 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Dubbing: End-to-End Auto-Audiobook System with Text-to-Timbre and Context-Aware Instruct-TTS
Sep 19, 2025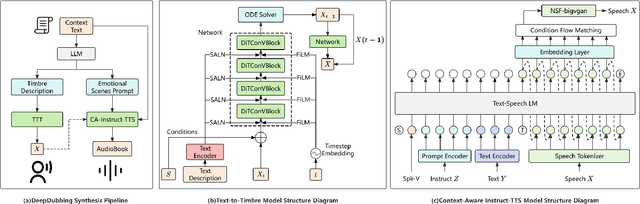


The pipeline for multi-participant audiobook production primarily consists of three stages: script analysis, character voice timbre selection, and speech synthesis. Among these, script analysis can be automated with high accuracy using NLP models, whereas character voice timbre selection still relies on manual effort. Speech synthesis uses either manual dubbing or text-to-speech (TTS). While TTS boosts efficiency, it struggles with emotional expression, intonation control, and contextual scene adaptation. To address these challenges, we propose DeepDubbing, an end-to-end automated system for multi-participant audiobook production. The system comprises two main components: a Text-to-Timbre (TTT) model and a Context-Aware Instruct-TTS (CA-Instruct-TTS) model. The TTT model generates role-specific timbre embeddings conditioned on text descriptions. The CA-Instruct-TTS model synthesizes expressive speech by analyzing contextual dialogue and incorporating fine-grained emotional instructions. This system enables the automated generation of multi-participant audiobooks with both timbre-matched character voices and emotionally expressive narration, offering a novel solution for audiobook production.
CycleFlow: Leveraging Cycle Consistency in Flow Matching for Speaker Style Adaptation
Jan 03, 2025Voice Conversion (VC) aims to convert the style of a source speaker, such as timbre and pitch, to the style of any target speaker while preserving the linguistic content. However, the ground truth of the converted speech does not exist in a non-parallel VC scenario, which induces the train-inference mismatch problem. Moreover, existing methods still have an inaccurate pitch and low speaker adaptation quality, there is a significant disparity in pitch between the source and target speaker style domains. As a result, the models tend to generate speech with hoarseness, posing challenges in achieving high-quality voice conversion. In this study, we propose CycleFlow, a novel VC approach that leverages cycle consistency in conditional flow matching (CFM) for speaker timbre adaptation training on non-parallel data. Furthermore, we design a Dual-CFM based on VoiceCFM and PitchCFM to generate speech and improve speaker pitch adaptation quality. Experiments show that our method can significantly improve speaker similarity, generating natural and higher-quality speech.
VITS-based Singing Voice Conversion System with DSPGAN post-processing for SVCC2023
Oct 08, 2023This paper presents the T02 team's system for the Singing Voice Conversion Challenge 2023 (SVCC2023). Our system entails a VITS-based SVC model, incorporating three modules: a feature extractor, a voice converter, and a post-processor. Specifically, the feature extractor provides F0 contours and extracts speaker-independent linguistic content from the input singing voice by leveraging a HuBERT model. The voice converter is employed to recompose the speaker timbre, F0, and linguistic content to generate the waveform of the target speaker. Besides, to further improve the audio quality, a fine-tuned DSPGAN vocoder is introduced to re-synthesise the waveform. Given the limited target speaker data, we utilize a two-stage training strategy to adapt the base model to the target speaker. During model adaptation, several tricks, such as data augmentation and joint training with auxiliary singer data, are involved. Official challenge results show that our system achieves superior performance, especially in the cross-domain task, ranking 1st and 2nd in naturalness and similarity, respectively. Further ablation justifies the effectiveness of our system design.
MBTFNet: Multi-Band Temporal-Frequency Neural Network For Singing Voice Enhancement
Oct 06, 2023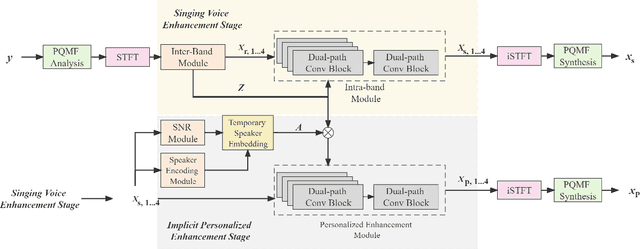
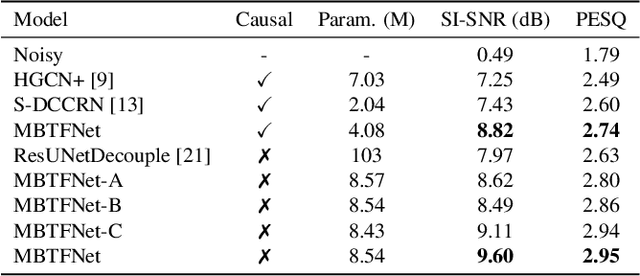
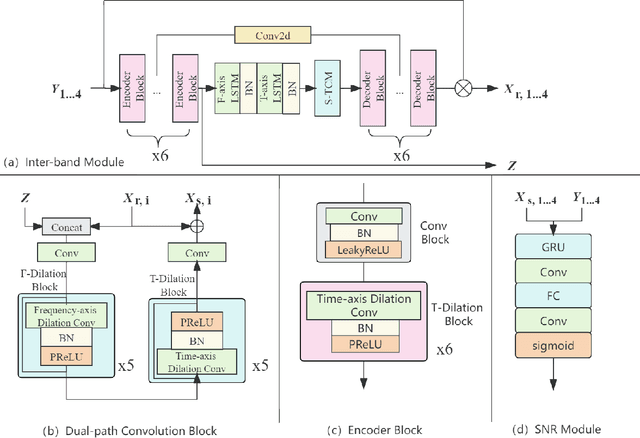
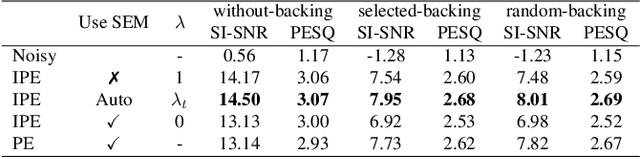
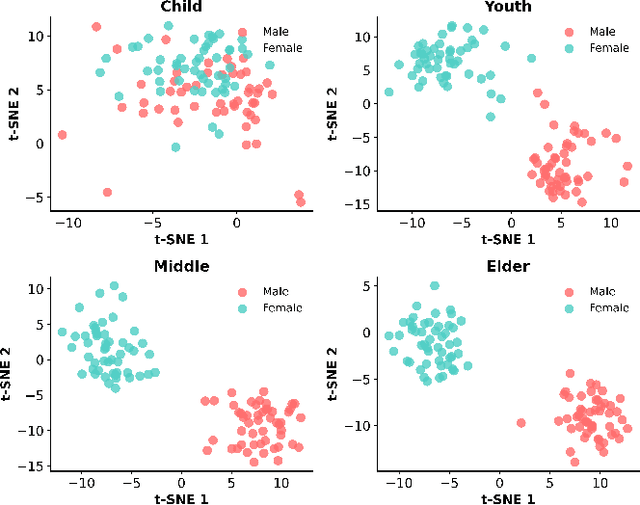
A typical neural speech enhancement (SE) approach mainly handles speech and noise mixtures, which is not optimal for singing voice enhancement scenarios. Music source separation (MSS) models treat vocals and various accompaniment components equally, which may reduce performance compared to the model that only considers vocal enhancement. In this paper, we propose a novel multi-band temporal-frequency neural network (MBTFNet) for singing voice enhancement, which particularly removes background music, noise and even backing vocals from singing recordings. MBTFNet combines inter and intra-band modeling for better processing of full-band signals. Dual-path modeling are introduced to expand the receptive field of the model. We propose an implicit personalized enhancement (IPE) stage based on signal-to-noise ratio (SNR) estimation, which further improves the performance of MBTFNet. Experiments show that our proposed model significantly outperforms several state-of-the-art SE and MSS models.
KaraTuner: Towards end to end natural pitch correction for singing voice in karaoke
Oct 18, 2021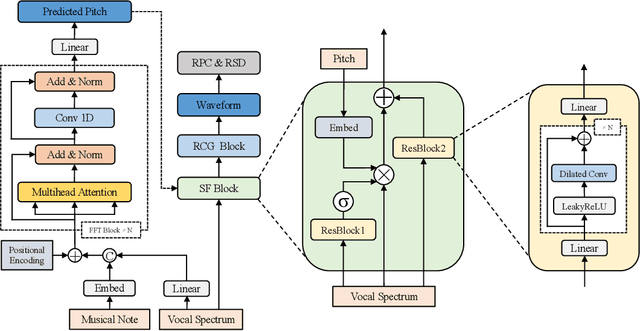

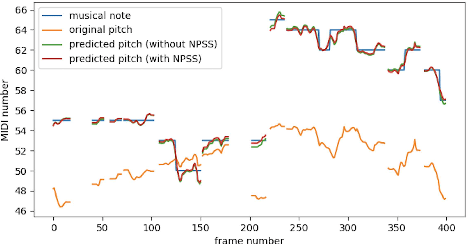
An automatic pitch correction system typically includes several stages, such as pitch extraction, deviation estimation, pitch shift processing, and cross-fade smoothing. However, designing these components with strategies often requires domain expertise and they are likely to fail on corner cases. In this paper, we present KaraTuner, an end-to-end neural architecture that predicts pitch curve and resynthesizes the singing voice directly from the tuned pitch and vocal spectrum extracted from the original recordings. Several vital technical points have been introduced in KaraTuner to ensure pitch accuracy, pitch naturalness, timbre consistency, and sound quality. A feed-forward Transformer is employed in the pitch predictor to capture long-term dependencies in the vocal spectrum and musical note. We also develop a pitch-controllable vocoder base on a novel source-filter block and the Fre-GAN architecture. KaraTuner obtains a higher preference than the rule-based pitch correction approach through A/B tests, and perceptual experiments show that the proposed vocoder achieves significant advantages in timbre consistency and sound quality compared with the parametric WORLD vocoder and phase vocoder.