 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Spectral Mapping With Attention Based Convolution Recurrent Neural Network for Speech Enhancement
Apr 15, 2021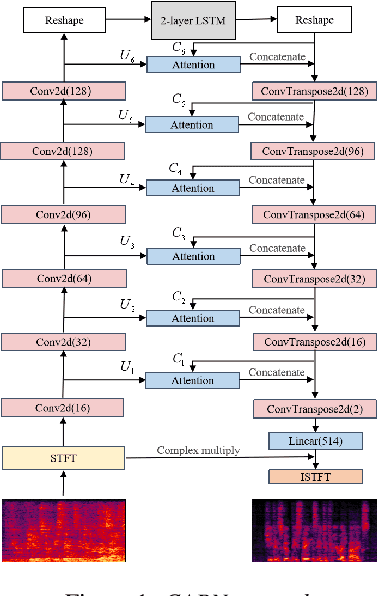
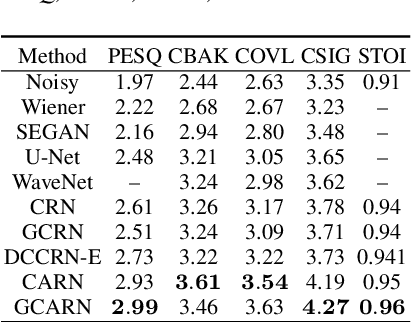
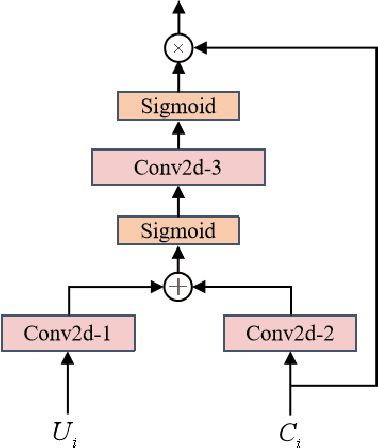
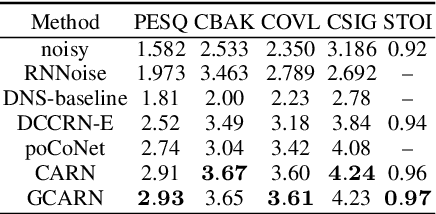
Speech enhancement has benefited from the success of deep learning in terms of intelligibility and perceptual quality. Conventional time-frequency (TF) domain methods focus on predicting TF-masks or speech spectrum,via a naive convolution neural network or recurrent neural network.Some recent studies were based on Complex spectral Mapping convolution recurrent neural network (CRN) . These models skiped directly from encoder layers' output and decoder layers' input ,which maybe thoughtless. We proposed an attention mechanism based skip connection between encoder and decoder layers,namely Complex Spectral Mapping With Attention Based Convolution Recurrent Neural Network (CARN).Compared with CRN model,the proposed CARN model improved more than 10% relatively at several metrics such as PESQ,CBAK,COVL,CSIG and son,and outperformed the place 1st model in both real time and non-real time track of the DNS Challenge 2020 at these metrics.
BART based semantic correction for Mandarin automatic speech recognition system
Mar 26, 2021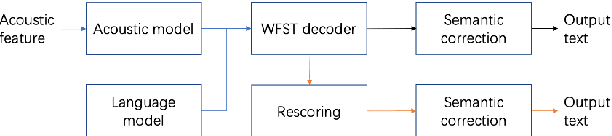
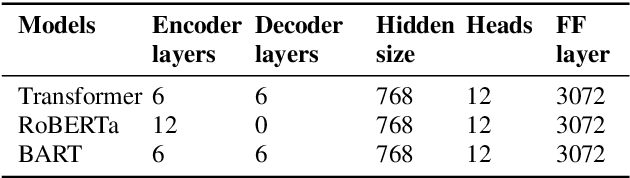
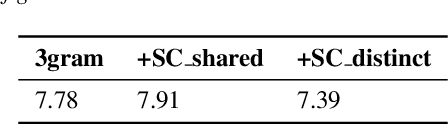

Although automatic speech recognition (ASR) systems achieved significantly improvements in recent years, spoken language recognition error occurs which can be easily spotted by human beings. Various language modeling techniques have been developed on post recognition tasks like semantic correction. In this paper, we propose a Transformer based semantic correction method with pretrained BART initialization, Experiments on 10000 hours Mandarin speech dataset show that character error rate (CER) can be effectively reduced by 21.7% relatively compared to our baseline ASR system. Expert evaluation demonstrates that actual improvement of our model surpasses what CER indicates.