 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketchJudge: A Diagnostic Benchmark for Grading Hand-drawn Diagrams with Multimodal Large Language Models
Jan 11, 2026While Multimodal Large Language Models (MLLMs) have achieved remarkable progress in visual understanding, they often struggle when faced with the unstructured and ambiguous nature of human-generated sketches. This limitation is particularly pronounced in the underexplored task of visual grading, where models should not only solve a problem but also diagnose errors in hand-drawn diagrams. Such diagnostic capabilities depend on complex structural, semantic, and metacognitive reasoning. To bridge this gap, we introduce SketchJudge, a novel benchmark tailored for evaluating MLLMs as graders of hand-drawn STEM diagrams. SketchJudge encompasses 1,015 hand-drawn student responses across four domains: geometry, physics, charts, and flowcharts, featuring diverse stylistic variations and distinct error types. Evaluations on SketchJudge demonstrate that even advanced MLLMs lag significantly behind humans, validating the benchmark's effectiveness in exposing the fragility of current vision-language alignment in symbolic and noisy contexts. All data, code, and evaluation scripts are publicly available at https://github.com/yuhangsu82/SketchJudge.
Fake-in-Facext: Towards Fine-Grained Explainable DeepFake Analysis
Oct 23, 2025The advancement of Multimodal Large Language Models (MLLMs) has bridged the gap between vision and language tasks, enabling the implementation of Explainable DeepFake Analysis (XDFA). However, current methods suffer from a lack of fine-grained awareness: the description of artifacts in data annotation is unreliable and coarse-grained, and the models fail to support the output of connections between textual forgery explanations and the visual evidence of artifacts, as well as the input of queries for arbitrary facial regions. As a result, their responses are not sufficiently grounded in Face Visual Context (Facext). To address this limitation, we propose the Fake-in-Facext (FiFa) framework, with contributions focusing on data annotation and model construction. We first define a Facial Image Concept Tree (FICT) to divide facial images into fine-grained regional concepts, thereby obtaining a more reliable data annotation pipeline, FiFa-Annotator, for forgery explanation. Based on this dedicated data annotation, we introduce a novel Artifact-Grounding Explanation (AGE) task, which generates textual forgery explanations interleaved with segmentation masks of manipulated artifacts. We propose a unified multi-task learning architecture, FiFa-MLLM, to simultaneously support abundant multimodal inputs and outputs for fine-grained Explainable DeepFake Analysis. With multiple auxiliary supervision tasks, FiFa-MLLM can outperform strong baselines on the AGE task and achieve SOTA performance on existing XDFA datasets. The code and data will be made open-source at https://github.com/lxq1000/Fake-in-Facext.
VisioMath: Benchmarking Figure-based Mathematical Reasoning in LMMs
Jun 07, 2025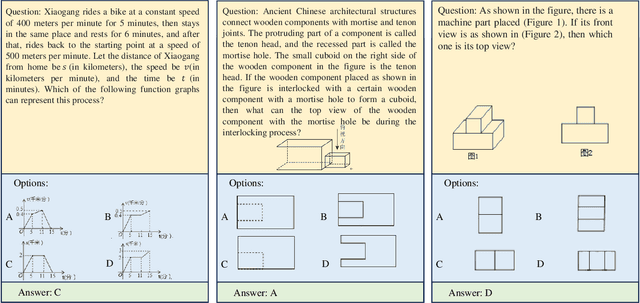
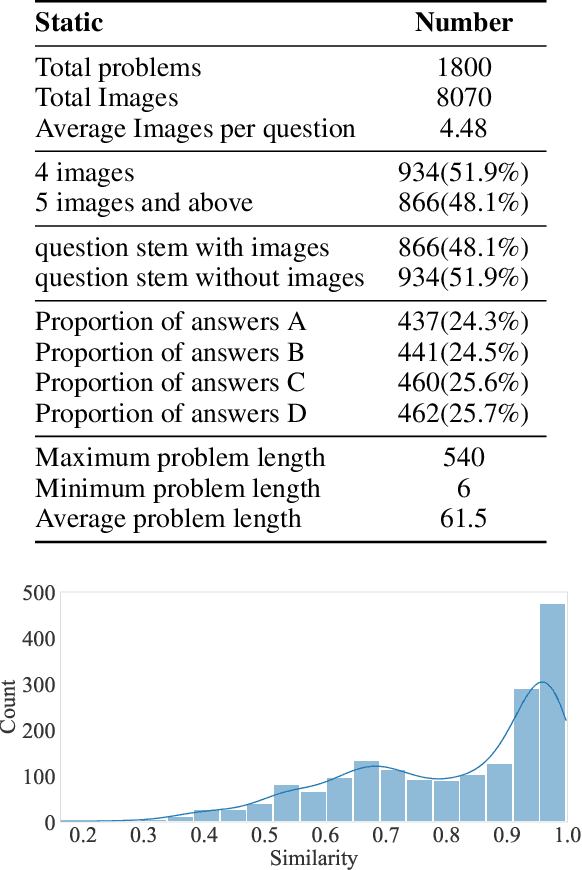
Large Multimodal Models (LMMs) have demonstrated remarkable problem-solving capabilities across various domains. However, their ability to perform mathematical reasoning when answer options are represented as images--an essential aspect of multi-image comprehension--remains underexplored. To bridge this gap, we introduce VisioMath, a benchmark designed to evaluate mathematical reasoning in multimodal contexts involving image-based answer choices. VisioMath comprises 8,070 images and 1,800 multiple-choice questions, where each answer option is an image, presenting unique challenges to existing LMMs. To the best of our knowledge, VisioMath is the first dataset specifically tailored for mathematical reasoning in image-based-option scenarios, where fine-grained distinctions between answer choices are critical for accurate problem-solving. We systematically evaluate state-of-the-art LMMs on VisioMath and find that even the most advanced models struggle with this task. Notably, GPT-4o achieves only 45.9% accuracy, underscoring the limitations of current models in reasoning over visually similar answer choices. By addressing a crucial gap in existing benchmarks, VisioMath establishes a rigorous testbed for future research, driving advancements in multimodal reasoning.
SMART: Self-Generating and Self-Validating Multi-Dimensional Assessment for LLMs' Mathematical Problem Solving
May 22, 2025
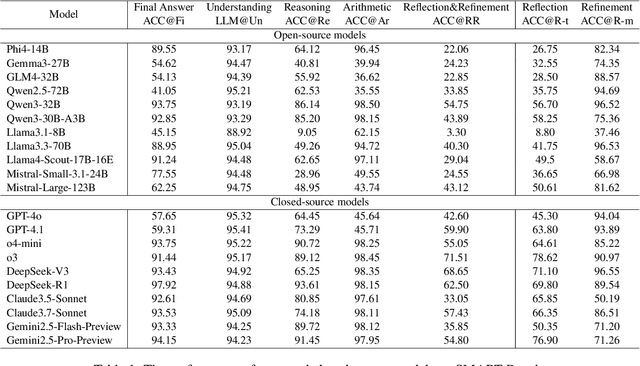

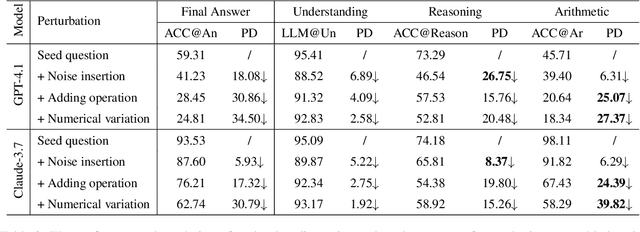
Large Language Models have achieved remarkable results on a variety of mathematical benchmarks. However, concerns remain as to whether these successes reflect genuine mathematical reasoning or superficial pattern recognition. Common evaluation metrics, such as final answer accuracy, fail to disentangle the underlying competencies involved, offering limited diagnostic value. To address these limitations, we introduce SMART: a Self-Generating and Self-Validating Multi-Dimensional Assessment Framework. SMART decomposes mathematical problem solving into four distinct dimensions: understanding, reasoning, arithmetic, and reflection \& refinement. Each dimension is evaluated independently through tailored tasks, enabling interpretable and fine-grained analysis of LLM behavior. Crucially, SMART integrates an automated self-generating and self-validating mechanism to produce and verify benchmark data, ensuring both scalability and reliability. We apply SMART to 21 state-of-the-art open- and closed-source LLMs, uncovering significant discrepancies in their abilities across different dimensions. Our findings demonstrate the inadequacy of final answer accuracy as a sole metric and motivate a new holistic metric to better capture true problem-solving capabilities. Code and benchmarks will be released upon acceptance.
Face-Human-Bench: A Comprehensive Benchmark of Face and Human Understanding for Multi-modal Assistants
Jan 05, 2025



Faces and humans are crucial elements in social interaction and are widely included in everyday photos and videos. Therefore, a deep understanding of faces and humans will enable multi-modal assistants to achieve improved response quality and broadened application scope. Currently, the multi-modal assistant community lacks a comprehensive and scientific evaluation of face and human understanding abilities. In this paper, we first propose a hierarchical ability taxonomy that includes three levels of abilities. Then, based on this taxonomy, we collect images and annotations from publicly available datasets in the face and human community and build a semi-automatic data pipeline to produce problems for the new benchmark. Finally, the obtained Face-Human-Bench comprises a development set with 900 problems and a test set with 1800 problems, supporting both English and Chinese. We conduct evaluations over 25 mainstream multi-modal large language models (MLLMs) with our Face-Human-Bench, focusing on the correlation between abilities, the impact of the relative position of targets on performance, and the impact of Chain of Thought (CoT) prompting on performance. Moreover, inspired by multi-modal agents, we also explore which abilities of MLLMs need to be supplemented by specialist models.
Unsupervised Attention Regularization Based Domain Adaptation for Oracle Character Recognition
Sep 24, 2024The study of oracle characters plays an important role in Chinese archaeology and philology. However, the difficulty of collecting and annotating real-world scanned oracle characters hinders the development of oracle character recognition. In this paper, we develop a novel unsupervised domain adaptation (UDA) method, i.e., unsupervised attention regularization net?work (UARN), to transfer recognition knowledge from labeled handprinted oracle characters to unlabeled scanned data. First, we experimentally prove that existing UDA methods are not always consistent with human priors and cannot achieve optimal performance on the target domain. For these oracle characters with flip-insensitivity and high inter-class similarity, model interpretations are not flip-consistent and class-separable. To tackle this challenge, we take into consideration visual perceptual plausibility when adapting. Specifically, our method enforces attention consistency between the original and flipped images to achieve the model robustness to flipping. Simultaneously, we constrain attention separability between the pseudo class and the most confusing class to improve the model discriminability. Extensive experiments demonstrate that UARN shows better interpretability and achieves state-of-the-art performance on Oracle-241 dataset, substantially outperforming the previously structure-texture separation network by 8.5%.
An Efficient Privacy-aware Split Learning Framework for Satellite Communications
Sep 13, 2024



In the rapidly evolving domain of satellite communications, integrating advanced machine learning techniques, particularly split learning, is crucial for enhancing data processing and model training efficiency across satellites, space stations, and ground stations. Traditional ML approaches often face significant challenges within satellite networks due to constraints such as limited bandwidth and computational resources. To address this gap, we propose a novel framework for more efficient SL in satellite communications. Our approach, Dynamic Topology Informed Pruning, namely DTIP, combines differential privacy with graph and model pruning to optimize graph neural networks for distributed learning. DTIP strategically applies differential privacy to raw graph data and prunes GNNs, thereby optimizing both model size and communication load across network tiers. Extensive experiments across diverse datasets demonstrate DTIP's efficacy in enhancing privacy, accuracy, and computational efficiency. Specifically, on Amazon2M dataset, DTIP maintains an accuracy of 0.82 while achieving a 50% reduction in floating-point operations per second. Similarly, on ArXiv dataset, DTIP achieves an accuracy of 0.85 under comparable conditions. Our framework not only significantly improves the operational efficiency of satellite communications but also establishes a new benchmark in privacy-aware distributed learning, potentially revolutionizing data handling in space-based networks.
Confidence-Aware RGB-D Face Recognition via Virtual Depth Synthesis
Mar 16, 2024



2D face recognition encounters challenges in unconstrained environments due to varying illumination, occlusion, and pose. Recent studies focus on RGB-D face recognition to improve robustness by incorporating depth information. However, collecting sufficient paired RGB-D training data is expensive and time-consuming, hindering wide deployment. In this work, we first construct a diverse depth dataset generated by 3D Morphable Models for depth model pre-training. Then, we propose a domain-independent pre-training framework that utilizes readily available pre-trained RGB and depth models to separately perform face recognition without needing additional paired data for retraining. To seamlessly integrate the two distinct networks and harness the complementary benefits of RGB and depth information for improved accuracy, we propose an innovative Adaptive Confidence Weighting (ACW). This mechanism is designed to learn confidence estimates for each modality to achieve modality fusion at the score level. Our method is simple and lightweight, only requiring ACW training beyond the backbone models. Experiments on multiple public RGB-D face recognition benchmarks demonstrate state-of-the-art performance surpassing previous methods based on depth estimation and feature fusion, validating the efficacy of our approach.
Faceptor: A Generalist Model for Face Perception
Mar 14, 2024



With the comprehensive research conducted on various face analysis tasks, there is a growing interest among researchers to develop a unified approach to face perception. Existing methods mainly discuss unified representation and training, which lack task extensibility and application efficiency. To tackle this issue, we focus on the unified model structure, exploring a face generalist model. As an intuitive design, Naive Faceptor enables tasks with the same output shape and granularity to share the structural design of the standardized output head, achieving improved task extensibility. Furthermore, Faceptor is proposed to adopt a well-designed single-encoder dual-decoder architecture, allowing task-specific queries to represent new-coming semantics. This design enhances the unification of model structure while improving application efficiency in terms of storage overhead. Additionally, we introduce Layer-Attention into Faceptor, enabling the model to adaptively select features from optimal layers to perform the desired tasks. Through joint training on 13 face perception datasets, Faceptor achieves exceptional performance in facial landmark localization, face parsing, age estimation, expression recognition, binary attribute classification, and face recognition, achieving or surpassing specialized methods in most tasks. Our training framework can also be applied to auxiliary supervised learning, significantly improving performance in data-sparse tasks such as age estimation and expression recognition. The code and models will be made publicly available at https://github.com/lxq1000/Faceptor.
Marginal Debiased Network for Fair Visual Recognition
Jan 04, 2024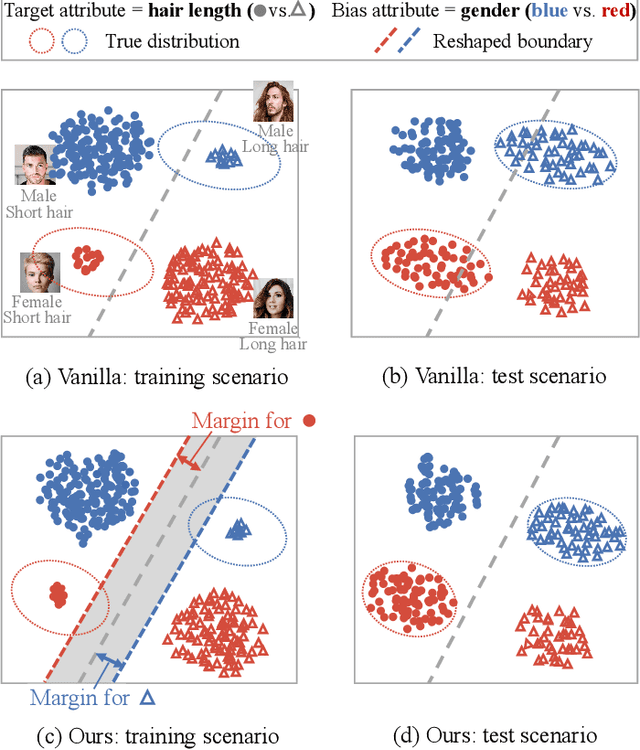



Deep neural networks (DNNs) are often prone to learn the spurious correlations between target classes and bias attributes, like gender and race, inherent in a major portion of training data (bias-aligned samples), thus showing unfair behavior and arising controversy in the modern pluralistic and egalitarian society. In this paper, we propose a novel marginal debiased network (MDN) to learn debiased representations. More specifically, a marginal softmax loss (MSL) is designed by introducing the idea of margin penalty into the fairness problem, which assigns a larger margin for bias-conflicting samples (data without spurious correlations) than for bias-aligned ones, so as to deemphasize the spurious correlations and improve generalization on unbiased test criteria. To determine the margins, our MDN is optimized through a meta learning framework. We propose a meta equalized loss (MEL) to perceive the model fairness, and adaptively update the margin parameters by metaoptimization which requires the trained model guided by the optimal margins should minimize MEL computed on an unbiased meta-validation set. Extensive experiments on BiasedMNIST, Corrupted CIFAR-10, CelebA and UTK-Face datasets demonstrate that our MDN can achieve a remarkable performance on under-represented samples and obtain superior debiased results against the previous approaches.