 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolvable Embodied Agent for Robotic Manipulation via Long Short-Term Reflection and Optimization
Apr 15, 2026Achieving general-purpose robotics requires empowering robots to adapt and evolve based on their environment and feedback. Traditional methods face limitations such as extensive training requirements, difficulties in cross-task generalization, and lack of interpretability. Prompt learning offers new opportunities for self-evolving robots without extensive training, but simply reflecting on past experiences.However, extracting meaningful insights from task successes and failures remains a challenge. To this end, we propose the evolvable embodied agent (EEAgent) framework, which leverages large vision-language models (VLMs) for better environmental interpretation and policy planning. To enhance reflection on past experiences, we propose a long short-term reflective optimization (LSTRO) mechanism that dynamically refines prompts based on both past experiences and newly learned lessons, facilitating continuous self-evolution, thereby enhancing overall task success rates. Evaluations on six VIMA-Bench tasks reveal that our approach sets a new state-of-the-art, notably outperforming baselines in complex scenarios.
Attention-weighted Centered Kernel Alignment for Knowledge Distillation in Large Audio-Language Models Applied to Speech Emotion Recognition
Feb 02, 2026The emergence of Large Audio-Language Models (LALMs) has advanced Speech Emotion Recognition (SER), but their size limits deployment in resource-constrained environments. While Knowledge Distillation is effective for LALM compression, existing methods remain underexplored in distilling the cross-modal projection module (Projector), and often struggle with alignment due to differences in feature dimensions. We propose PL-Distill, a KD framework that combines Projector-Level Distillation (PDist) to align audio embeddings and Logits-Level Distillation (LDist) to align output logits. PDist introduces Attention-weighted Centered Kernel Alignment, a novel approach we propose to highlight important time steps and address dimension mismatches. Meanwhile, LDist minimizes the Kullback-Leibler divergence between teacher and student logits from audio and text modalities. On IEMOCAP, RAVDESS, and SAVEE, PL-Distill compresses an 8.4B-parameter teacher to a compact 1.1B-parameter student, consistently outperforming the teacher, state-of-the-art pretrained models, and other KD baselines across all metrics.
Head-Aware Visual Cropping: Enhancing Fine-Grained VQA with Attention-Guided Subimage
Jan 30, 2026Multimodal Large Language Models (MLLMs) show strong performance in Visual Question Answering (VQA) but remain limited in fine-grained reasoning due to low-resolution inputs and noisy attention aggregation. We propose \textbf{Head Aware Visual Cropping (HAVC)}, a training-free method that improves visual grounding by leveraging a selectively refined subset of attention heads. HAVC first filters heads through an OCR-based diagnostic task, ensuring that only those with genuine grounding ability are retained. At inference, these heads are further refined using spatial entropy for stronger spatial concentration and gradient sensitivity for predictive contribution. The fused signals produce a reliable Visual Cropping Guidance Map, which highlights the most task-relevant region and guides the cropping of a subimage subsequently provided to the MLLM together with the image-question pair. Extensive experiments on multiple fine-grained VQA benchmarks demonstrate that HAVC consistently outperforms state-of-the-art cropping strategies, achieving more precise localization, stronger visual grounding, providing a simple yet effective strategy for enhancing precision in MLLMs.
CARE: Multi-Task Pretraining for Latent Continuous Action Representation in Robot Control
Jan 30, 2026Recent advances in Vision-Language-Action (VLA) models have shown promise for robot control, but their dependence on action supervision limits scalability and generalization. To address this challenge, we introduce CARE, a novel framework designed to train VLA models for robotic task execution. Unlike existing methods that depend on action annotations during pretraining, CARE eliminates the need for explicit action labels by leveraging only video-text pairs. These weakly aligned data sources enable the model to learn continuous latent action representations through a newly designed multi-task pretraining objective. During fine-tuning, a small set of labeled data is used to train the action head for control. Experimental results across various simulation tasks demonstrate CARE's superior success rate, semantic interpretability, and ability to avoid shortcut learning. These results underscore CARE's scalability, interpretability, and effectiveness in robotic control with weak supervision.
MIRRORTALK: Forging Personalized Avatars Via Disentangled Style and Hierarchical Motion Control
Jan 30, 2026Synthesizing personalized talking faces that uphold and highlight a speaker's unique style while maintaining lip-sync accuracy remains a significant challenge. A primary limitation of existing approaches is the intrinsic confounding of speaker-specific talking style and semantic content within facial motions, which prevents the faithful transfer of a speaker's unique persona to arbitrary speech. In this paper, we propose MirrorTalk, a generative framework based on a conditional diffusion model, combined with a Semantically-Disentangled Style Encoder (SDSE) that can distill pure style representations from a brief reference video. To effectively utilize this representation, we further introduce a hierarchical modulation strategy within the diffusion process. This mechanism guides the synthesis by dynamically balancing the contributions of audio and style features across distinct facial regions, ensuring both precise lip-sync accuracy and expressive full-face dynamics. Extensive experiments demonstrate that MirrorTalk achieves significant improvements over state-of-the-art methods in terms of lip-sync accuracy and personalization preservation.
CycleFlow: Leveraging Cycle Consistency in Flow Matching for Speaker Style Adaptation
Jan 03, 2025Voice Conversion (VC) aims to convert the style of a source speaker, such as timbre and pitch, to the style of any target speaker while preserving the linguistic content. However, the ground truth of the converted speech does not exist in a non-parallel VC scenario, which induces the train-inference mismatch problem. Moreover, existing methods still have an inaccurate pitch and low speaker adaptation quality, there is a significant disparity in pitch between the source and target speaker style domains. As a result, the models tend to generate speech with hoarseness, posing challenges in achieving high-quality voice conversion. In this study, we propose CycleFlow, a novel VC approach that leverages cycle consistency in conditional flow matching (CFM) for speaker timbre adaptation training on non-parallel data. Furthermore, we design a Dual-CFM based on VoiceCFM and PitchCFM to generate speech and improve speaker pitch adaptation quality. Experiments show that our method can significantly improve speaker similarity, generating natural and higher-quality speech.
ESARM: 3D Emotional Speech-to-Animation via Reward Model from Automatically-Ranked Demonstrations
Nov 20, 2024This paper proposes a novel 3D speech-to-animation (STA) generation framework designed to address the shortcomings of existing models in producing diverse and emotionally resonant animations. Current STA models often generate animations that lack emotional depth and variety, failing to align with human expectations. To overcome these limitations, we introduce a novel STA model coupled with a reward model. This combination enables the decoupling of emotion and content under audio conditions through a cross-coupling training approach. Additionally, we develop a training methodology that leverages automatic quality evaluation of generated facial animations to guide the reinforcement learning process. This methodology encourages the STA model to explore a broader range of possibilities, resulting in the generation of diverse and emotionally expressive facial animations of superior quality. We conduct extensive empirical experiments on a benchmark dataset, and the results validate the effectiveness of our proposed framework in generating high-quality, emotionally rich 3D animations that are better aligned with human preferences.
Semi-Supervised Self-Learning Enhanced Music Emotion Recognition
Oct 29, 2024

Music emotion recognition (MER) aims to identify the emotions conveyed in a given musical piece. But currently in the field of MER, the available public datasets have limited sample sizes. Recently, segment-based methods for emotion-related tasks have been proposed, which train backbone networks on shorter segments instead of entire audio clips, thereby naturally augmenting training samples without requiring additional resources. Then, the predicted segment-level results are aggregated to obtain the entire song prediction. The most commonly used method is that segment inherits the label of the clip containing it, but music emotion is not constant during the whole clip. Doing so will introduce label noise and make the training overfit easily. To handle the noisy label issue, we propose a semi-supervised self-learning (SSSL) method, which can differentiate between samples with correct and incorrect labels in a self-learning manner, thus effectively utilizing the augmented segment-level data. Experiments on three public emotional datasets demonstrate that the proposed method can achieve better or comparable performance.
IDEAW: Robust Neural Audio Watermarking with Invertible Dual-Embedding
Sep 29, 2024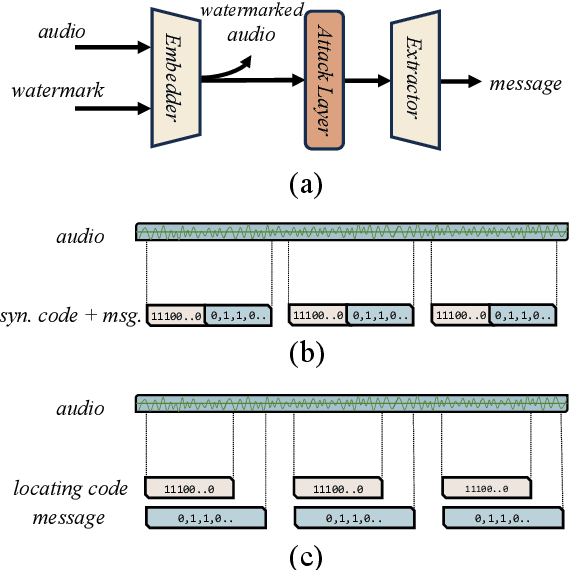

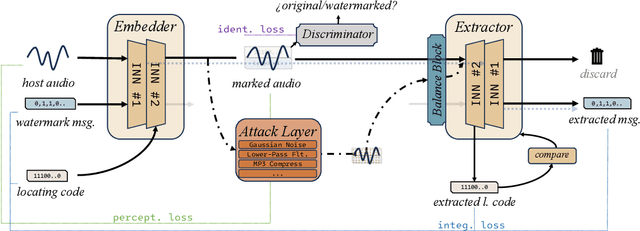

The audio watermarking technique embeds messages into audio and accurately extracts messages from the watermarked audio. Traditional methods develop algorithms based on expert experience to embed watermarks into the time-domain or transform-domain of signals. With the development of deep neural networks, deep learning-based neural audio watermarking has emerged. Compared to traditional algorithms, neural audio watermarking achieves better robustness by considering various attacks during training. However, current neural watermarking methods suffer from low capacity and unsatisfactory imperceptibility. Additionally, the issue of watermark locating, which is extremely important and even more pronounced in neural audio watermarking, has not been adequately studied. In this paper, we design a dual-embedding watermarking model for efficient locating. We also consider the impact of the attack layer on the invertible neural network in robustness training, improving the model to enhance both its reasonableness and stability. Experiments show that the proposed model, IDEAW, can withstand various attacks with higher capacity and more efficient locating ability compared to existing methods.
Enhancing Emotion Recognition in Conversation through Emotional Cross-Modal Fusion and Inter-class Contrastive Learning
May 28, 2024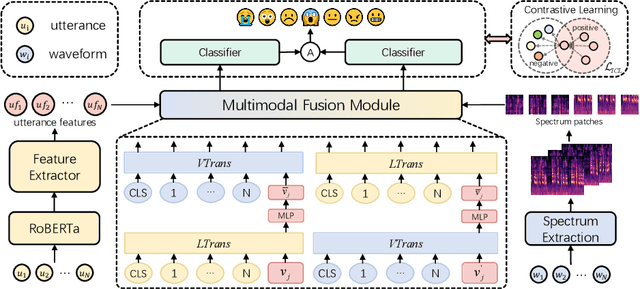

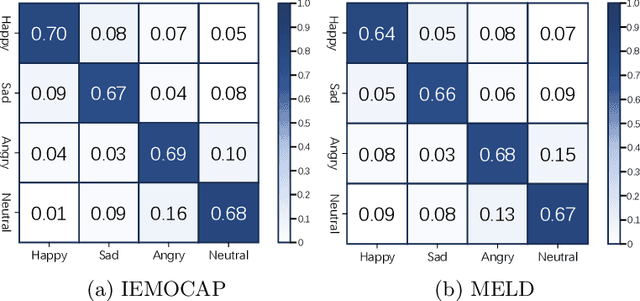
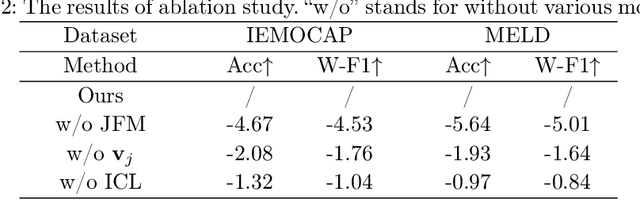
The purpose of emotion recognition in conversation (ERC) is to identify the emotion category of an utterance based on contextual information. Previous ERC methods relied on simple connections for cross-modal fusion and ignored the information differences between modalities, resulting in the model being unable to focus on modality-specific emotional information. At the same time, the shared information between modalities was not processed to generate emotions. Information redundancy problem. To overcome these limitations, we propose a cross-modal fusion emotion prediction network based on vector connections. The network mainly includes two stages: the multi-modal feature fusion stage based on connection vectors and the emotion classification stage based on fused features. Furthermore, we design a supervised inter-class contrastive learning module based on emotion labels. Experimental results confirm the effectiveness of the proposed method, demonstrating excellent performance on the IEMOCAP and MELD datasets.