 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifeBench: A Benchmark for Long-Horizon Multi-Source Memory
Mar 04, 2026Long-term memory is fundamental for personalized agents capable of accumulating knowledge, reasoning over user experiences, and adapting across time. However, existing memory benchmarks primarily target declarative memory, specifically semantic and episodic types, where all information is explicitly presented in dialogues. In contrast, real-world actions are also governed by non-declarative memory, including habitual and procedural types, and need to be inferred from diverse digital traces. To bridge this gap, we introduce Lifebench, which features densely connected, long-horizon event simulation. It pushes AI agents beyond simple recall, requiring the integration of declarative and non-declarative memory reasoning across diverse and temporally extended contexts. Building such a benchmark presents two key challenges: ensuring data quality and scalability. We maintain data quality by employing real-world priors, including anonymized social surveys, map APIs, and holiday-integrated calendars, thus enforcing fidelity, diversity and behavioral rationality within the dataset. Towards scalability, we draw inspiration from cognitive science and structure events according to their partonomic hierarchy; enabling efficient parallel generation while maintaining global coherence. Performance results show that top-tier, state-of-the-art memory systems reach just 55.2\% accuracy, highlighting the inherent difficulty of long-horizon retrieval and multi-source integration within our proposed benchmark. The dataset and data synthesis code are available at https://github.com/1754955896/LifeBench.
EM-TTS: Efficiently Trained Low-Resource Mongolian Lightweight Text-to-Speech
Mar 17, 2024



Recently, deep learning-based Text-to-Speech (TTS) systems have achieved high-quality speech synthesis results. Recurrent neural networks have become a standard modeling technique for sequential data in TTS systems and are widely used. However, training a TTS model which includes RNN components requires powerful GPU performance and takes a long time. In contrast, CNN-based sequence synthesis techniques can significantly reduce the parameters and training time of a TTS model while guaranteeing a certain performance due to their high parallelism, which alleviate these economic costs of training. In this paper, we propose a lightweight TTS system based on deep convolutional neural networks, which is a two-stage training end-to-end TTS model and does not employ any recurrent units. Our model consists of two stages: Text2Spectrum and SSRN. The former is used to encode phonemes into a coarse mel spectrogram and the latter is used to synthesize the complete spectrum from the coarse mel spectrogram. Meanwhile, we improve the robustness of our model by a series of data augmentations, such as noise suppression, time warping, frequency masking and time masking, for solving the low resource mongolian problem. Experiments show that our model can reduce the training time and parameters while ensuring the quality and naturalness of the synthesized speech compared to using mainstream TTS models. Our method uses NCMMSC2022-MTTSC Challenge dataset for validation, which significantly reduces training time while maintaining a certain accuracy.
SAR2EO: A High-resolution Image Translation Framework with Denoising Enhancement
Apr 08, 2023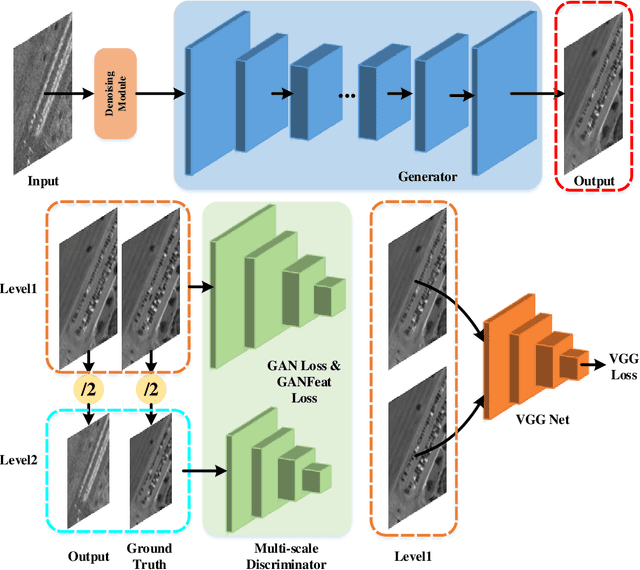
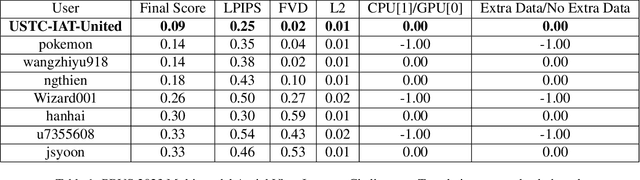

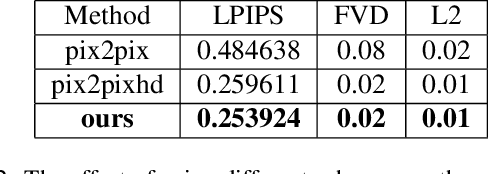
Synthetic Aperture Radar (SAR) to electro-optical (EO) image translation is a fundamental task in remote sensing that can enrich the dataset by fusing information from different sources. Recently, many methods have been proposed to tackle this task, but they are still difficult to complete the conversion from low-resolution images to high-resolution images. Thus, we propose a framework, SAR2EO, aiming at addressing this challenge. Firstly, to generate high-quality EO images, we adopt the coarse-to-fine generator, multi-scale discriminators, and improved adversarial loss in the pix2pixHD model to increase the synthesis quality. Secondly, we introduce a denoising module to remove the noise in SAR images, which helps to suppress the noise while preserving the structural information of the images. To validate the effectiveness of the proposed framework, we conduct experiments on the dataset of the Multi-modal Aerial View Imagery Challenge (MAVIC), which consists of large-scale SAR and EO image pairs. The experimental results demonstrate the superiority of our proposed framework, and we win the first place in the MAVIC held in CVPR PBVS 2023.
Scene Clustering Based Pseudo-labeling Strategy for Multi-modal Aerial View Object Classification
May 19, 2022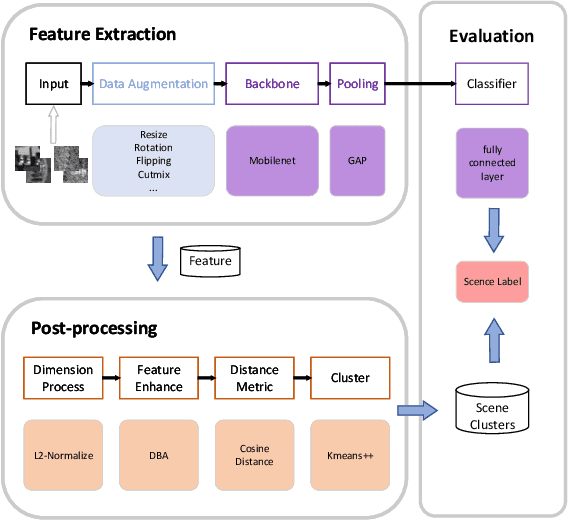
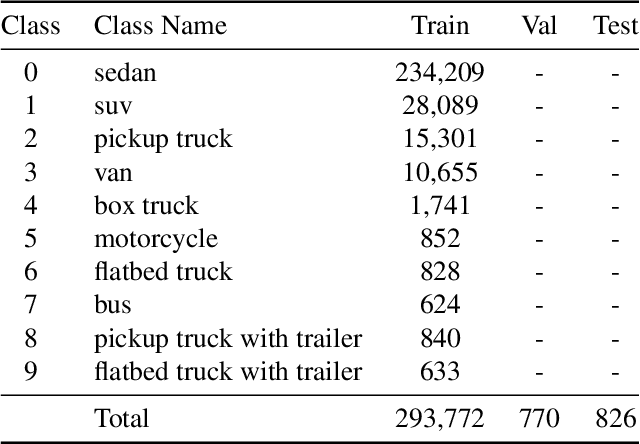
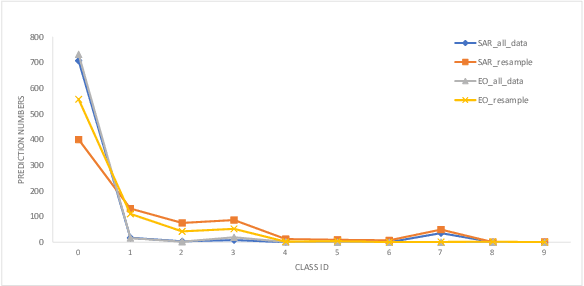

Multi-modal aerial view object classification (MAVOC) in Automatic target recognition (ATR), although an important and challenging problem, has been under studied. This paper firstly finds that fine-grained data, class imbalance and various shooting conditions preclude the representational ability of general image classification. Moreover, the MAVOC dataset has scene aggregation characteristics. By exploiting these properties, we propose Scene Clustering Based Pseudo-labeling Strategy (SCP-Label), a simple yet effective method to employ in post-processing. The SCP-Label brings greater accuracy by assigning the same label to objects within the same scene while also mitigating bias and confusion with model ensembles. Its performance surpasses the official baseline by a large margin of +20.57% Accuracy on Track 1 (SAR), and +31.86% Accuracy on Track 2 (SAR+EO), demonstrating the potential of SCP-Label as post-processing. Finally, we win the championship both on Track1 and Track2 in the CVPR 2022 Perception Beyond the Visible Spectrum (PBVS) Workshop MAVOC Challenge. Our code is available at https://github.com/HowieChangchn/SCP-Label.