 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-Local Monte Carlo Tree Search in Vision-Language Models for Text-to-3D Indoor Scene Generation
Jun 04, 2026Large Vision-Language Models have achieved significant reasoning performance in various tasks.However, there are few studies on text-to-3D indoor scene generation with LVLMs. The main challenge is that prevailing LVLM-based methods employ chain-of-thought sequential decision mechanisms that cannot revise earlier decisions, causing error propagation.In this paper, we consider the task as a planning problem constrained by spatial and layout commonsense.To solve this problem, we model it as a tree search problem with global and local trees, which differs from existing sequential decision-making approaches.In the global tree, we place each object iteratively and explore multiple attempts like humans furnishing a room, where the problem space is represented as a tree.To effectively search the tree, we propose a hierarchical scene representation and a PRM-guided MCTS method.The hierarchical representation abstracts a scene into room level, region level, floor object level, and supported object level.The PRM-guided MCTS method uses the PRM to prune unnecessary branches and the MCTS algorithm to balance exploration and exploitation to get an optimal solution with fewer attempts.In the local tree, it further decomposes the placement of each object into finer sub-steps, including the specific placement parameters.To make the whole appearance of the scene consistent, we leverage pre-trained diffusion image generative models to predict textures for all the objects in the scene.As existing benchmarks for text-to-3D indoor scene generation remain limited in scale and diversity, we collect a new large-scale diverse dataset that contains 65 scene types and 3,250 instructions with diverse sizes, layouts, and styles, named 3DTindo-bench, to better assess the capability of the state-of-the-art models. Our experiments show that our method generates more realistic 3D scenes than state-of-the-art approaches.
Restoring Initial Noise Sensitivity in Text-to-Image Distillation via Geometric Alignment
Jun 01, 2026Generative distillation significantly accelerates text-to-image (T2I) generation by compressing multi-step trajectories into few-step student models while preserving perceptual quality. However, existing methods primarily optimize efficiency and output fidelity, often neglecting critical properties of the original trajectory. In this work, we identify a key missing property: sensitivity to initial noise, whose degradation impairs downstream control methods relying on noise-based optimization and manipulation. We trace this issue to standard distillation objectives that enforce pointwise output alignment, inadvertently flattening the input-output landscape and suppressing the teacher's local geometric structure. To address this, we propose Geometry-Aware Distillation (GAD), a sensitivity-preserving framework that aligns the local functional behavior of teacher and student models. Specifically, GAD matches Jacobian-vector products with respect to input noise, enabling the student to reproduce the teacher's differential response to perturbations. Extensive experiments across multiple T2I paradigms and noise-driven control tasks demonstrate that GAD significantly restores sensitivity and improves diversity while maintaining high visual fidelity. Code is available at https://github.com/Hannah1102/GAD.
Active Exploring like a Pigeon: Reinforcing Spatial Reasoning via Agentic Vision-Language Models
Jun 01, 2026Enabling Vision-Language Models (VLMs) to perform spatial reasoning remains challenging. Existing approaches treat VLMs as passive observers, which is difficult for real-world applications. Moreover, reinforcement learning methods rely on sparse rewards, limiting their effectiveness for complex reasoning tasks. Inspired by pigeons' building and exploiting cognitive maps for navigation, we propose a novel agentic pipeline for spatial reasoning. First, we introduce a new \emph{dynamic cognitive map} parameterizing scene layout as object positions and orientations, serving as persistent memory for new observations. Second, we propose a novel \emph{Spatial Assertion Codes (SAC)}, Python expressions programmatically describing spatial relationships. By collaborating with the dynamic cognitive map, SAC enables verification of intermediate reasoning steps, providing dense reward signals. We optimize the model via supervised and reinforcement finetuning. Experiments on the MindCube benchmark demonstrate state-of-the-art performance with \emph{80.5\%} overall accuracy, outperforming the best current method by \emph{29.5} accuracy points (a relative improvement of \emph{53.2\%}) on the challenging \textsc{Rotation} subset. Our code and data are open-sourced at https://github.com/dw-dengwei/active-spatial-reasoning.git.
Inference-Time Alignment of Diffusion Models via Trust-Region Iterative Twisted Sequential Monte Carlo
May 24, 2026We study inference-time alignment for diffusion-based generative models, aiming to steer a base model toward high-reward outputs without updating its weights. Recent Sequential Monte Carlo (SMC)-based steering methods approximate reward-tilted target distributions in a principled way, but their proposals remain largely tied to the base sampler. Since reward information is mainly used after propagation through particle reweighting and resampling, these methods can require large particle budgets and suffer from weight degeneracy and high-variance estimates. One way to reduce variance and improve particle efficiency is to iteratively learn twisting functions that provide look-ahead guidance, as in twisted SMC. However, existing learnable twisting methods are developed mainly for classical sequential inference and can be unstable when applied to diffusion-based alignment with high-dimensional state spaces and terminal, noisy, or black-box rewards. We propose Trust-Region Iterative Twisted Sequential Monte Carlo (TRI-TSMC), a trust-region framework for learning twisting functions in SMC-based inference-time alignment. Each iteration computes an exact KL-constrained update in path space, which admits a closed-form solution by tempered importance reweighting, and projects this target back to the parameterized twisted family by weighted maximum likelihood. Theoretically, we formalize the value-function interpretation of the optimal twisting function and show that it yields a zero-variance sampler. We prove that the trust-region update follows an escort path toward the target distribution, that the weighted maximum-likelihood update is a forward-KL projection, and that the path reduces residual importance-weight variance. Empirically, TRI-TSMC improves primary alignment objectives on discrete diffusion text generation and text-to-image generation under matched inference-time budgets.
The Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
The Second Challenge on Real-World Face Restoration at NTIRE 2026: Methods and Results
Apr 12, 2026This paper provides a review of the NTIRE 2026 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural and realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. Performance is evaluated using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 96 registrants, with 10 teams submitting valid models; ultimately, 9 teams achieved valid scores in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
Index-ASR Technical Report
Dec 31, 2025Automatic speech recognition (ASR) has witnessed remarkable progress in recent years, largely driven by the emergence of LLM-based ASR paradigm. Despite their strong performance on a variety of open-source benchmarks, existing LLM-based ASR systems still suffer from two critical limitations. First, they are prone to hallucination errors, often generating excessively long and repetitive outputs that are not well grounded in the acoustic input. Second, they provide limited support for flexible and fine-grained contextual customization. To address these challenges, we propose Index-ASR, a large-scale LLM-based ASR system designed to simultaneously enhance robustness and support customizable hotword recognition. The core idea of Index-ASR lies in the integration of LLM and large-scale training data enriched with background noise and contextual information. Experimental results show that our Index-ASR achieves strong performance on both open-source benchmarks and in-house test sets, highlighting its robustness and practicality for real-world ASR applications.
JoyVoice: Long-Context Conditioning for Anthropomorphic Multi-Speaker Conversational Synthesis
Dec 22, 2025Large speech generation models are evolving from single-speaker, short sentence synthesis to multi-speaker, long conversation geneartion. Current long-form speech generation models are predominately constrained to dyadic, turn-based interactions. To address this, we introduce JoyVoice, a novel anthropomorphic foundation model designed for flexible, boundary-free synthesis of up to eight speakers. Unlike conventional cascaded systems, JoyVoice employs a unified E2E-Transformer-DiT architecture that utilizes autoregressive hidden representations directly for diffusion inputs, enabling holistic end-to-end optimization. We further propose a MM-Tokenizer operating at a low bitrate of 12.5 Hz, which integrates multitask semantic and MMSE losses to effectively model both semantic and acoustic information. Additionally, the model incorporates robust text front-end processing via large-scale data perturbation. Experiments show that JoyVoice achieves state-of-the-art results in multilingual generation (Chinese, English, Japanese, Korean) and zero-shot voice cloning. JoyVoice achieves top-tier results on both the Seed-TTS-Eval Benchmark and multi-speaker long-form conversational voice cloning tasks, demonstrating superior audio quality and generalization. It achieves significant improvements in prosodic continuity for long-form speech, rhythm richness in multi-speaker conversations, paralinguistic naturalness, besides superior intelligibility. We encourage readers to listen to the demo at https://jea-speech.github.io/JoyVoice
Rethinking Langevin Thompson Sampling from A Stochastic Approximation Perspective
Oct 06, 2025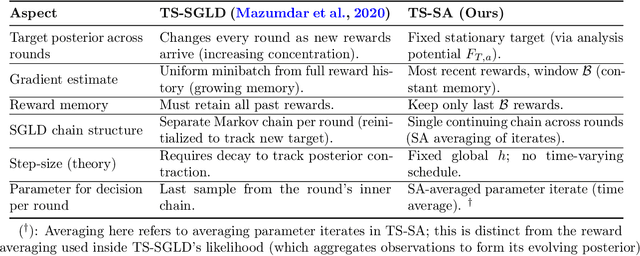


Most existing approximate Thompson Sampling (TS) algorithms for multi-armed bandits use Stochastic Gradient Langevin Dynamics (SGLD) or its variants in each round to sample from the posterior, relaxing the need for conjugacy assumptions between priors and reward distributions in vanilla TS. However, they often require approximating a different posterior distribution in different round of the bandit problem. This requires tricky, round-specific tuning of hyperparameters such as dynamic learning rates, causing challenges in both theoretical analysis and practical implementation. To alleviate this non-stationarity, we introduce TS-SA, which incorporates stochastic approximation (SA) within the TS framework. In each round, TS-SA constructs a posterior approximation only using the most recent reward(s), performs a Langevin Monte Carlo (LMC) update, and applies an SA step to average noisy proposals over time. This can be interpreted as approximating a stationary posterior target throughout the entire algorithm, which further yields a fixed step-size, a unified convergence analysis framework, and improved posterior estimates through temporal averaging. We establish near-optimal regret bounds for TS-SA, with a simplified and more intuitive theoretical analysis enabled by interpreting the entire algorithm as a simulation of a stationary SGLD process. Our empirical results demonstrate that even a single-step Langevin update with certain warm-up outperforms existing methods substantially on bandit tasks.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.