 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDedicated Inference Engine and Binary-Weight Neural Networks for Lightweight Instance Segmentation
Jan 03, 2025
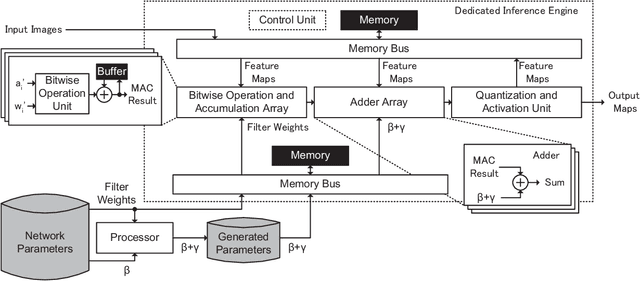
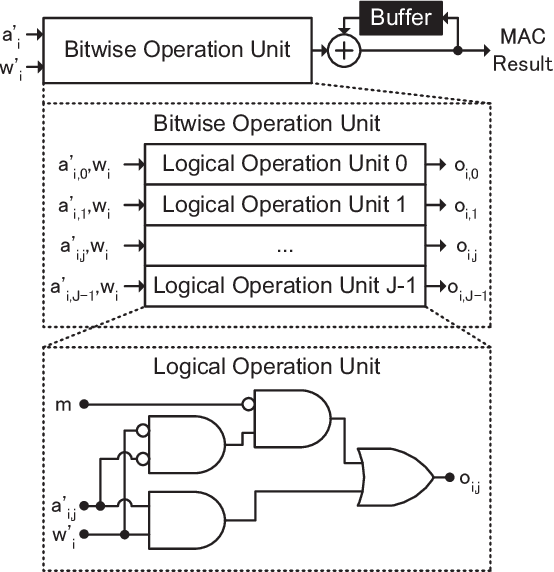
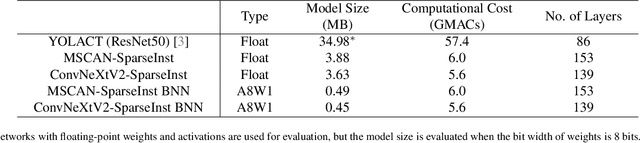
Reducing computational costs is an important issue for development of embedded systems. Binary-weight Neural Networks (BNNs), in which weights are binarized and activations are quantized, are employed to reduce computational costs of various kinds of applications. In this paper, a design methodology of hardware architecture for inference engines is proposed to handle modern BNNs with two operation modes. Multiply-Accumulate (MAC) operations can be simplified by replacing multiply operations with bitwise operations. The proposed method can effectively reduce the gate count of inference engines by removing a part of computational costs from the hardware system. The architecture of MAC operations can calculate the inference results of BNNs efficiently with only 52% of hardware costs compared with the related works. To show that the inference engine can handle practical applications, two lightweight networks which combine the backbones of SegNeXt and the decoder of SparseInst for instance segmentation are also proposed. The output results of the lightweight networks are computed using only bitwise operations and add operations. The proposed inference engine has lower hardware costs than related works. The experimental results show that the proposed inference engine can handle the proposed instance-segmentation networks and achieves higher accuracy than YOLACT on the "Person" category although the model size is 77.7$\times$ smaller compared with YOLACT.
UNet--: Memory-Efficient and Feature-Enhanced Network Architecture based on U-Net with Reduced Skip-Connections
Dec 24, 2024U-Net models with encoder, decoder, and skip-connections components have demonstrated effectiveness in a variety of vision tasks. The skip-connections transmit fine-grained information from the encoder to the decoder. It is necessary to maintain the feature maps used by the skip-connections in memory before the decoding stage. Therefore, they are not friendly to devices with limited resource. In this paper, we propose a universal method and architecture to reduce the memory consumption and meanwhile generate enhanced feature maps to improve network performance. To this end, we design a simple but effective Multi-Scale Information Aggregation Module (MSIAM) in the encoder and an Information Enhancement Module (IEM) in the decoder. The MSIAM aggregates multi-scale feature maps into single-scale with less memory. After that, the aggregated feature maps can be expanded and enhanced to multi-scale feature maps by the IEM. By applying the proposed method on NAFNet, a SOTA model in the field of image restoration, we design a memory-efficient and feature-enhanced network architecture, UNet--. The memory demand by the skip-connections in the UNet-- is reduced by 93.3%, while the performance is improved compared to NAFNet. Furthermore, we show that our proposed method can be generalized to multiple visual tasks, with consistent improvements in both memory consumption and network accuracy compared to the existing efficient architectures.
* 17 pages, 7 figures, accepted by ACCV2024
CASSOD-Net: Cascaded and Separable Structures of Dilated Convolution for Embedded Vision Systems and Applications
Apr 29, 2021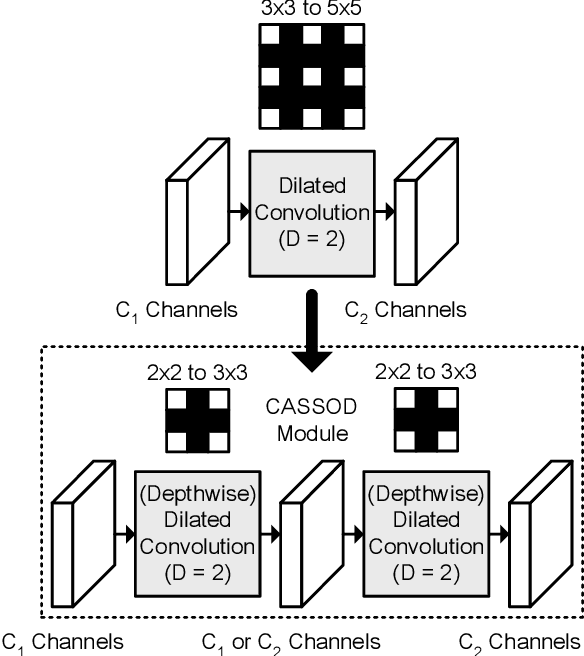

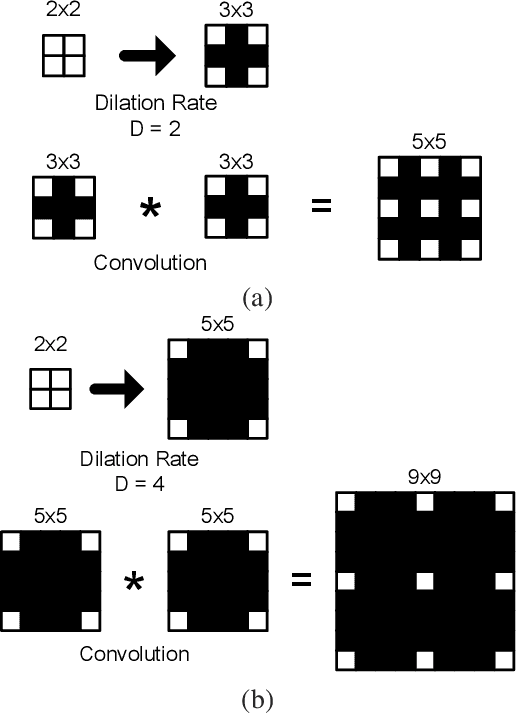
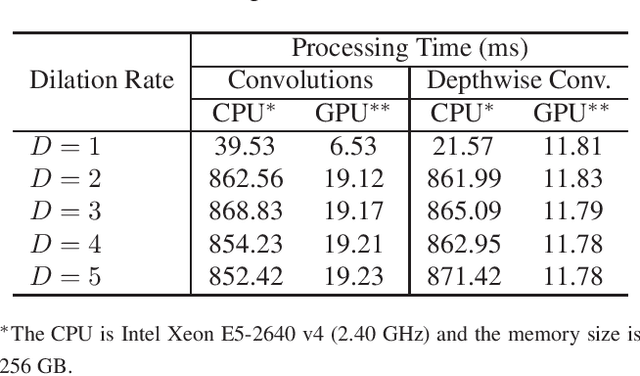
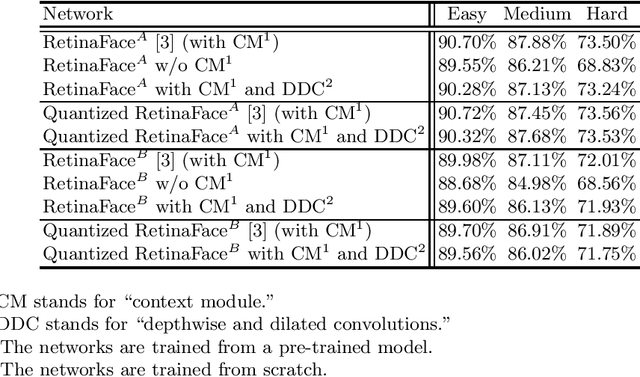
The field of view (FOV) of convolutional neural networks is highly related to the accuracy of inference. Dilated convolutions are known as an effective solution to the problems which require large FOVs. However, for general-purpose hardware or dedicated hardware, it usually takes extra time to handle dilated convolutions compared with standard convolutions. In this paper, we propose a network module, Cascaded and Separable Structure of Dilated (CASSOD) Convolution, and a special hardware system to handle the CASSOD networks efficiently. A CASSOD-Net includes multiple cascaded $2 \times 2$ dilated filters, which can be used to replace the traditional $3 \times 3$ dilated filters without decreasing the accuracy of inference. Two example applications, face detection and image segmentation, are tested with dilated convolutions and the proposed CASSOD modules. The new network for face detection achieves higher accuracy than the previous work with only 47% of filter weights in the dilated convolution layers of the context module. Moreover, the proposed hardware system can accelerate the computations of dilated convolutions, and it is 2.78 times faster than traditional hardware systems when the filter size is $3 \times 3$.
Hardware Architecture of Embedded Inference Accelerator and Analysis of Algorithms for Depthwise and Large-Kernel Convolutions
Apr 29, 2021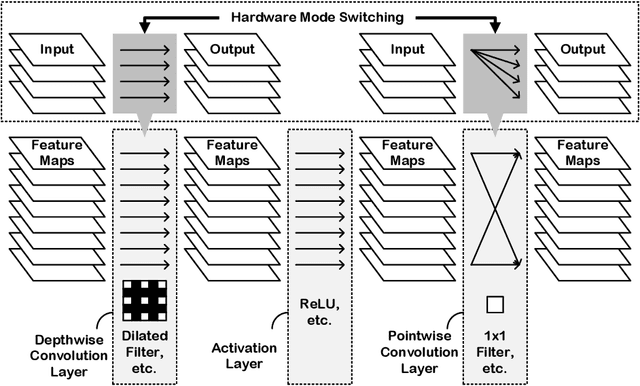
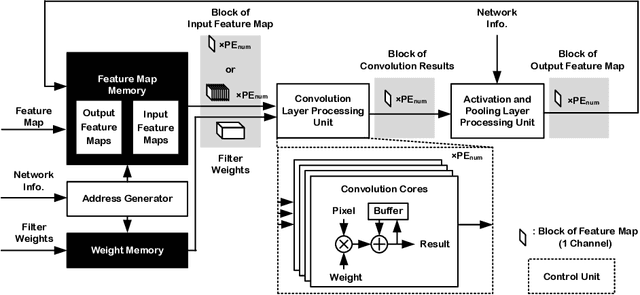
In order to handle modern convolutional neural networks (CNNs) efficiently, a hardware architecture of CNN inference accelerator is proposed to handle depthwise convolutions and regular convolutions, which are both essential building blocks for embedded-computer-vision algorithms. Different from related works, the proposed architecture can support filter kernels with different sizes with high flexibility since it does not require extra costs for intra-kernel parallelism, and it can generate convolution results faster than the architecture of the related works. The experimental results show the importance of supporting depthwise convolutions and dilated convolutions with the proposed hardware architecture. In addition to depthwise convolutions with large-kernels, a new structure called DDC layer, which includes the combination of depthwise convolutions and dilated convolutions, is also analyzed in this paper. For face detection, the computational costs decrease by 30%, and the model size decreases by 20% when the DDC layers are applied to the network. For image classification, the accuracy is increased by 1% by simply replacing $3 \times 3$ filters with $5 \times 5$ filters in depthwise convolutions.
* Camera-ready version for ECCV 2020 workshop (Embedded Vision Workshop)
Condensation-Net: Memory-Efficient Network Architecture with Cross-Channel Pooling Layers and Virtual Feature Maps
Apr 29, 2021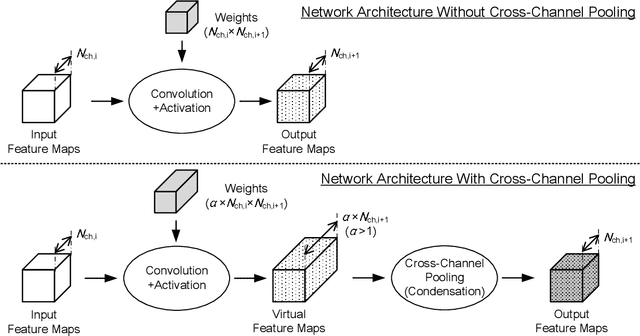

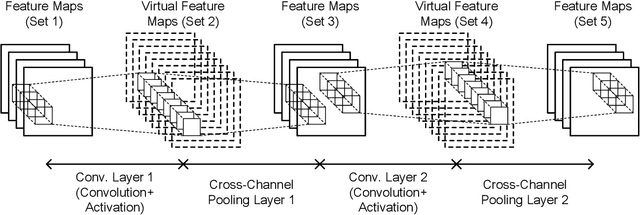
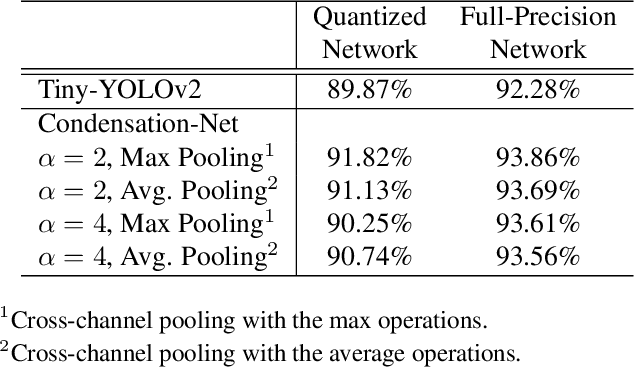
"Lightweight convolutional neural networks" is an important research topic in the field of embedded vision. To implement image recognition tasks on a resource-limited hardware platform, it is necessary to reduce the memory size and the computational cost. The contribution of this paper is stated as follows. First, we propose an algorithm to process a specific network architecture (Condensation-Net) without increasing the maximum memory storage for feature maps. The architecture for virtual feature maps saves 26.5% of memory bandwidth by calculating the results of cross-channel pooling before storing the feature map into the memory. Second, we show that cross-channel pooling can improve the accuracy of object detection tasks, such as face detection, because it increases the number of filter weights. Compared with Tiny-YOLOv2, the improvement of accuracy is 2.0% for quantized networks and 1.5% for full-precision networks when the false-positive rate is 0.1. Last but not the least, the analysis results show that the overhead to support the cross-channel pooling with the proposed hardware architecture is negligible small. The extra memory cost to support Condensation-Net is 0.2% of the total size, and the extra gate count is only 1.0% of the total size.
* Camera-ready version for CVPR 2019 workshop (Embedded Vision Workshop)
BAMSProd: A Step towards Generalizing the Adaptive Optimization Methods to Deep Binary Model
Sep 29, 2020
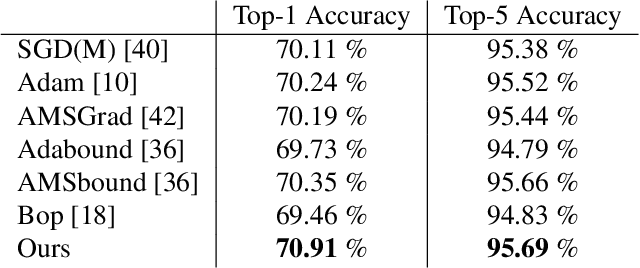

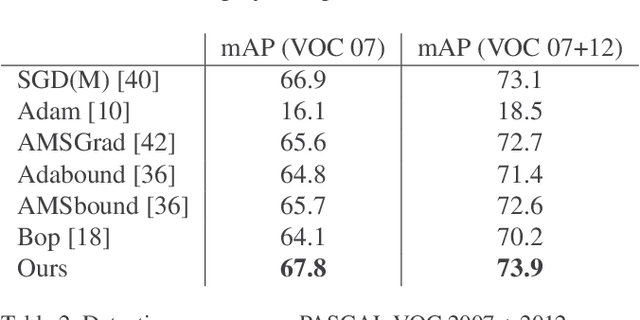
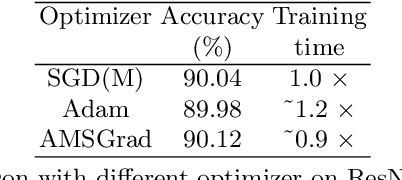
Recent methods have significantly reduced the performance degradation of Binary Neural Networks (BNNs), but guaranteeing the effective and efficient training of BNNs is an unsolved problem. The main reason is that the estimated gradients produced by the Straight-Through-Estimator (STE) mismatches with the gradients of the real derivatives. In this paper, we provide an explicit convex optimization example where training the BNNs with the traditionally adaptive optimization methods still faces the risk of non-convergence, and identify that constraining the range of gradients is critical for optimizing the deep binary model to avoid highly suboptimal solutions. For solving above issues, we propose a BAMSProd algorithm with a key observation that the convergence property of optimizing deep binary model is strongly related to the quantization errors. In brief, it employs an adaptive range constraint via an errors measurement for smoothing the gradients transition while follows the exponential moving strategy from AMSGrad to avoid errors accumulation during the optimization. The experiments verify the corollary of theoretical convergence analysis, and further demonstrate that our optimization method can speed up the convergence about 1:2x and boost the performance of BNNs to a significant level than the specific binary optimizer about 3:7%, even in a highly non-convex optimization problem.
* 10 pages, 4 figures, 2 tables
QuantNet: Learning to Quantize by Learning within Fully Differentiable Framework
Sep 10, 2020
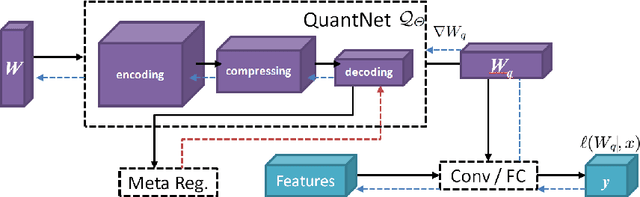

Despite the achievements of recent binarization methods on reducing the performance degradation of Binary Neural Networks (BNNs), gradient mismatching caused by the Straight-Through-Estimator (STE) still dominates quantized networks. This paper proposes a meta-based quantizer named QuantNet, which utilizes a differentiable sub-network to directly binarize the full-precision weights without resorting to STE and any learnable gradient estimators. Our method not only solves the problem of gradient mismatching, but also reduces the impact of discretization errors, caused by the binarizing operation in the deployment, on performance. Generally, the proposed algorithm is implemented within a fully differentiable framework, and is easily extended to the general network quantization with any bits. The quantitative experiments on CIFAR-100 and ImageNet demonstrate that QuantNet achieves the signifficant improvements comparing with previous binarization methods, and even bridges gaps of accuracies between binarized models and full-precision models.
IFQ-Net: Integrated Fixed-point Quantization Networks for Embedded Vision
Nov 19, 2019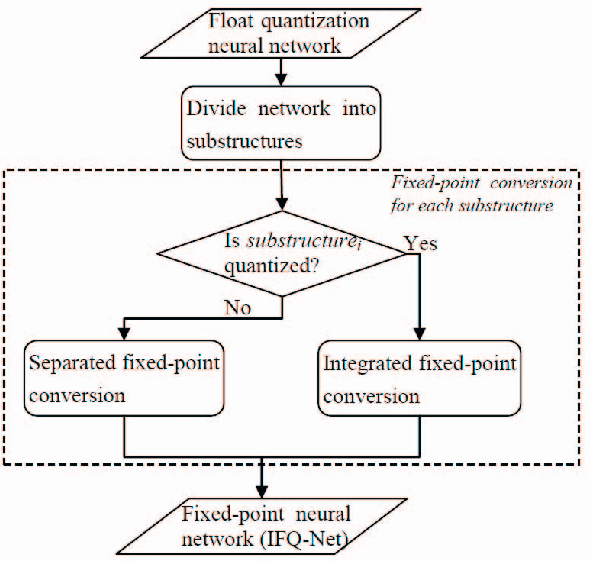
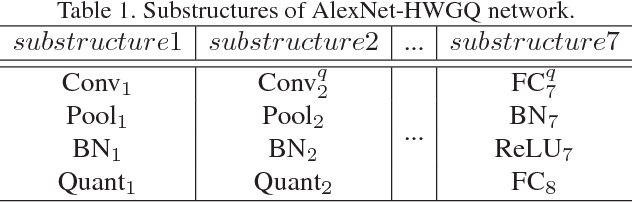
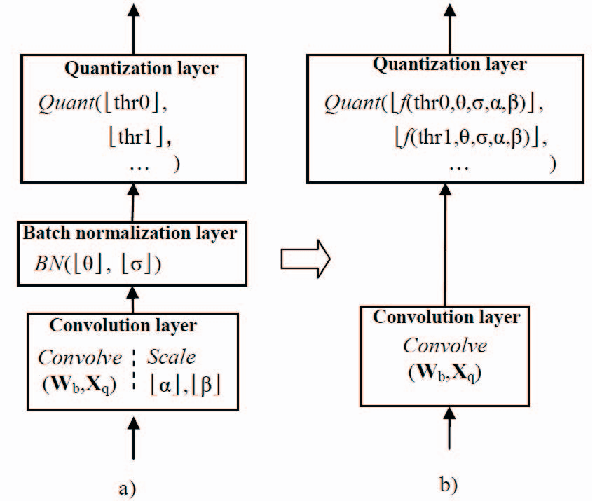
Deploying deep models on embedded devices has been a challenging problem since the great success of deep learning based networks. Fixed-point networks, which represent their data with low bits fixed-point and thus give remarkable savings on memory usage, are generally preferred. Even though current fixed-point networks employ relative low bits (e.g. 8-bits), the memory saving is far from enough for the embedded devices. On the other hand, quantization deep networks, for example XNOR-Net and HWGQNet, quantize the data into 1 or 2 bits resulting in more significant memory savings but still contain lots of floatingpoint data. In this paper, we propose a fixed-point network for embedded vision tasks through converting the floatingpoint data in a quantization network into fixed-point. Furthermore, to overcome the data loss caused by the conversion, we propose to compose floating-point data operations across multiple layers (e.g. convolution, batch normalization and quantization layers) and convert them into fixedpoint. We name the fixed-point network obtained through such integrated conversion as Integrated Fixed-point Quantization Networks (IFQ-Net). We demonstrate that our IFQNet gives 2.16x and 18x more savings on model size and runtime feature map memory respectively with similar accuracy on ImageNet. Furthermore, based on YOLOv2, we design IFQ-Tinier-YOLO face detector which is a fixed-point network with 256x reduction in model size (246k Bytes) than Tiny-YOLO. We illustrate the promising performance of our face detector in terms of detection rate on Face Detection Data Set and Bencmark (FDDB) and qualitative results of detecting small faces of Wider Face dataset.
* 9 pages, 6 figures
DupNet: Towards Very Tiny Quantized CNN with Improved Accuracy for Face Detection
Nov 13, 2019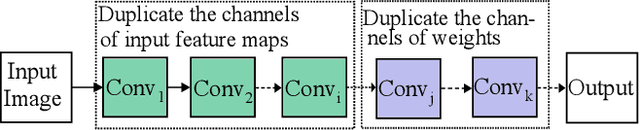
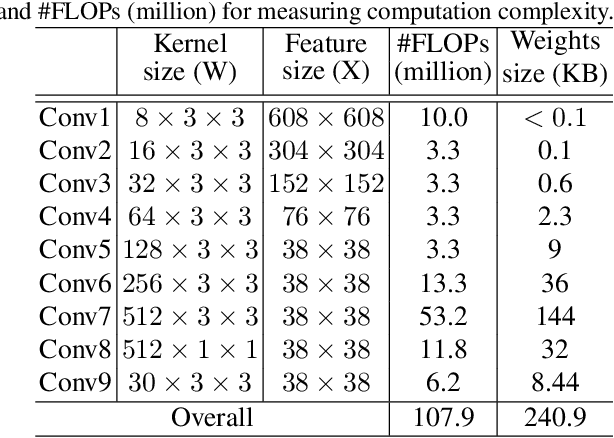
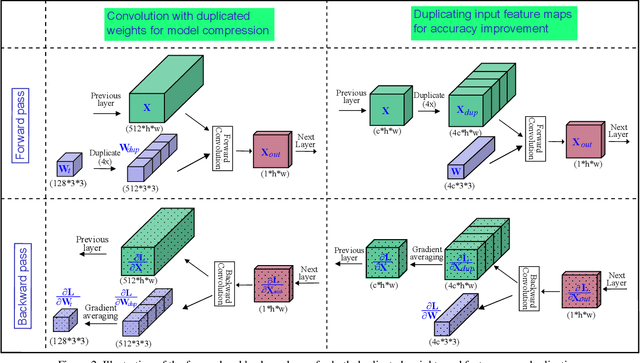
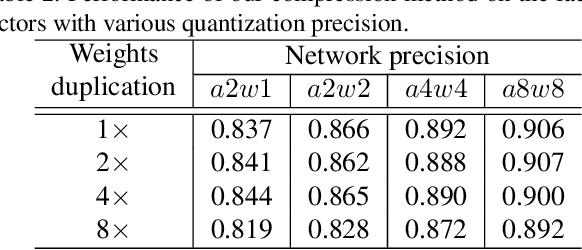
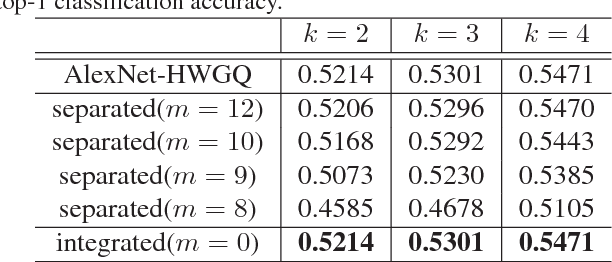
Deploying deep learning based face detectors on edge devices is a challenging task due to the limited computation resources. Even though binarizing the weights of a very tiny network gives impressive compactness on model size (e.g. 240.9 KB for IFQ-Tinier-YOLO), it is not tiny enough to fit in the embedded devices with strict memory constraints. In this paper, we propose DupNet which consists of two parts. Firstly, we employ weights with duplicated channels for the weight-intensive layers to reduce the model size. Secondly, for the quantization-sensitive layers whose quantization causes notable accuracy drop, we duplicate its input feature maps. It allows us to use more weights channels for convolving more representative outputs. Based on that, we propose a very tiny face detector, DupNet-Tinier-YOLO, which is 6.5X times smaller on model size and 42.0% less complex on computation and meanwhile achieves 2.4% higher detection than IFQ-Tinier-YOLO. Comparing with the full precision Tiny-YOLO, our DupNet-Tinier-YOLO gives 1,694.2X and 389.9X times savings on model size and computation complexity respectively with only 4.0% drop on detection rate (0.880 vs. 0.920). Moreover, our DupNet-Tinier-YOLO is only 36.9 KB, which is the tiniest deep face detector to our best knowledge.
Knowledge Representing: Efficient, Sparse Representation of Prior Knowledge for Knowledge Distillation
Nov 13, 2019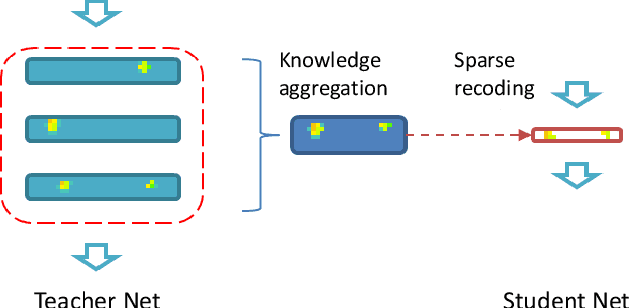

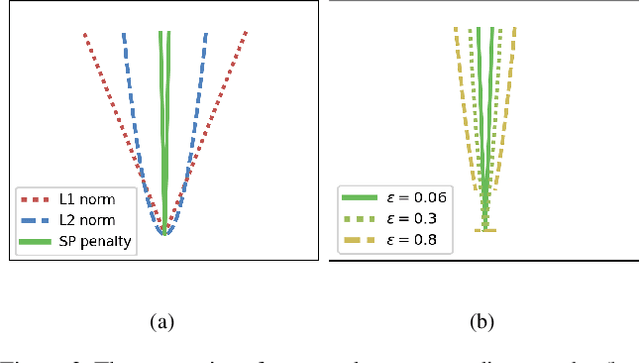
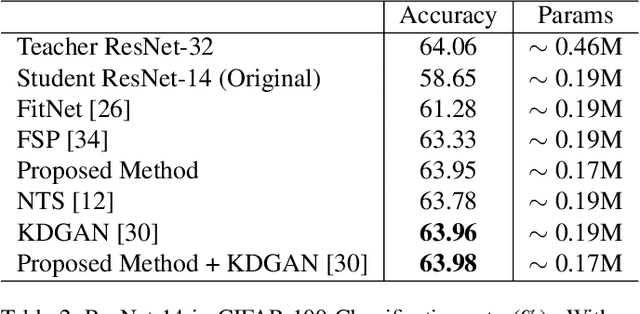
Despite the recent works on knowledge distillation (KD) have achieved a further improvement through elaborately modeling the decision boundary as the posterior knowledge, their performance is still dependent on the hypothesis that the target network has a powerful capacity (representation ability). In this paper, we propose a knowledge representing (KR) framework mainly focusing on modeling the parameters distribution as prior knowledge. Firstly, we suggest a knowledge aggregation scheme in order to answer how to represent the prior knowledge from teacher network. Through aggregating the parameters distribution from teacher network into more abstract level, the scheme is able to alleviate the phenomenon of residual accumulation in the deeper layers. Secondly, as the critical issue of what the most important prior knowledge is for better distilling, we design a sparse recoding penalty for constraining the student network to learn with the penalized gradients. With the proposed penalty, the student network can effectively avoid the over-regularization during knowledge distilling and converge faster. The quantitative experiments exhibit that the proposed framework achieves the state-ofthe-arts performance, even though the target network does not have the expected capacity. Moreover, the framework is flexible enough for combining with other KD methods based on the posterior knowledge.