 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycleFlow: Leveraging Cycle Consistency in Flow Matching for Speaker Style Adaptation
Jan 03, 2025Voice Conversion (VC) aims to convert the style of a source speaker, such as timbre and pitch, to the style of any target speaker while preserving the linguistic content. However, the ground truth of the converted speech does not exist in a non-parallel VC scenario, which induces the train-inference mismatch problem. Moreover, existing methods still have an inaccurate pitch and low speaker adaptation quality, there is a significant disparity in pitch between the source and target speaker style domains. As a result, the models tend to generate speech with hoarseness, posing challenges in achieving high-quality voice conversion. In this study, we propose CycleFlow, a novel VC approach that leverages cycle consistency in conditional flow matching (CFM) for speaker timbre adaptation training on non-parallel data. Furthermore, we design a Dual-CFM based on VoiceCFM and PitchCFM to generate speech and improve speaker pitch adaptation quality. Experiments show that our method can significantly improve speaker similarity, generating natural and higher-quality speech.
AlignCap: Aligning Speech Emotion Captioning to Human Preferences
Oct 24, 2024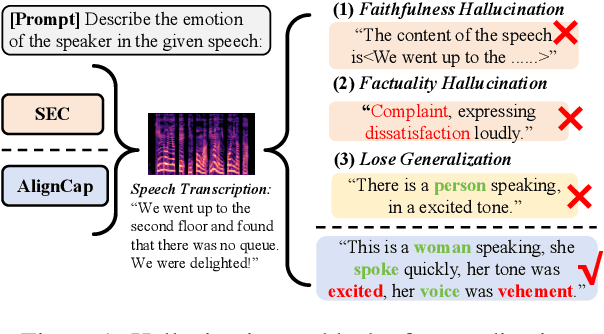

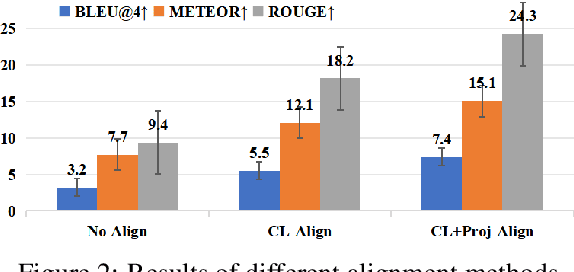
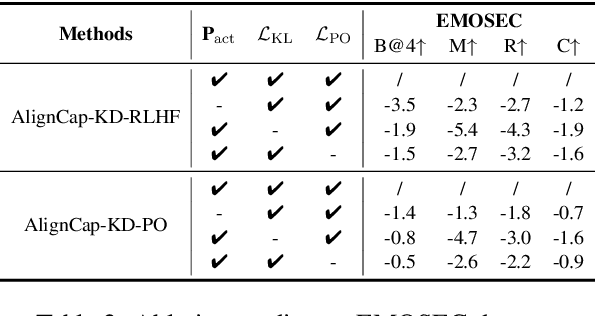
Speech Emotion Captioning (SEC) has gradually become an active research task. The emotional content conveyed through human speech are often complex, and classifying them into fixed categories may not be enough to fully capture speech emotions. Describing speech emotions through natural language may be a more effective approach. However, existing SEC methods often produce hallucinations and lose generalization on unseen speech. To overcome these problems, we propose AlignCap, which Aligning Speech Emotion Captioning to Human Preferences based on large language model (LLM) with two properties: 1) Speech-Text Alignment, which minimizing the divergence between the LLM's response prediction distributions for speech and text inputs using knowledge distillation (KD) Regularization. 2) Human Preference Alignment, where we design Preference Optimization (PO) Regularization to eliminate factuality and faithfulness hallucinations. We also extract emotional clues as a prompt for enriching fine-grained information under KD-Regularization. Experiments demonstrate that AlignCap presents stronger performance to other state-of-the-art methods on Zero-shot SEC task.
EfficientASR: Speech Recognition Network Compression via Attention Redundancy and Chunk-Level FFN Optimization
Apr 30, 2024In recent years, Transformer networks have shown remarkable performance in speech recognition tasks. However, their deployment poses challenges due to high computational and storage resource requirements. To address this issue, a lightweight model called EfficientASR is proposed in this paper, aiming to enhance the versatility of Transformer models. EfficientASR employs two primary modules: Shared Residual Multi-Head Attention (SRMHA) and Chunk-Level Feedforward Networks (CFFN). The SRMHA module effectively reduces redundant computations in the network, while the CFFN module captures spatial knowledge and reduces the number of parameters. The effectiveness of the EfficientASR model is validated on two public datasets, namely Aishell-1 and HKUST. Experimental results demonstrate a 36% reduction in parameters compared to the baseline Transformer network, along with improvements of 0.3% and 0.2% in Character Error Rate (CER) on the Aishell-1 and HKUST datasets, respectively.
EAD-VC: Enhancing Speech Auto-Disentanglement for Voice Conversion with IFUB Estimator and Joint Text-Guided Consistent Learning
Apr 30, 2024



Using unsupervised learning to disentangle speech into content, rhythm, pitch, and timbre for voice conversion has become a hot research topic. Existing works generally take into account disentangling speech components through human-crafted bottleneck features which can not achieve sufficient information disentangling, while pitch and rhythm may still be mixed together. There is a risk of information overlap in the disentangling process which results in less speech naturalness. To overcome such limits, we propose a two-stage model to disentangle speech representations in a self-supervised manner without a human-crafted bottleneck design, which uses the Mutual Information (MI) with the designed upper bound estimator (IFUB) to separate overlapping information between speech components. Moreover, we design a Joint Text-Guided Consistent (TGC) module to guide the extraction of speech content and eliminate timbre leakage issues. Experiments show that our model can achieve a better performance than the baseline, regarding disentanglement effectiveness, speech naturalness, and similarity. Audio samples can be found at https://largeaudiomodel.com/eadvc.
QLSC: A Query Latent Semantic Calibrator for Robust Extractive Question Answering
Apr 30, 2024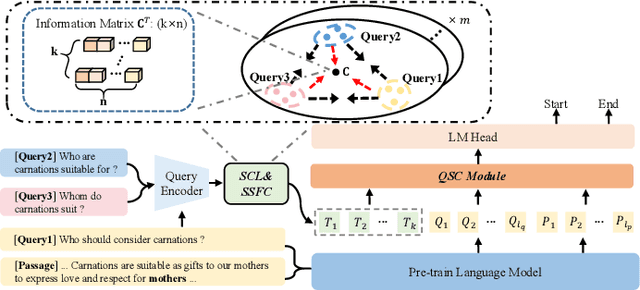
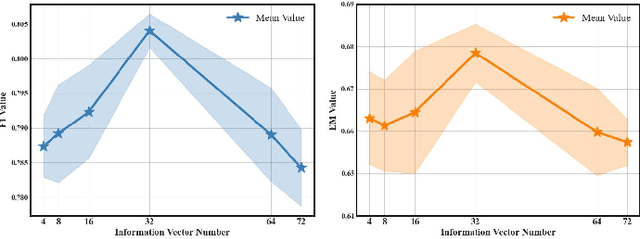
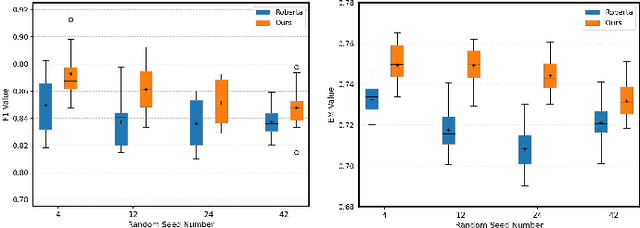
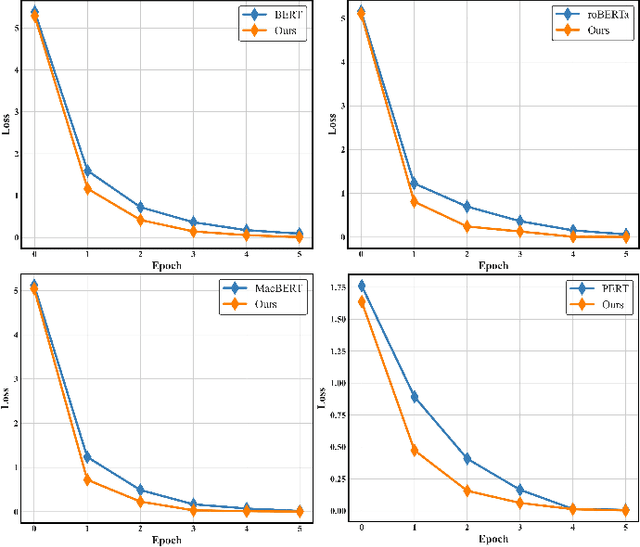
Extractive Question Answering (EQA) in Machine Reading Comprehension (MRC) often faces the challenge of dealing with semantically identical but format-variant inputs. Our work introduces a novel approach, called the ``Query Latent Semantic Calibrator (QLSC)'', designed as an auxiliary module for existing MRC models. We propose a unique scaling strategy to capture latent semantic center features of queries. These features are then seamlessly integrated into traditional query and passage embeddings using an attention mechanism. By deepening the comprehension of the semantic queries-passage relationship, our approach diminishes sensitivity to variations in text format and boosts the model's capability in pinpointing accurate answers. Experimental results on robust Question-Answer datasets confirm that our approach effectively handles format-variant but semantically identical queries, highlighting the effectiveness and adaptability of our proposed method.
EM-TTS: Efficiently Trained Low-Resource Mongolian Lightweight Text-to-Speech
Mar 17, 2024



Recently, deep learning-based Text-to-Speech (TTS) systems have achieved high-quality speech synthesis results. Recurrent neural networks have become a standard modeling technique for sequential data in TTS systems and are widely used. However, training a TTS model which includes RNN components requires powerful GPU performance and takes a long time. In contrast, CNN-based sequence synthesis techniques can significantly reduce the parameters and training time of a TTS model while guaranteeing a certain performance due to their high parallelism, which alleviate these economic costs of training. In this paper, we propose a lightweight TTS system based on deep convolutional neural networks, which is a two-stage training end-to-end TTS model and does not employ any recurrent units. Our model consists of two stages: Text2Spectrum and SSRN. The former is used to encode phonemes into a coarse mel spectrogram and the latter is used to synthesize the complete spectrum from the coarse mel spectrogram. Meanwhile, we improve the robustness of our model by a series of data augmentations, such as noise suppression, time warping, frequency masking and time masking, for solving the low resource mongolian problem. Experiments show that our model can reduce the training time and parameters while ensuring the quality and naturalness of the synthesized speech compared to using mainstream TTS models. Our method uses NCMMSC2022-MTTSC Challenge dataset for validation, which significantly reduces training time while maintaining a certain accuracy.
CP-EB: Talking Face Generation with Controllable Pose and Eye Blinking Embedding
Nov 15, 2023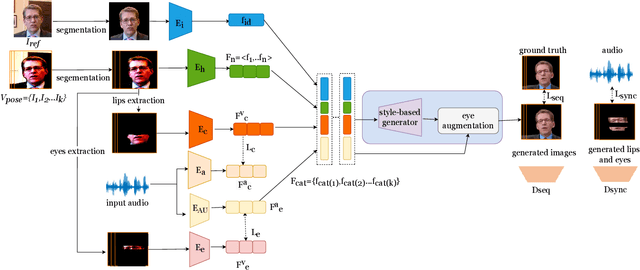
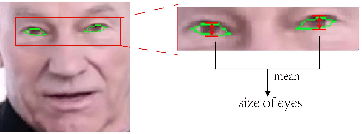
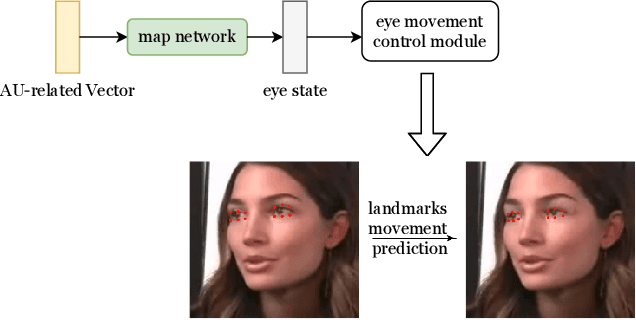

This paper proposes a talking face generation method named "CP-EB" that takes an audio signal as input and a person image as reference, to synthesize a photo-realistic people talking video with head poses controlled by a short video clip and proper eye blinking embedding. It's noted that not only the head pose but also eye blinking are both important aspects for deep fake detection. The implicit control of poses by video has already achieved by the state-of-art work. According to recent research, eye blinking has weak correlation with input audio which means eye blinks extraction from audio and generation are possible. Hence, we propose a GAN-based architecture to extract eye blink feature from input audio and reference video respectively and employ contrastive training between them, then embed it into the concatenated features of identity and poses to generate talking face images. Experimental results show that the proposed method can generate photo-realistic talking face with synchronous lips motions, natural head poses and blinking eyes.