 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Decaying Steps: Enhancing Attack Stability and Transferability for Sign-based Optimizers
Feb 22, 2026Crafting adversarial examples can be formulated as an optimization problem. While sign-based optimizers such as I-FGSM and MI-FGSM have become the de facto standard for the induced optimization problems, there still exist several unsolved problems in theoretical grounding and practical reliability especially in non-convergence and instability, which inevitably influences their transferability. Contrary to the expectation, we observe that the attack success rate may degrade sharply when more number of iterations are conducted. In this paper, we address these issues from an optimization perspective. By reformulating the sign-based optimizer as a specific coordinate-wise gradient descent, we argue that one cause for non-convergence and instability is their non-decaying step-size scheduling. Based upon this viewpoint, we propose a series of new attack algorithms that enforce Monotonically Decreasing Coordinate-wise Step-sizes (MDCS) within sign-based optimizers. Typically, we further provide theoretical guarantees proving that MDCS-MI attains an optimal convergence rate of $O(1/\sqrt{T})$, where $T$ is the number of iterations. Extensive experiments on image classification and cross-modal retrieval tasks demonstrate that our approach not only significantly improves transferability but also enhances attack stability compared to state-of-the-art sign-based methods.
Vista: Scene-Aware Optimization for Streaming Video Question Answering under Post-Hoc Queries
Feb 09, 2026Streaming video question answering (Streaming Video QA) poses distinct challenges for multimodal large language models (MLLMs), as video frames arrive sequentially and user queries can be issued at arbitrary time points. Existing solutions relying on fixed-size memory or naive compression often suffer from context loss or memory overflow, limiting their effectiveness in long-form, real-time scenarios. We present Vista, a novel framework for scene-aware streaming video QA that enables efficient and scalable reasoning over continuous video streams. The innovation of Vista can be summarized in three aspects: (1) scene-aware segmentation, where Vista dynamically clusters incoming frames into temporally and visually coherent scene units; (2) scene-aware compression, where each scene is compressed into a compact token representation and stored in GPU memory for efficient index-based retrieval, while full-resolution frames are offloaded to CPU memory; and (3) scene-aware recall, where relevant scenes are selectively recalled and reintegrated into the model input upon receiving a query, enabling both efficiency and completeness. Vista is model-agnostic and integrates seamlessly with a variety of vision-language backbones, enabling long-context reasoning without compromising latency or memory efficiency. Extensive experiments on StreamingBench demonstrate that Vista achieves state-of-the-art performance, establishing a strong baseline for real-world streaming video understanding.
Triage: Hierarchical Visual Budgeting for Efficient Video Reasoning in Vision-Language Models
Jan 30, 2026Vision-Language Models (VLMs) face significant computational challenges in video processing due to massive data redundancy, which creates prohibitively long token sequences. To address this, we introduce Triage, a training-free, plug-and-play framework that reframes video reasoning as a resource allocation problem via hierarchical visual budgeting. Its first stage, Frame-Level Budgeting, identifies keyframes by evaluating their visual dynamics and relevance, generating a strategic prior based on their importance scores. Guided by this prior, the second stage, Token-Level Budgeting, allocates tokens in two phases: it first secures high-relevance Core Tokens, followed by diverse Context Tokens selected with an efficient batched Maximal Marginal Relevance (MMR) algorithm. Extensive experiments demonstrate that Triage improves inference speed and reduces memory footprint, while maintaining or surpassing the performance of baselines and other methods on various video reasoning benchmarks.
Advances and Frontiers of LLM-based Issue Resolution in Software Engineering: A Comprehensive Survey
Jan 15, 2026Issue resolution, a complex Software Engineering (SWE) task integral to real-world development, has emerged as a compelling challenge for artificial intelligence. The establishment of benchmarks like SWE-bench revealed this task as profoundly difficult for large language models, thereby significantly accelerating the evolution of autonomous coding agents. This paper presents a systematic survey of this emerging domain. We begin by examining data construction pipelines, covering automated collection and synthesis approaches. We then provide a comprehensive analysis of methodologies, spanning training-free frameworks with their modular components to training-based techniques, including supervised fine-tuning and reinforcement learning. Subsequently, we discuss critical analyses of data quality and agent behavior, alongside practical applications. Finally, we identify key challenges and outline promising directions for future research. An open-source repository is maintained at https://github.com/DeepSoftwareAnalytics/Awesome-Issue-Resolution to serve as a dynamic resource in this field.
Optimizing the Adversarial Perturbation with a Momentum-based Adaptive Matrix
Dec 16, 2025Generating adversarial examples (AEs) can be formulated as an optimization problem. Among various optimization-based attacks, the gradient-based PGD and the momentum-based MI-FGSM have garnered considerable interest. However, all these attacks use the sign function to scale their perturbations, which raises several theoretical concerns from the point of view of optimization. In this paper, we first reveal that PGD is actually a specific reformulation of the projected gradient method using only the current gradient to determine its step-size. Further, we show that when we utilize a conventional adaptive matrix with the accumulated gradients to scale the perturbation, PGD becomes AdaGrad. Motivated by this analysis, we present a novel momentum-based attack AdaMI, in which the perturbation is optimized with an interesting momentum-based adaptive matrix. AdaMI is proved to attain optimal convergence for convex problems, indicating that it addresses the non-convergence issue of MI-FGSM, thereby ensuring stability of the optimization process. The experiments demonstrate that the proposed momentum-based adaptive matrix can serve as a general and effective technique to boost adversarial transferability over the state-of-the-art methods across different networks while maintaining better stability and imperceptibility.
FastBEV++: Fast by Algorithm, Deployable by Design
Dec 09, 2025The advancement of camera-only Bird's-Eye-View(BEV) perception is currently impeded by a fundamental tension between state-of-the-art performance and on-vehicle deployment tractability. This bottleneck stems from a deep-rooted dependency on computationally prohibitive view transformations and bespoke, platform-specific kernels. This paper introduces FastBEV++, a framework engineered to reconcile this tension, demonstrating that high performance and deployment efficiency can be achieved in unison via two guiding principles: Fast by Algorithm and Deployable by Design. We realize the "Deployable by Design" principle through a novel view transformation paradigm that decomposes the monolithic projection into a standard Index-Gather-Reshape pipeline. Enabled by a deterministic pre-sorting strategy, this transformation is executed entirely with elementary, operator native primitives (e.g Gather, Matrix Multiplication), which eliminates the need for specialized CUDA kernels and ensures fully TensorRT-native portability. Concurrently, our framework is "Fast by Algorithm", leveraging this decomposed structure to seamlessly integrate an end-to-end, depth-aware fusion mechanism. This jointly learned depth modulation, further bolstered by temporal aggregation and robust data augmentation, significantly enhances the geometric fidelity of the BEV representation.Empirical validation on the nuScenes benchmark corroborates the efficacy of our approach. FastBEV++ establishes a new state-of-the-art 0.359 NDS while maintaining exceptional real-time performance, exceeding 134 FPS on automotive-grade hardware (e.g Tesla T4). By offering a solution that is free of custom plugins yet highly accurate, FastBEV++ presents a mature and scalable design philosophy for production autonomous systems. The code is released at: https://github.com/ymlab/advanced-fastbev
SWE-Factory: Your Automated Factory for Issue Resolution Training Data and Evaluation Benchmarks
Jun 12, 2025Constructing large-scale datasets for the GitHub issue resolution task is crucial for both training and evaluating the software engineering capabilities of Large Language Models (LLMs). However, the traditional process for creating such benchmarks is notoriously challenging and labor-intensive, particularly in the stages of setting up evaluation environments, grading test outcomes, and validating task instances. In this paper, we propose SWE-Factory, an automated pipeline designed to address these challenges. To tackle these issues, our pipeline integrates three core automated components. First, we introduce SWE-Builder, a multi-agent system that automates evaluation environment construction, which employs four specialized agents that work in a collaborative, iterative loop and leverages an environment memory pool to enhance efficiency. Second, we introduce a standardized, exit-code-based grading method that eliminates the need for manually writing custom parsers. Finally, we automate the fail2pass validation process using these reliable exit code signals. Experiments on 671 issues across four programming languages show that our pipeline can effectively construct valid task instances; for example, with GPT-4.1-mini, our SWE-Builder constructs 269 valid instances at $0.045 per instance, while with Gemini-2.5-flash, it achieves comparable performance at the lowest cost of $0.024 per instance. We also demonstrate that our exit-code-based grading achieves 100% accuracy compared to manual inspection, and our automated fail2pass validation reaches a precision of 0.92 and a recall of 1.00. We hope our automated pipeline will accelerate the collection of large-scale, high-quality GitHub issue resolution datasets for both training and evaluation. Our code and datasets are released at https://github.com/DeepSoftwareAnalytics/swe-factory.
MoQAE: Mixed-Precision Quantization for Long-Context LLM Inference via Mixture of Quantization-Aware Experts
Jun 09, 2025One of the primary challenges in optimizing large language models (LLMs) for long-context inference lies in the high memory consumption of the Key-Value (KV) cache. Existing approaches, such as quantization, have demonstrated promising results in reducing memory usage. However, current quantization methods cannot take both effectiveness and efficiency into account. In this paper, we propose MoQAE, a novel mixed-precision quantization method via mixture of quantization-aware experts. First, we view different quantization bit-width configurations as experts and use the traditional mixture of experts (MoE) method to select the optimal configuration. To avoid the inefficiency caused by inputting tokens one by one into the router in the traditional MoE method, we input the tokens into the router chunk by chunk. Second, we design a lightweight router-only fine-tuning process to train MoQAE with a comprehensive loss to learn the trade-off between model accuracy and memory usage. Finally, we introduce a routing freezing (RF) and a routing sharing (RS) mechanism to further reduce the inference overhead. Extensive experiments on multiple benchmark datasets demonstrate that our method outperforms state-of-the-art KV cache quantization approaches in both efficiency and effectiveness.
MADLLM: Multivariate Anomaly Detection via Pre-trained LLMs
Apr 13, 2025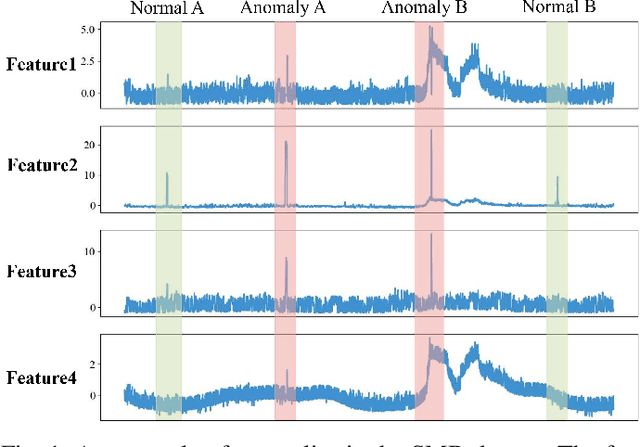
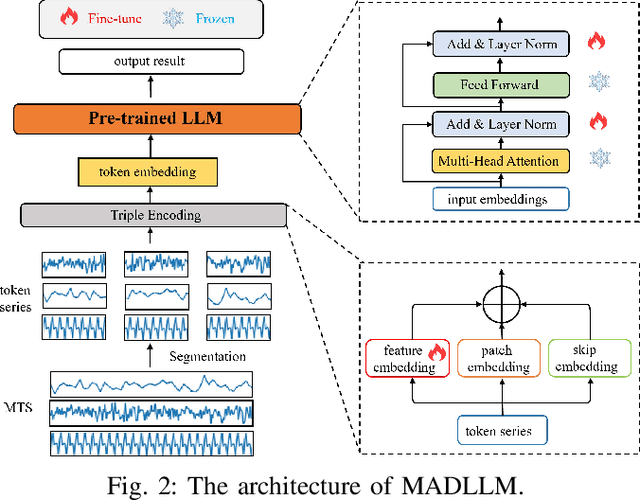
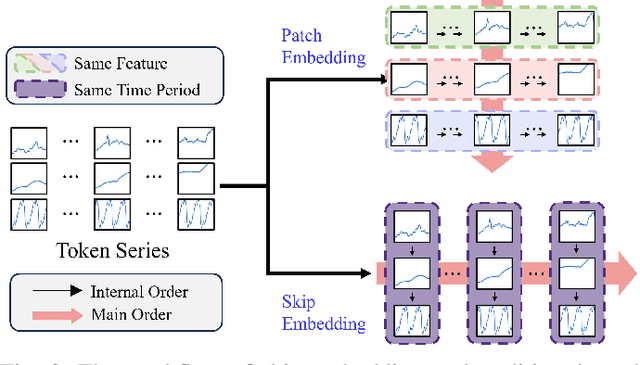
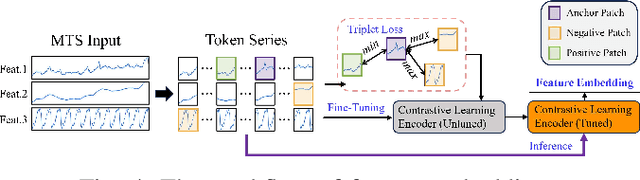
When applying pre-trained large language models (LLMs) to address anomaly detection tasks, the multivariate time series (MTS) modality of anomaly detection does not align with the text modality of LLMs. Existing methods simply transform the MTS data into multiple univariate time series sequences, which can cause many problems. This paper introduces MADLLM, a novel multivariate anomaly detection method via pre-trained LLMs. We design a new triple encoding technique to align the MTS modality with the text modality of LLMs. Specifically, this technique integrates the traditional patch embedding method with two novel embedding approaches: Skip Embedding, which alters the order of patch processing in traditional methods to help LLMs retain knowledge of previous features, and Feature Embedding, which leverages contrastive learning to allow the model to better understand the correlations between different features. Experimental results demonstrate that our method outperforms state-of-the-art methods in various public anomaly detection datasets.
Cocktail: Chunk-Adaptive Mixed-Precision Quantization for Long-Context LLM Inference
Mar 30, 2025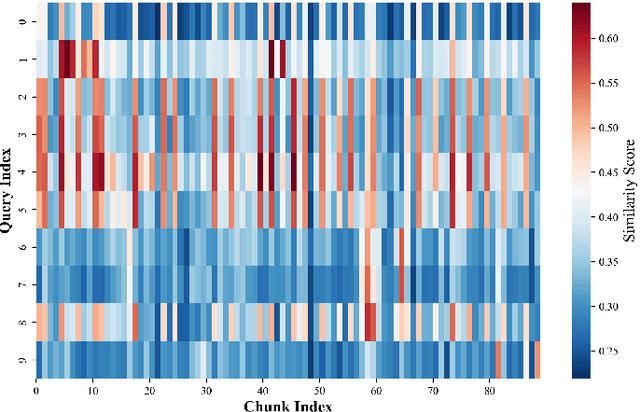
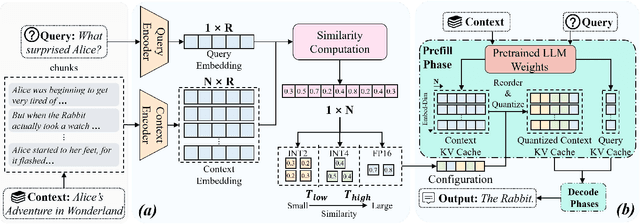
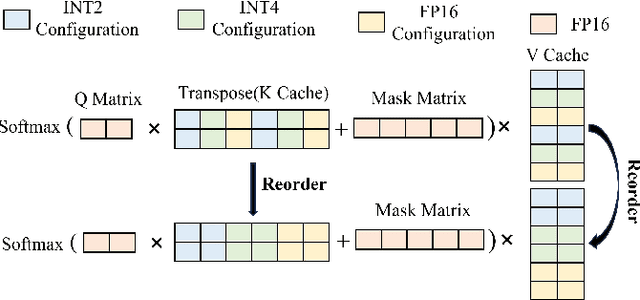
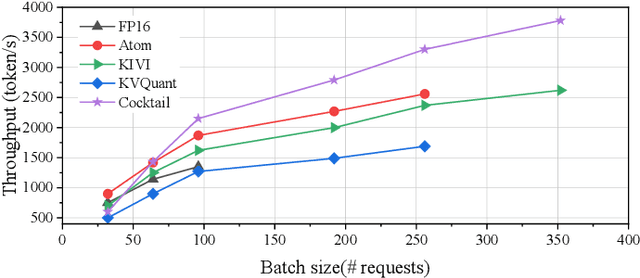
Recently, large language models (LLMs) have been able to handle longer and longer contexts. However, a context that is too long may cause intolerant inference latency and GPU memory usage. Existing methods propose mixed-precision quantization to the key-value (KV) cache in LLMs based on token granularity, which is time-consuming in the search process and hardware inefficient during computation. This paper introduces a novel approach called Cocktail, which employs chunk-adaptive mixed-precision quantization to optimize the KV cache. Cocktail consists of two modules: chunk-level quantization search and chunk-level KV cache computation. Chunk-level quantization search determines the optimal bitwidth configuration of the KV cache chunks quickly based on the similarity scores between the corresponding context chunks and the query, maintaining the model accuracy. Furthermore, chunk-level KV cache computation reorders the KV cache chunks before quantization, avoiding the hardware inefficiency caused by mixed-precision quantization in inference computation. Extensive experiments demonstrate that Cocktail outperforms state-of-the-art KV cache quantization methods on various models and datasets.