 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNet--: Memory-Efficient and Feature-Enhanced Network Architecture based on U-Net with Reduced Skip-Connections
Dec 24, 2024U-Net models with encoder, decoder, and skip-connections components have demonstrated effectiveness in a variety of vision tasks. The skip-connections transmit fine-grained information from the encoder to the decoder. It is necessary to maintain the feature maps used by the skip-connections in memory before the decoding stage. Therefore, they are not friendly to devices with limited resource. In this paper, we propose a universal method and architecture to reduce the memory consumption and meanwhile generate enhanced feature maps to improve network performance. To this end, we design a simple but effective Multi-Scale Information Aggregation Module (MSIAM) in the encoder and an Information Enhancement Module (IEM) in the decoder. The MSIAM aggregates multi-scale feature maps into single-scale with less memory. After that, the aggregated feature maps can be expanded and enhanced to multi-scale feature maps by the IEM. By applying the proposed method on NAFNet, a SOTA model in the field of image restoration, we design a memory-efficient and feature-enhanced network architecture, UNet--. The memory demand by the skip-connections in the UNet-- is reduced by 93.3%, while the performance is improved compared to NAFNet. Furthermore, we show that our proposed method can be generalized to multiple visual tasks, with consistent improvements in both memory consumption and network accuracy compared to the existing efficient architectures.
* 17 pages, 7 figures, accepted by ACCV2024
CASSOD-Net: Cascaded and Separable Structures of Dilated Convolution for Embedded Vision Systems and Applications
Apr 29, 2021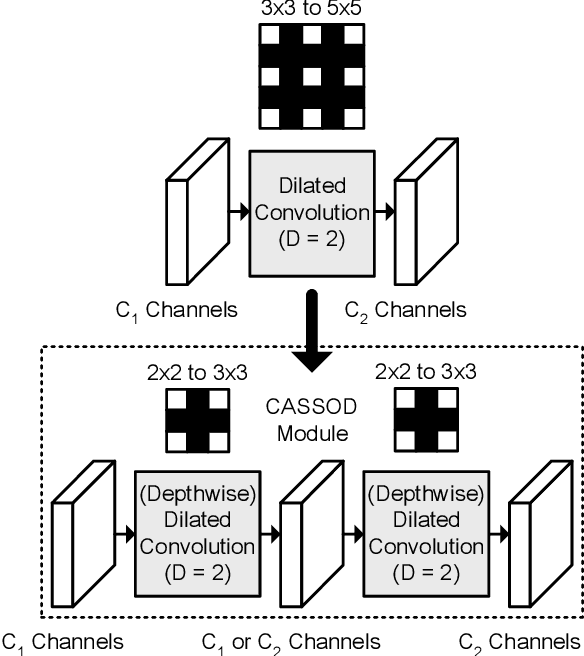

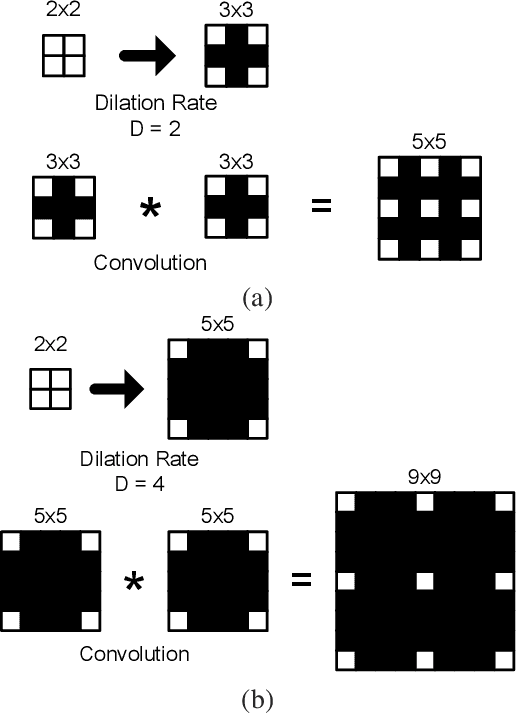
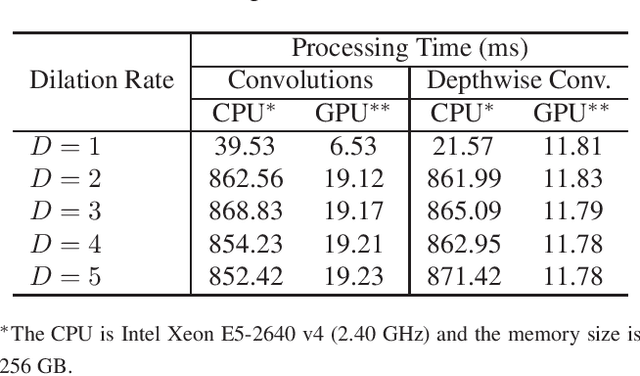
The field of view (FOV) of convolutional neural networks is highly related to the accuracy of inference. Dilated convolutions are known as an effective solution to the problems which require large FOVs. However, for general-purpose hardware or dedicated hardware, it usually takes extra time to handle dilated convolutions compared with standard convolutions. In this paper, we propose a network module, Cascaded and Separable Structure of Dilated (CASSOD) Convolution, and a special hardware system to handle the CASSOD networks efficiently. A CASSOD-Net includes multiple cascaded $2 \times 2$ dilated filters, which can be used to replace the traditional $3 \times 3$ dilated filters without decreasing the accuracy of inference. Two example applications, face detection and image segmentation, are tested with dilated convolutions and the proposed CASSOD modules. The new network for face detection achieves higher accuracy than the previous work with only 47% of filter weights in the dilated convolution layers of the context module. Moreover, the proposed hardware system can accelerate the computations of dilated convolutions, and it is 2.78 times faster than traditional hardware systems when the filter size is $3 \times 3$.
Vehicle Re-ID for Surround-view Camera System
Jun 30, 2020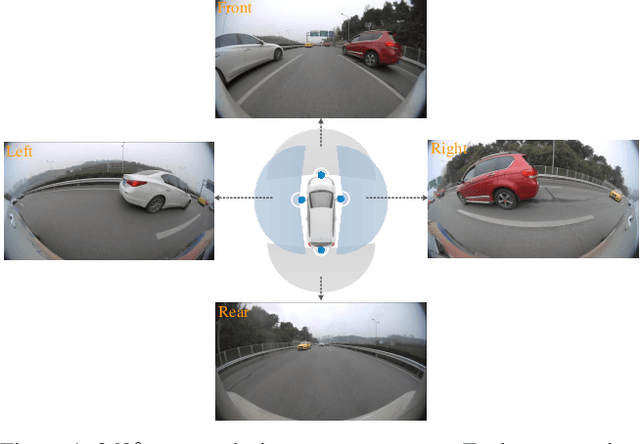
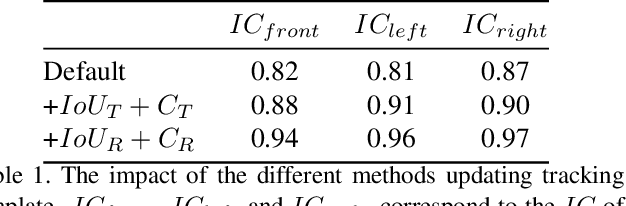

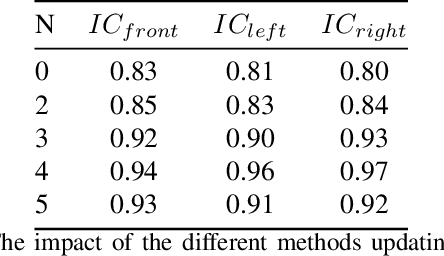
The vehicle re-identification (ReID) plays a critical role in the perception system of autonomous driving, which attracts more and more attention in recent years. However, to our best knowledge, there is no existing complete solution for the surround-view system mounted on the vehicle. In this paper, we argue two main challenges in above scenario: i) In single camera view, it is difficult to recognize the same vehicle from the past image frames due to the fisheye distortion, occlusion, truncation, etc. ii) In multi-camera view, the appearance of the same vehicle varies greatly from different camera's viewpoints. Thus, we present an integral vehicle Re-ID solution to address these problems. Specifically, we propose a novel quality evaluation mechanism to balance the effect of tracking box's drift and target's consistency. Besides, we take advantage of the Re-ID network based on attention mechanism, then combined with a spatial constraint strategy to further boost the performance between different cameras. The experiments demonstrate that our solution achieves state-of-the-art accuracy while being real-time in practice. Besides, we will release the code and annotated fisheye dataset for the benefit of community.