Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBART based semantic correction for Mandarin automatic speech recognition system
Paper and Code
Mar 26, 2021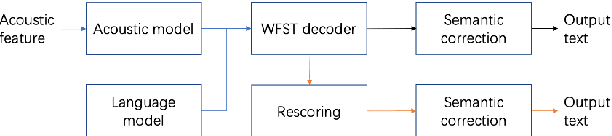
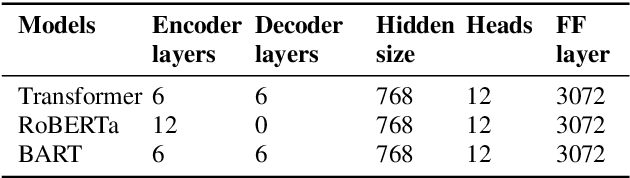
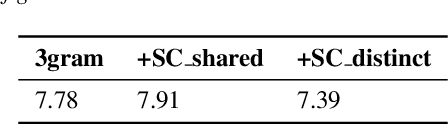

Although automatic speech recognition (ASR) systems achieved significantly improvements in recent years, spoken language recognition error occurs which can be easily spotted by human beings. Various language modeling techniques have been developed on post recognition tasks like semantic correction. In this paper, we propose a Transformer based semantic correction method with pretrained BART initialization, Experiments on 10000 hours Mandarin speech dataset show that character error rate (CER) can be effectively reduced by 21.7% relatively compared to our baseline ASR system. Expert evaluation demonstrates that actual improvement of our model surpasses what CER indicates.
* submitted to INTERSPEECH2021
View paper on