 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence-Aware RGB-D Face Recognition via Virtual Depth Synthesis
Mar 16, 2024



2D face recognition encounters challenges in unconstrained environments due to varying illumination, occlusion, and pose. Recent studies focus on RGB-D face recognition to improve robustness by incorporating depth information. However, collecting sufficient paired RGB-D training data is expensive and time-consuming, hindering wide deployment. In this work, we first construct a diverse depth dataset generated by 3D Morphable Models for depth model pre-training. Then, we propose a domain-independent pre-training framework that utilizes readily available pre-trained RGB and depth models to separately perform face recognition without needing additional paired data for retraining. To seamlessly integrate the two distinct networks and harness the complementary benefits of RGB and depth information for improved accuracy, we propose an innovative Adaptive Confidence Weighting (ACW). This mechanism is designed to learn confidence estimates for each modality to achieve modality fusion at the score level. Our method is simple and lightweight, only requiring ACW training beyond the backbone models. Experiments on multiple public RGB-D face recognition benchmarks demonstrate state-of-the-art performance surpassing previous methods based on depth estimation and feature fusion, validating the efficacy of our approach.
Enhancing Generalization of Invisible Facial Privacy Cloak via Gradient Accumulation
Jan 03, 2024The blooming of social media and face recognition (FR) systems has increased people's concern about privacy and security. A new type of adversarial privacy cloak (class-universal) can be applied to all the images of regular users, to prevent malicious FR systems from acquiring their identity information. In this work, we discover the optimization dilemma in the existing methods -- the local optima problem in large-batch optimization and the gradient information elimination problem in small-batch optimization. To solve these problems, we propose Gradient Accumulation (GA) to aggregate multiple small-batch gradients into a one-step iterative gradient to enhance the gradient stability and reduce the usage of quantization operations. Experiments show that our proposed method achieves high performance on the Privacy-Commons dataset against black-box face recognition models.
Gradient Attention Balance Network: Mitigating Face Recognition Racial Bias via Gradient Attention
Apr 05, 2023



Although face recognition has made impressive progress in recent years, we ignore the racial bias of the recognition system when we pursue a high level of accuracy. Previous work found that for different races, face recognition networks focus on different facial regions, and the sensitive regions of darker-skinned people are much smaller. Based on this discovery, we propose a new de-bias method based on gradient attention, called Gradient Attention Balance Network (GABN). Specifically, we use the gradient attention map (GAM) of the face recognition network to track the sensitive facial regions and make the GAMs of different races tend to be consistent through adversarial learning. This method mitigates the bias by making the network focus on similar facial regions. In addition, we also use masks to erase the Top-N sensitive facial regions, forcing the network to allocate its attention to a larger facial region. This method expands the sensitive region of darker-skinned people and further reduces the gap between GAM of darker-skinned people and GAM of Caucasians. Extensive experiments show that GABN successfully mitigates racial bias in face recognition and learns more balanced performance for people of different races.
Dive into the Resolution Augmentations and Metrics in Low Resolution Face Recognition: A Plain yet Effective New Baseline
Feb 11, 2023



Although deep learning has significantly improved Face Recognition (FR), dramatic performance deterioration may occur when processing Low Resolution (LR) faces. To alleviate this, approaches based on unified feature space are proposed with the sacrifice under High Resolution (HR) circumstances. To deal with the huge domain gap between HR and LR domains and achieve the best on both domains, we first took a closer look at the impacts of several resolution augmentations and then analyzed the difficulty of LR samples from the perspective of the model gradient produced by different resolution samples. Besides, we also find that the introduction of some resolutions could help the learning of lower resolutions. Based on these, we divide the LR samples into three difficulties according to the resolution and propose a more effective Multi-Resolution Augmentation. Then, due to the rapidly increasing domain gap as the resolution decreases, we carefully design a novel and effective metric loss based on a LogExp distance function that provides decent gradients to prevent oscillation near the convergence point or tolerance to small distance errors; it could also dynamically adjust the penalty for errors in different dimensions, allowing for more optimization of dimensions with large errors. Combining these two insights, our model could learn more general knowledge in a wide resolution range of images and balanced results can be achieved by our extremely simple framework. Moreover, the augmentations and metrics are the cornerstones of LRFR, so our method could be considered a new baseline for the LRFR task. Experiments on the LRFR datasets: SCface, XQLFW, and large-scale LRFR dataset: TinyFace demonstrate the effectiveness of our methods, while the degradation on HRFR datasets is significantly reduced.
Model and Data Agreement for Learning with Noisy Labels
Dec 02, 2022Learning with noisy labels is a vital topic for practical deep learning as models should be robust to noisy open-world datasets in the wild. The state-of-the-art noisy label learning approach JoCoR fails when faced with a large ratio of noisy labels. Moreover, selecting small-loss samples can also cause error accumulation as once the noisy samples are mistakenly selected as small-loss samples, they are more likely to be selected again. In this paper, we try to deal with error accumulation in noisy label learning from both model and data perspectives. We introduce mean point ensemble to utilize a more robust loss function and more information from unselected samples to reduce error accumulation from the model perspective. Furthermore, as the flip images have the same semantic meaning as the original images, we select small-loss samples according to the loss values of flip images instead of the original ones to reduce error accumulation from the data perspective. Extensive experiments on CIFAR-10, CIFAR-100, and large-scale Clothing1M show that our method outperforms state-of-the-art noisy label learning methods with different levels of label noise. Our method can also be seamlessly combined with other noisy label learning methods to further improve their performance and generalize well to other tasks. The code is available in https://github.com/zyh-uaiaaaa/MDA-noisy-label-learning.
SFace: Sigmoid-Constrained Hypersphere Loss for Robust Face Recognition
May 24, 2022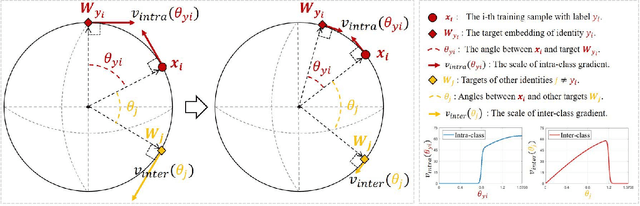
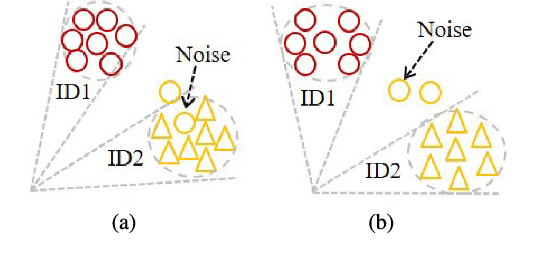
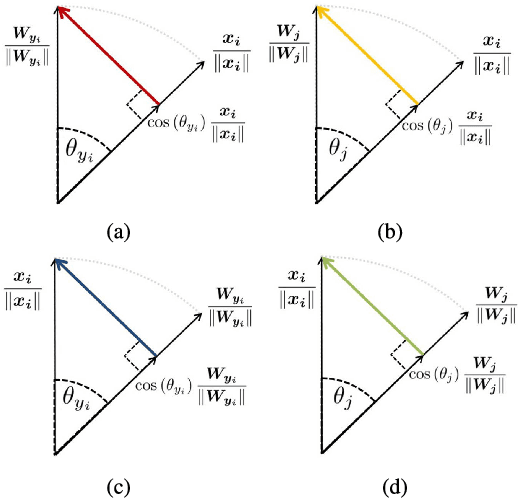
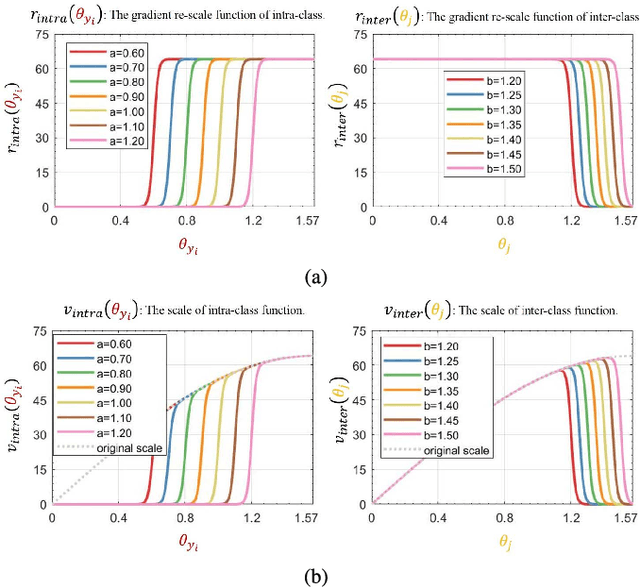
Deep face recognition has achieved great success due to large-scale training databases and rapidly developing loss functions. The existing algorithms devote to realizing an ideal idea: minimizing the intra-class distance and maximizing the inter-class distance. However, they may neglect that there are also low quality training images which should not be optimized in this strict way. Considering the imperfection of training databases, we propose that intra-class and inter-class objectives can be optimized in a moderate way to mitigate overfitting problem, and further propose a novel loss function, named sigmoid-constrained hypersphere loss (SFace). Specifically, SFace imposes intra-class and inter-class constraints on a hypersphere manifold, which are controlled by two sigmoid gradient re-scale functions respectively. The sigmoid curves precisely re-scale the intra-class and inter-class gradients so that training samples can be optimized to some degree. Therefore, SFace can make a better balance between decreasing the intra-class distances for clean examples and preventing overfitting to the label noise, and contributes more robust deep face recognition models. Extensive experiments of models trained on CASIA-WebFace, VGGFace2, and MS-Celeb-1M databases, and evaluated on several face recognition benchmarks, such as LFW, MegaFace and IJB-C databases, have demonstrated the superiority of SFace.
* 12 pages, 9 figures
CASSOD-Net: Cascaded and Separable Structures of Dilated Convolution for Embedded Vision Systems and Applications
Apr 29, 2021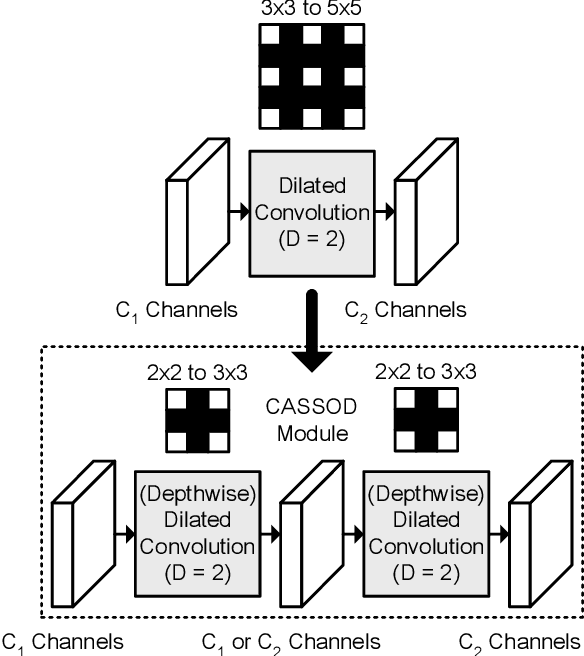

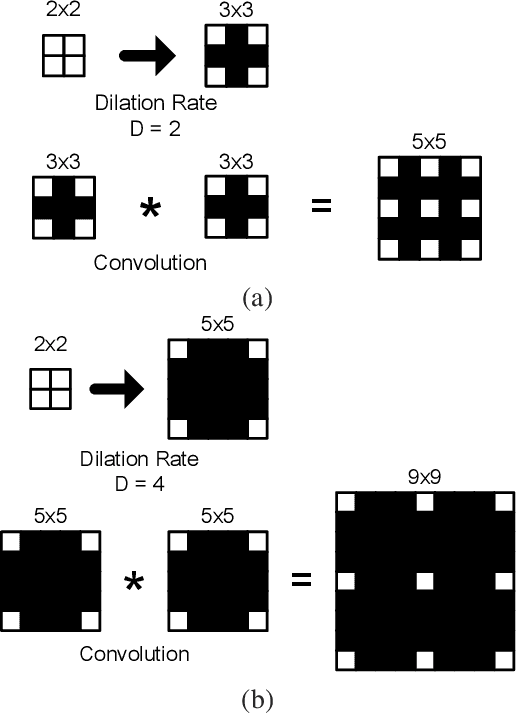
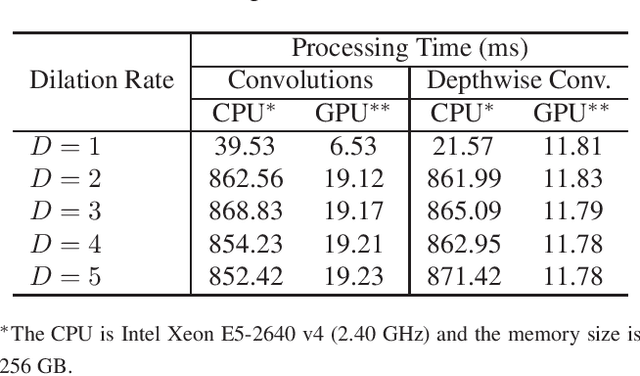
The field of view (FOV) of convolutional neural networks is highly related to the accuracy of inference. Dilated convolutions are known as an effective solution to the problems which require large FOVs. However, for general-purpose hardware or dedicated hardware, it usually takes extra time to handle dilated convolutions compared with standard convolutions. In this paper, we propose a network module, Cascaded and Separable Structure of Dilated (CASSOD) Convolution, and a special hardware system to handle the CASSOD networks efficiently. A CASSOD-Net includes multiple cascaded $2 \times 2$ dilated filters, which can be used to replace the traditional $3 \times 3$ dilated filters without decreasing the accuracy of inference. Two example applications, face detection and image segmentation, are tested with dilated convolutions and the proposed CASSOD modules. The new network for face detection achieves higher accuracy than the previous work with only 47% of filter weights in the dilated convolution layers of the context module. Moreover, the proposed hardware system can accelerate the computations of dilated convolutions, and it is 2.78 times faster than traditional hardware systems when the filter size is $3 \times 3$.
Hardware Architecture of Embedded Inference Accelerator and Analysis of Algorithms for Depthwise and Large-Kernel Convolutions
Apr 29, 2021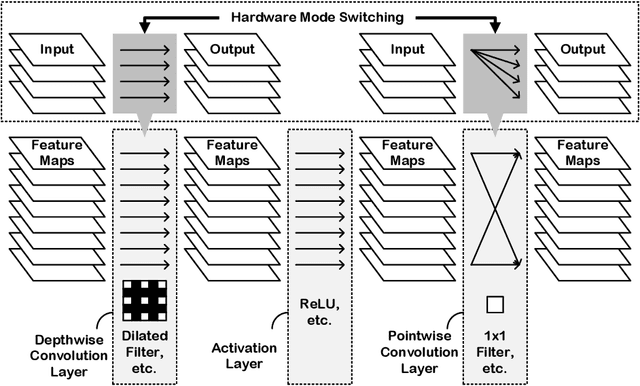
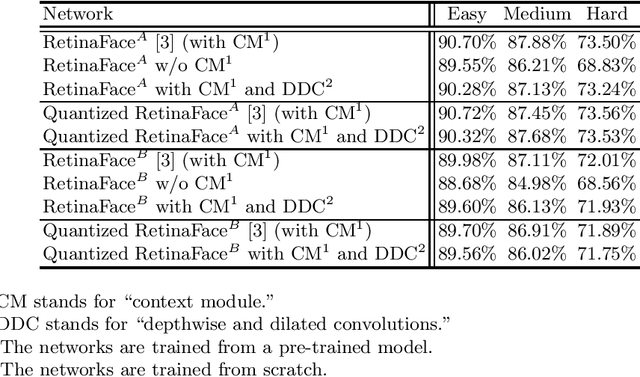
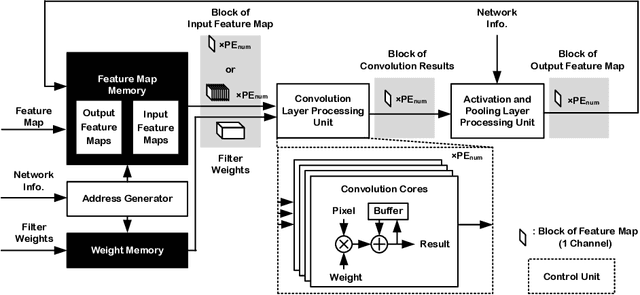
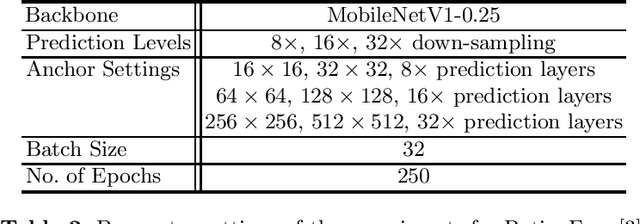
In order to handle modern convolutional neural networks (CNNs) efficiently, a hardware architecture of CNN inference accelerator is proposed to handle depthwise convolutions and regular convolutions, which are both essential building blocks for embedded-computer-vision algorithms. Different from related works, the proposed architecture can support filter kernels with different sizes with high flexibility since it does not require extra costs for intra-kernel parallelism, and it can generate convolution results faster than the architecture of the related works. The experimental results show the importance of supporting depthwise convolutions and dilated convolutions with the proposed hardware architecture. In addition to depthwise convolutions with large-kernels, a new structure called DDC layer, which includes the combination of depthwise convolutions and dilated convolutions, is also analyzed in this paper. For face detection, the computational costs decrease by 30%, and the model size decreases by 20% when the DDC layers are applied to the network. For image classification, the accuracy is increased by 1% by simply replacing $3 \times 3$ filters with $5 \times 5$ filters in depthwise convolutions.
* Camera-ready version for ECCV 2020 workshop (Embedded Vision Workshop)
Condensation-Net: Memory-Efficient Network Architecture with Cross-Channel Pooling Layers and Virtual Feature Maps
Apr 29, 2021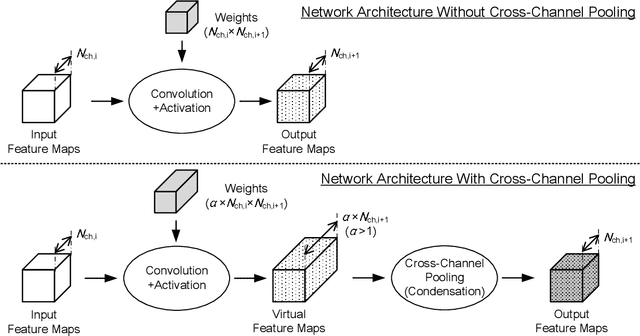

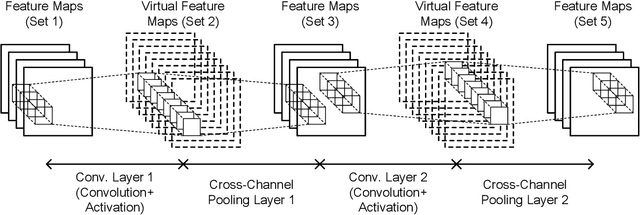
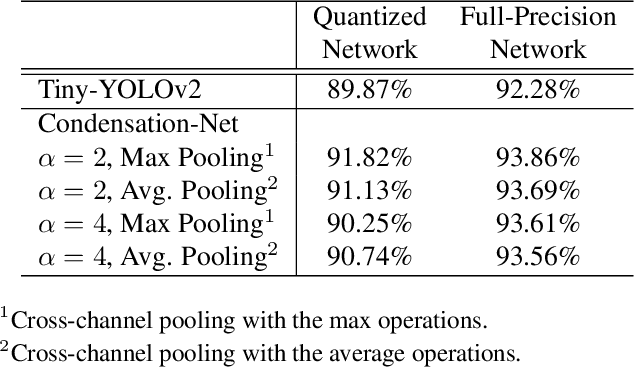
"Lightweight convolutional neural networks" is an important research topic in the field of embedded vision. To implement image recognition tasks on a resource-limited hardware platform, it is necessary to reduce the memory size and the computational cost. The contribution of this paper is stated as follows. First, we propose an algorithm to process a specific network architecture (Condensation-Net) without increasing the maximum memory storage for feature maps. The architecture for virtual feature maps saves 26.5% of memory bandwidth by calculating the results of cross-channel pooling before storing the feature map into the memory. Second, we show that cross-channel pooling can improve the accuracy of object detection tasks, such as face detection, because it increases the number of filter weights. Compared with Tiny-YOLOv2, the improvement of accuracy is 2.0% for quantized networks and 1.5% for full-precision networks when the false-positive rate is 0.1. Last but not the least, the analysis results show that the overhead to support the cross-channel pooling with the proposed hardware architecture is negligible small. The extra memory cost to support Condensation-Net is 0.2% of the total size, and the extra gate count is only 1.0% of the total size.
* Camera-ready version for CVPR 2019 workshop (Embedded Vision Workshop)
BAMSProd: A Step towards Generalizing the Adaptive Optimization Methods to Deep Binary Model
Sep 29, 2020
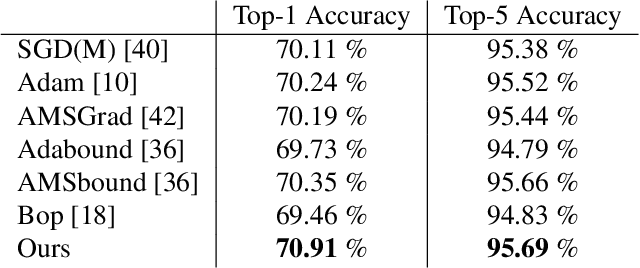

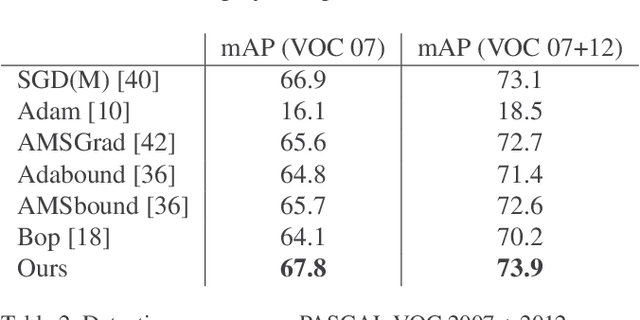
Recent methods have significantly reduced the performance degradation of Binary Neural Networks (BNNs), but guaranteeing the effective and efficient training of BNNs is an unsolved problem. The main reason is that the estimated gradients produced by the Straight-Through-Estimator (STE) mismatches with the gradients of the real derivatives. In this paper, we provide an explicit convex optimization example where training the BNNs with the traditionally adaptive optimization methods still faces the risk of non-convergence, and identify that constraining the range of gradients is critical for optimizing the deep binary model to avoid highly suboptimal solutions. For solving above issues, we propose a BAMSProd algorithm with a key observation that the convergence property of optimizing deep binary model is strongly related to the quantization errors. In brief, it employs an adaptive range constraint via an errors measurement for smoothing the gradients transition while follows the exponential moving strategy from AMSGrad to avoid errors accumulation during the optimization. The experiments verify the corollary of theoretical convergence analysis, and further demonstrate that our optimization method can speed up the convergence about 1:2x and boost the performance of BNNs to a significant level than the specific binary optimizer about 3:7%, even in a highly non-convex optimization problem.
* 10 pages, 4 figures, 2 tables