 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndexTTS 2.5 Technical Report
Jan 08, 2026In prior work, we introduced IndexTTS 2, a zero-shot neural text-to-speech foundation model comprising two core components: a transformer-based Text-to-Semantic (T2S) module and a non-autoregressive Semantic-to-Mel (S2M) module, which together enable faithful emotion replication and establish the first autoregressive duration-controllable generative paradigm. Building upon this, we present IndexTTS 2.5, which significantly enhances multilingual coverage, inference speed, and overall synthesis quality through four key improvements: 1) Semantic Codec Compression: we reduce the semantic codec frame rate from 50 Hz to 25 Hz, halving sequence length and substantially lowering both training and inference costs; 2) Architectural Upgrade: we replace the U-DiT-based backbone of the S2M module with a more efficient Zipformer-based modeling architecture, achieving notable parameter reduction and faster mel-spectrogram generation; 3) Multilingual Extension: We propose three explicit cross-lingual modeling strategies, boundary-aware alignment, token-level concatenation, and instruction-guided generation, establishing practical design principles for zero-shot multilingual emotional TTS that supports Chinese, English, Japanese, and Spanish, and enables robust emotion transfer even without target-language emotional training data; 4) Reinforcement Learning Optimization: we apply GRPO in post-training of the T2S module, improving pronunciation accuracy and natrualness. Experiments show that IndexTTS 2.5 not only supports broader language coverage but also replicates emotional prosody in unseen languages under the same zero-shot setting. IndexTTS 2.5 achieves a 2.28 times improvement in RTF while maintaining comparable WER and speaker similarity to IndexTTS 2.
IndexTTS: An Industrial-Level Controllable and Efficient Zero-Shot Text-To-Speech System
Feb 08, 2025



Recently, large language model (LLM) based text-to-speech (TTS) systems have gradually become the mainstream in the industry due to their high naturalness and powerful zero-shot voice cloning capabilities.Here, we introduce the IndexTTS system, which is mainly based on the XTTS and Tortoise model. We add some novel improvements. Specifically, in Chinese scenarios, we adopt a hybrid modeling method that combines characters and pinyin, making the pronunciations of polyphonic characters and long-tail characters controllable. We also performed a comparative analysis of the Vector Quantization (VQ) with Finite-Scalar Quantization (FSQ) for codebook utilization of acoustic speech tokens. To further enhance the effect and stability of voice cloning, we introduce a conformer-based speech conditional encoder and replace the speechcode decoder with BigVGAN2. Compared with XTTS, it has achieved significant improvements in naturalness, content consistency, and zero-shot voice cloning. As for the popular TTS systems in the open-source, such as Fish-Speech, CosyVoice2, FireRedTTS and F5-TTS, IndexTTS has a relatively simple training process, more controllable usage, and faster inference speed. Moreover, its performance surpasses that of these systems. Our demos are available at https://index-tts.github.io.
BART based semantic correction for Mandarin automatic speech recognition system
Mar 26, 2021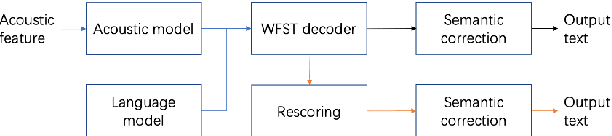
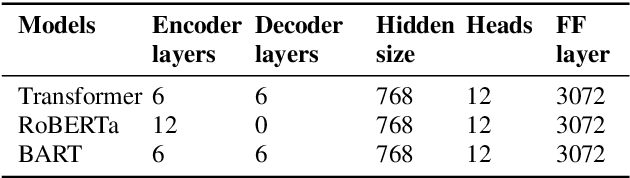
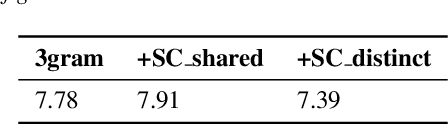

Although automatic speech recognition (ASR) systems achieved significantly improvements in recent years, spoken language recognition error occurs which can be easily spotted by human beings. Various language modeling techniques have been developed on post recognition tasks like semantic correction. In this paper, we propose a Transformer based semantic correction method with pretrained BART initialization, Experiments on 10000 hours Mandarin speech dataset show that character error rate (CER) can be effectively reduced by 21.7% relatively compared to our baseline ASR system. Expert evaluation demonstrates that actual improvement of our model surpasses what CER indicates.