semantic gap between the initial query and the target code. Additionally, we employ reinforcement learning to train an AlignRetriever that learns to leverage inference information in the enhanced query for more accurate retrieval. We evaluate AlignCoder on two widely-used benchmarks (CrossCodeEval and RepoEval) across five backbone code LLMs, demonstrating an 18.1% improvement in EM score compared to baselines on the CrossCodeEval benchmark. The results show that our framework achieves superior performance and exhibits high generalizability across various code LLMs and programming languages.
Advances and Frontiers of LLM-based Issue Resolution in Software Engineering: A Comprehensive Survey
Jan 15, 2026Issue resolution, a complex Software Engineering (SWE) task integral to real-world development, has emerged as a compelling challenge for artificial intelligence. The establishment of benchmarks like SWE-bench revealed this task as profoundly difficult for large language models, thereby significantly accelerating the evolution of autonomous coding agents. This paper presents a systematic survey of this emerging domain. We begin by examining data construction pipelines, covering automated collection and synthesis approaches. We then provide a comprehensive analysis of methodologies, spanning training-free frameworks with their modular components to training-based techniques, including supervised fine-tuning and reinforcement learning. Subsequently, we discuss critical analyses of data quality and agent behavior, alongside practical applications. Finally, we identify key challenges and outline promising directions for future research. An open-source repository is maintained at https://github.com/DeepSoftwareAnalytics/Awesome-Issue-Resolution to serve as a dynamic resource in this field.
Alada: Alternating Adaptation of Momentum Method for Memory-Efficient Matrix Optimization
Dec 15, 2025This work proposes Alada, an adaptive momentum method for stochastic optimization over large-scale matrices. Alada employs a rank-one factorization approach to estimate the second moment of gradients, where factors are updated alternatively to minimize the estimation error. Alada achieves sublinear memory overheads and can be readily extended to optimizing tensor-shaped variables.We also equip Alada with a first moment estimation rule, which enhances the algorithm's robustness without incurring additional memory overheads. The theoretical performance of Alada aligns with that of traditional methods such as Adam. Numerical studies conducted on several natural language processing tasks demonstrate the reduction in memory overheads and the robustness in training large models relative to Adam and its variants.
MIRNet: Integrating Constrained Graph-Based Reasoning with Pre-training for Diagnostic Medical Imaging
Nov 13, 2025Automated interpretation of medical images demands robust modeling of complex visual-semantic relationships while addressing annotation scarcity, label imbalance, and clinical plausibility constraints. We introduce MIRNet (Medical Image Reasoner Network), a novel framework that integrates self-supervised pre-training with constrained graph-based reasoning. Tongue image diagnosis is a particularly challenging domain that requires fine-grained visual and semantic understanding. Our approach leverages self-supervised masked autoencoder (MAE) to learn transferable visual representations from unlabeled data; employs graph attention networks (GAT) to model label correlations through expert-defined structured graphs; enforces clinical priors via constraint-aware optimization using KL divergence and regularization losses; and mitigates imbalance using asymmetric loss (ASL) and boosting ensembles. To address annotation scarcity, we also introduce TongueAtlas-4K, a comprehensive expert-curated benchmark comprising 4,000 images annotated with 22 diagnostic labels--representing the largest public dataset in tongue analysis. Validation shows our method achieves state-of-the-art performance. While optimized for tongue diagnosis, the framework readily generalizes to broader diagnostic medical imaging tasks.
What Matters in LLM-generated Data: Diversity and Its Effect on Model Fine-Tuning
Jun 24, 2025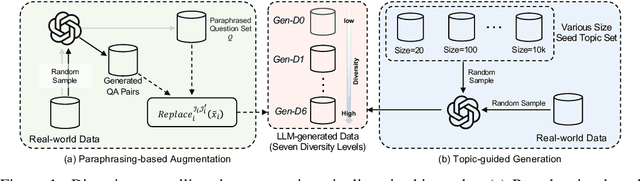
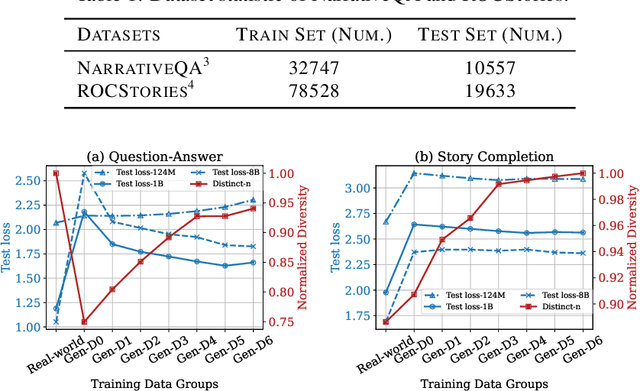
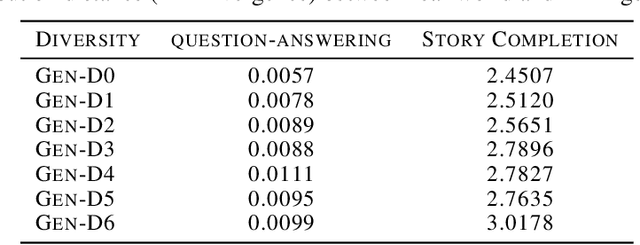
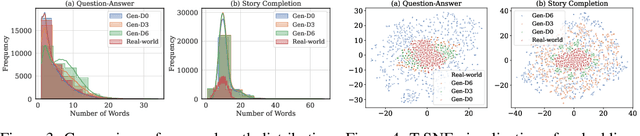
With the remarkable generative capabilities of large language models (LLMs), using LLM-generated data to train downstream models has emerged as a promising approach to mitigate data scarcity in specific domains and reduce time-consuming annotations. However, recent studies have highlighted a critical issue: iterative training on self-generated data results in model collapse, where model performance degrades over time. Despite extensive research on the implications of LLM-generated data, these works often neglect the importance of data diversity, a key factor in data quality. In this work, we aim to understand the implications of the diversity of LLM-generated data on downstream model performance. Specifically, we explore how varying levels of diversity in LLM-generated data affect downstream model performance. Additionally, we investigate the performance of models trained on data that mixes different proportions of LLM-generated data, which we refer to as synthetic data. Our experimental results show that, with minimal distribution shift, moderately diverse LLM-generated data can enhance model performance in scenarios with insufficient labeled data, whereas highly diverse generated data has a negative impact. We hope our empirical findings will offer valuable guidance for future studies on LLMs as data generators.
SWE-Factory: Your Automated Factory for Issue Resolution Training Data and Evaluation Benchmarks
Jun 12, 2025Constructing large-scale datasets for the GitHub issue resolution task is crucial for both training and evaluating the software engineering capabilities of Large Language Models (LLMs). However, the traditional process for creating such benchmarks is notoriously challenging and labor-intensive, particularly in the stages of setting up evaluation environments, grading test outcomes, and validating task instances. In this paper, we propose SWE-Factory, an automated pipeline designed to address these challenges. To tackle these issues, our pipeline integrates three core automated components. First, we introduce SWE-Builder, a multi-agent system that automates evaluation environment construction, which employs four specialized agents that work in a collaborative, iterative loop and leverages an environment memory pool to enhance efficiency. Second, we introduce a standardized, exit-code-based grading method that eliminates the need for manually writing custom parsers. Finally, we automate the fail2pass validation process using these reliable exit code signals. Experiments on 671 issues across four programming languages show that our pipeline can effectively construct valid task instances; for example, with GPT-4.1-mini, our SWE-Builder constructs 269 valid instances at $0.045 per instance, while with Gemini-2.5-flash, it achieves comparable performance at the lowest cost of $0.024 per instance. We also demonstrate that our exit-code-based grading achieves 100% accuracy compared to manual inspection, and our automated fail2pass validation reaches a precision of 0.92 and a recall of 1.00. We hope our automated pipeline will accelerate the collection of large-scale, high-quality GitHub issue resolution datasets for both training and evaluation. Our code and datasets are released at https://github.com/DeepSoftwareAnalytics/swe-factory.
Blind Spot Navigation: Evolutionary Discovery of Sensitive Semantic Concepts for LVLMs
May 21, 2025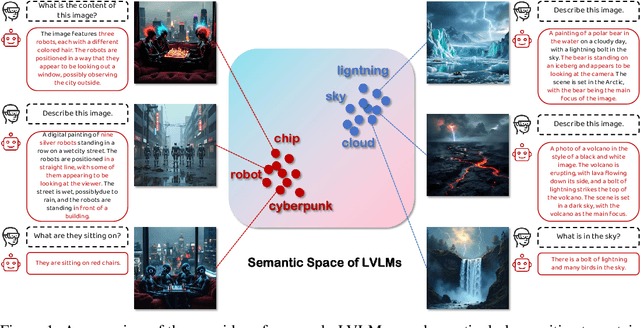
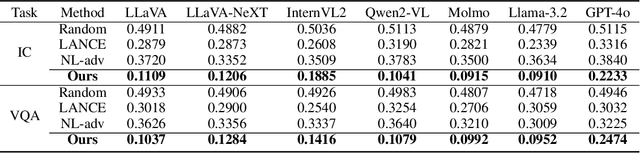
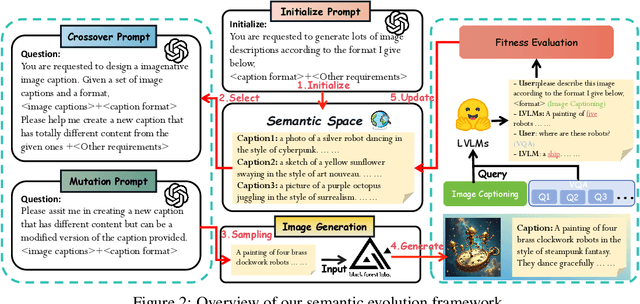
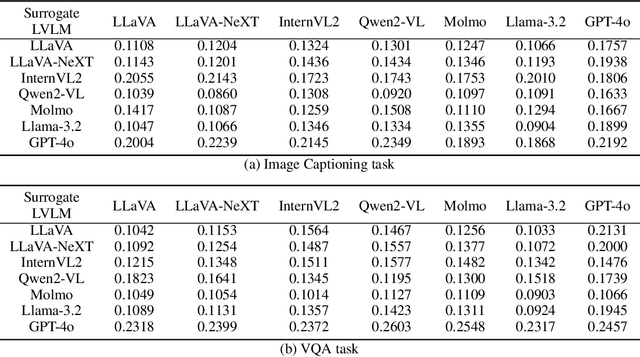
Adversarial attacks aim to generate malicious inputs that mislead deep models, but beyond causing model failure, they cannot provide certain interpretable information such as ``\textit{What content in inputs make models more likely to fail?}'' However, this information is crucial for researchers to specifically improve model robustness. Recent research suggests that models may be particularly sensitive to certain semantics in visual inputs (such as ``wet,'' ``foggy''), making them prone to errors. Inspired by this, in this paper we conducted the first exploration on large vision-language models (LVLMs) and found that LVLMs indeed are susceptible to hallucinations and various errors when facing specific semantic concepts in images. To efficiently search for these sensitive concepts, we integrated large language models (LLMs) and text-to-image (T2I) models to propose a novel semantic evolution framework. Randomly initialized semantic concepts undergo LLM-based crossover and mutation operations to form image descriptions, which are then converted by T2I models into visual inputs for LVLMs. The task-specific performance of LVLMs on each input is quantified as fitness scores for the involved semantics and serves as reward signals to further guide LLMs in exploring concepts that induce LVLMs. Extensive experiments on seven mainstream LVLMs and two multimodal tasks demonstrate the effectiveness of our method. Additionally, we provide interesting findings about the sensitive semantics of LVLMs, aiming to inspire further in-depth research.
Quantifying the Noise of Structural Perturbations on Graph Adversarial Attacks
Apr 30, 2025
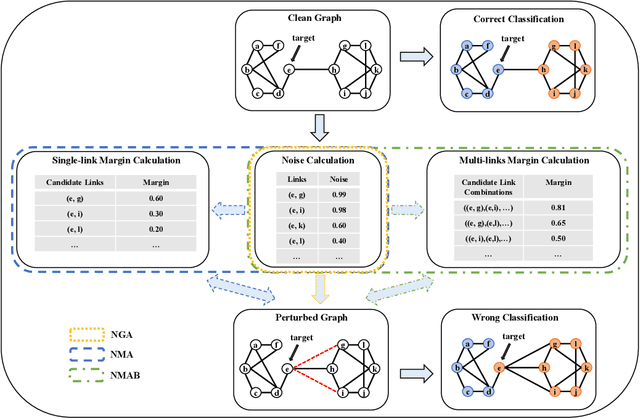

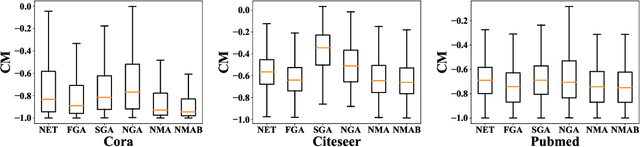
Graph neural networks have been widely utilized to solve graph-related tasks because of their strong learning power in utilizing the local information of neighbors. However, recent studies on graph adversarial attacks have proven that current graph neural networks are not robust against malicious attacks. Yet much of the existing work has focused on the optimization objective based on attack performance to obtain (near) optimal perturbations, but paid less attention to the strength quantification of each perturbation such as the injection of a particular node/link, which makes the choice of perturbations a black-box model that lacks interpretability. In this work, we propose the concept of noise to quantify the attack strength of each adversarial link. Furthermore, we propose three attack strategies based on the defined noise and classification margins in terms of single and multiple steps optimization. Extensive experiments conducted on benchmark datasets against three representative graph neural networks demonstrate the effectiveness of the proposed attack strategies. Particularly, we also investigate the preferred patterns of effective adversarial perturbations by analyzing the corresponding properties of the selected perturbation nodes.
Mitigating the Structural Bias in Graph Adversarial Defenses
Apr 29, 2025In recent years, graph neural networks (GNNs) have shown great potential in addressing various graph structure-related downstream tasks. However, recent studies have found that current GNNs are susceptible to malicious adversarial attacks. Given the inevitable presence of adversarial attacks in the real world, a variety of defense methods have been proposed to counter these attacks and enhance the robustness of GNNs. Despite the commendable performance of these defense methods, we have observed that they tend to exhibit a structural bias in terms of their defense capability on nodes with low degree (i.e., tail nodes), which is similar to the structural bias of traditional GNNs on nodes with low degree in the clean graph. Therefore, in this work, we propose a defense strategy by including hetero-homo augmented graph construction, $k$NN augmented graph construction, and multi-view node-wise attention modules to mitigate the structural bias of GNNs against adversarial attacks. Notably, the hetero-homo augmented graph consists of removing heterophilic links (i.e., links connecting nodes with dissimilar features) globally and adding homophilic links (i.e., links connecting nodes with similar features) for nodes with low degree. To further enhance the defense capability, an attention mechanism is adopted to adaptively combine the representations from the above two kinds of graph views. We conduct extensive experiments to demonstrate the defense and debiasing effect of the proposed strategy on benchmark datasets.
GT-SVQ: A Linear-Time Graph Transformer for Node Classification Using Spiking Vector Quantization
Apr 16, 2025Graph Transformers (GTs), which simultaneously integrate message-passing and self-attention mechanisms, have achieved promising empirical results in some graph prediction tasks. Although these approaches show the potential of Transformers in capturing long-range graph topology information, issues concerning the quadratic complexity and high computing energy consumption severely limit the scalability of GTs on large-scale graphs. Recently, as brain-inspired neural networks, Spiking Neural Networks (SNNs), facilitate the development of graph representation learning methods with lower computational and storage overhead through the unique event-driven spiking neurons. Inspired by these characteristics, we propose a linear-time Graph Transformer using Spiking Vector Quantization (GT-SVQ) for node classification. GT-SVQ reconstructs codebooks based on rate coding outputs from spiking neurons, and injects the codebooks into self-attention blocks to aggregate global information in linear complexity. Besides, spiking vector quantization effectively alleviates codebook collapse and the reliance on complex machinery (distance measure, auxiliary loss, etc.) present in previous vector quantization-based graph learning methods. In experiments, we compare GT-SVQ with other state-of-the-art baselines on node classification datasets ranging from small to large. Experimental results show that GT-SVQ has achieved competitive performances on most datasets while maintaining up to 130x faster inference speed compared to other GTs.