 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Singing Style Conversion with Boundary-Aware Information Bottleneck
Apr 07, 2026This paper presents the submission of the S4 team to the Singing Voice Conversion Challenge 2025 (SVCC2025)-a novel singing style conversion system that advances fine-grained style conversion and control within in-domain settings. To address the critical challenges of style leakage, dynamic rendering, and high-fidelity generation with limited data, we introduce three key innovations: a boundary-aware Whisper bottleneck that pools phoneme-span representations to suppress residual source style while preserving linguistic content; an explicit frame-level technique matrix, enhanced by targeted F0 processing during inference, for stable and distinct dynamic style rendering; and a perceptually motivated high-frequency band completion strategy that leverages an auxiliary standard 48kHz SVC model to augment the high-frequency spectrum, thereby overcoming data scarcity without overfitting. In the official SVCC2025 subjective evaluation, our system achieves the best naturalness performance among all submissions while maintaining competitive results in speaker similarity and technique control, despite using significantly less extra singing data than other top-performing systems. Audio samples are available online.
IndexTTS 2.5 Technical Report
Jan 08, 2026In prior work, we introduced IndexTTS 2, a zero-shot neural text-to-speech foundation model comprising two core components: a transformer-based Text-to-Semantic (T2S) module and a non-autoregressive Semantic-to-Mel (S2M) module, which together enable faithful emotion replication and establish the first autoregressive duration-controllable generative paradigm. Building upon this, we present IndexTTS 2.5, which significantly enhances multilingual coverage, inference speed, and overall synthesis quality through four key improvements: 1) Semantic Codec Compression: we reduce the semantic codec frame rate from 50 Hz to 25 Hz, halving sequence length and substantially lowering both training and inference costs; 2) Architectural Upgrade: we replace the U-DiT-based backbone of the S2M module with a more efficient Zipformer-based modeling architecture, achieving notable parameter reduction and faster mel-spectrogram generation; 3) Multilingual Extension: We propose three explicit cross-lingual modeling strategies, boundary-aware alignment, token-level concatenation, and instruction-guided generation, establishing practical design principles for zero-shot multilingual emotional TTS that supports Chinese, English, Japanese, and Spanish, and enables robust emotion transfer even without target-language emotional training data; 4) Reinforcement Learning Optimization: we apply GRPO in post-training of the T2S module, improving pronunciation accuracy and natrualness. Experiments show that IndexTTS 2.5 not only supports broader language coverage but also replicates emotional prosody in unseen languages under the same zero-shot setting. IndexTTS 2.5 achieves a 2.28 times improvement in RTF while maintaining comparable WER and speaker similarity to IndexTTS 2.
SYKI-SVC: Advancing Singing Voice Conversion with Post-Processing Innovations and an Open-Source Professional Testset
Jan 06, 2025Singing voice conversion aims to transform a source singing voice into that of a target singer while preserving the original lyrics, melody, and various vocal techniques. In this paper, we propose a high-fidelity singing voice conversion system. Our system builds upon the SVCC T02 framework and consists of three key components: a feature extractor, a voice converter, and a post-processor. The feature extractor utilizes the ContentVec and Whisper models to derive F0 contours and extract speaker-independent linguistic features from the input singing voice. The voice converter then integrates the extracted timbre, F0, and linguistic content to synthesize the target speaker's waveform. The post-processor augments high-frequency information directly from the source through simple and effective signal processing to enhance audio quality. Due to the lack of a standardized professional dataset for evaluating expressive singing conversion systems, we have created and made publicly available a specialized test set. Comparative evaluations demonstrate that our system achieves a remarkably high level of naturalness, and further analysis confirms the efficacy of our proposed system design.
FGCL: Fine-grained Contrastive Learning For Mandarin Stuttering Event Detection
Oct 08, 2024
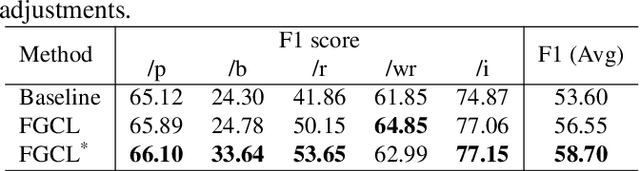
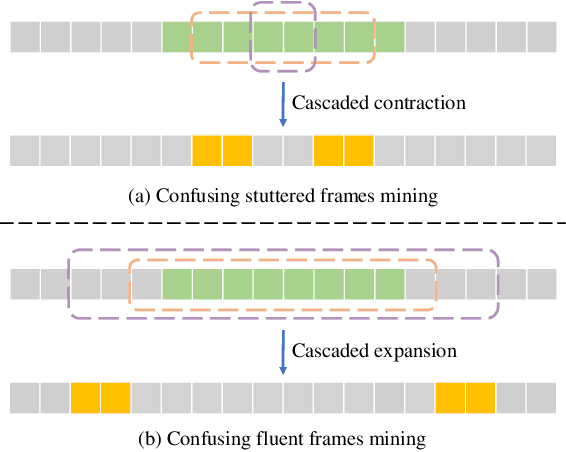
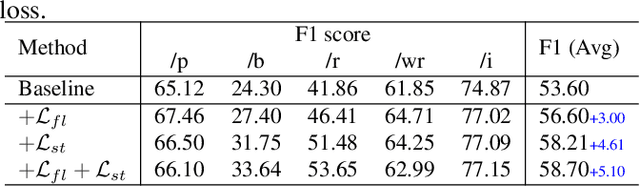
This paper presents the T031 team's approach to the StutteringSpeech Challenge in SLT2024. Mandarin Stuttering Event Detection (MSED) aims to detect instances of stuttering events in Mandarin speech. We propose a detailed acoustic analysis method to improve the accuracy of stutter detection by capturing subtle nuances that previous Stuttering Event Detection (SED) techniques have overlooked. To this end, we introduce the Fine-Grained Contrastive Learning (FGCL) framework for MSED. Specifically, we model the frame-level probabilities of stuttering events and introduce a mining algorithm to identify both easy and confusing frames. Then, we propose a stutter contrast loss to enhance the distinction between stuttered and fluent speech frames, thereby improving the discriminative capability of stuttered feature embeddings. Extensive evaluations on English and Mandarin datasets demonstrate the effectiveness of FGCL, achieving a significant increase of over 5.0% in F1 score on Mandarin data.
VITS-based Singing Voice Conversion System with DSPGAN post-processing for SVCC2023
Oct 08, 2023This paper presents the T02 team's system for the Singing Voice Conversion Challenge 2023 (SVCC2023). Our system entails a VITS-based SVC model, incorporating three modules: a feature extractor, a voice converter, and a post-processor. Specifically, the feature extractor provides F0 contours and extracts speaker-independent linguistic content from the input singing voice by leveraging a HuBERT model. The voice converter is employed to recompose the speaker timbre, F0, and linguistic content to generate the waveform of the target speaker. Besides, to further improve the audio quality, a fine-tuned DSPGAN vocoder is introduced to re-synthesise the waveform. Given the limited target speaker data, we utilize a two-stage training strategy to adapt the base model to the target speaker. During model adaptation, several tricks, such as data augmentation and joint training with auxiliary singer data, are involved. Official challenge results show that our system achieves superior performance, especially in the cross-domain task, ranking 1st and 2nd in naturalness and similarity, respectively. Further ablation justifies the effectiveness of our system design.