 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-Parsing: Perception, Structuring and Recognition via High-Parallelism Decoding
Jan 28, 2026This paper presents Youtu-Parsing, an efficient and versatile document parsing model designed for high-performance content extraction. The architecture employs a native Vision Transformer (ViT) featuring a dynamic-resolution visual encoder to extract shared document features, coupled with a prompt-guided Youtu-LLM-2B language model for layout analysis and region-prompted decoding. Leveraging this decoupled and feature-reusable framework, we introduce a high-parallelism decoding strategy comprising two core components: token parallelism and query parallelism. The token parallelism strategy concurrently generates up to 64 candidate tokens per inference step, which are subsequently validated through a verification mechanism. This approach yields a 5--11x speedup over traditional autoregressive decoding and is particularly well-suited for highly structured scenarios, such as table recognition. To further exploit the advantages of region-prompted decoding, the query parallelism strategy enables simultaneous content prediction for multiple bounding boxes (up to five), providing an additional 2x acceleration while maintaining output quality equivalent to standard decoding. Youtu-Parsing encompasses a diverse range of document elements, including text, formulas, tables, charts, seals, and hierarchical structures. Furthermore, the model exhibits strong robustness when handling rare characters, multilingual text, and handwritten content. Extensive evaluations demonstrate that Youtu-Parsing achieves state-of-the-art (SOTA) performance on both the OmniDocBench and olmOCR-bench benchmarks. Overall, Youtu-Parsing demonstrates significant experimental value and practical utility for large-scale document intelligence applications.
Youtu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
AUD-TGN: Advancing Action Unit Detection with Temporal Convolution and GPT-2 in Wild Audiovisual Contexts
Mar 20, 2024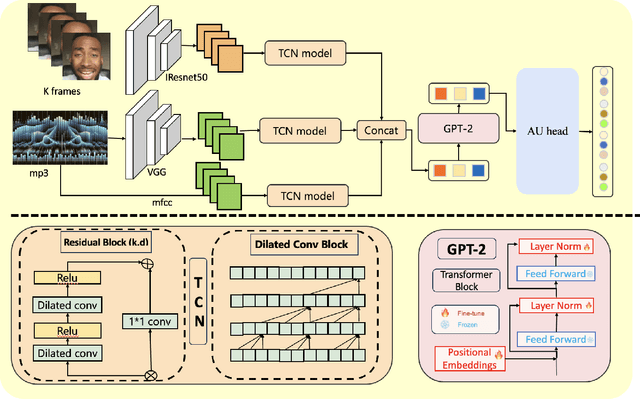
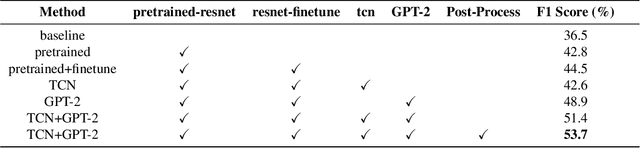
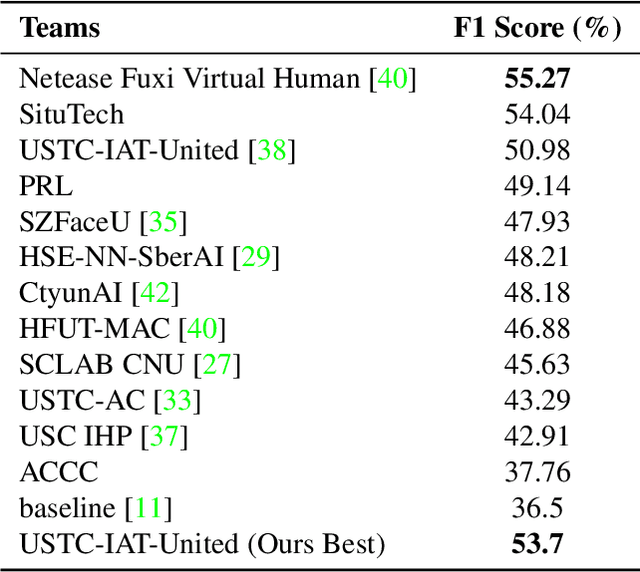
Leveraging the synergy of both audio data and visual data is essential for understanding human emotions and behaviors, especially in in-the-wild setting. Traditional methods for integrating such multimodal information often stumble, leading to less-than-ideal outcomes in the task of facial action unit detection. To overcome these shortcomings, we propose a novel approach utilizing audio-visual multimodal data. This method enhances audio feature extraction by leveraging Mel Frequency Cepstral Coefficients (MFCC) and Log-Mel spectrogram features alongside a pre-trained VGGish network. Moreover, this paper adaptively captures fusion features across modalities by modeling the temporal relationships, and ultilizes a pre-trained GPT-2 model for sophisticated context-aware fusion of multimodal information. Our method notably improves the accuracy of AU detection by understanding the temporal and contextual nuances of the data, showcasing significant advancements in the comprehension of intricate scenarios. These findings underscore the potential of integrating temporal dynamics and contextual interpretation, paving the way for future research endeavors.
Multimodal Fusion Method with Spatiotemporal Sequences and Relationship Learning for Valence-Arousal Estimation
Mar 20, 2024


This paper presents our approach for the VA (Valence-Arousal) estimation task in the ABAW6 competition. We devised a comprehensive model by preprocessing video frames and audio segments to extract visual and audio features. Through the utilization of Temporal Convolutional Network (TCN) modules, we effectively captured the temporal and spatial correlations between these features. Subsequently, we employed a Transformer encoder structure to learn long-range dependencies, thereby enhancing the model's performance and generalization ability. Our method leverages a multimodal data fusion approach, integrating pre-trained audio and video backbones for feature extraction, followed by TCN-based spatiotemporal encoding and Transformer-based temporal information capture. Experimental results demonstrate the effectiveness of our approach, achieving competitive performance in VA estimation on the AffWild2 dataset.
Exploring Facial Expression Recognition through Semi-Supervised Pretraining and Temporal Modeling
Mar 19, 2024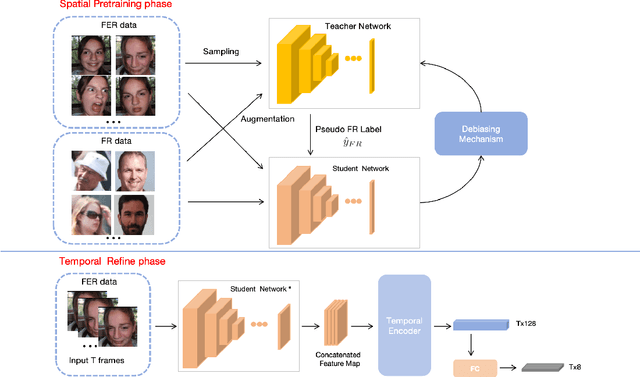

Facial Expression Recognition (FER) plays a crucial role in computer vision and finds extensive applications across various fields. This paper aims to present our approach for the upcoming 6th Affective Behavior Analysis in-the-Wild (ABAW) competition, scheduled to be held at CVPR2024. In the facial expression recognition task, The limited size of the FER dataset poses a challenge to the expression recognition model's generalization ability, resulting in subpar recognition performance. To address this problem, we employ a semi-supervised learning technique to generate expression category pseudo-labels for unlabeled face data. At the same time, we uniformly sampled the labeled facial expression samples and implemented a debiased feedback learning strategy to address the problem of category imbalance in the dataset and the possible data bias in semi-supervised learning. Moreover, to further compensate for the limitation and bias of features obtained only from static images, we introduced a Temporal Encoder to learn and capture temporal relationships between neighbouring expression image features. In the 6th ABAW competition, our method achieved outstanding results on the official validation set, a result that fully confirms the effectiveness and competitiveness of our proposed method.
SAR2EO: A High-resolution Image Translation Framework with Denoising Enhancement
Apr 08, 2023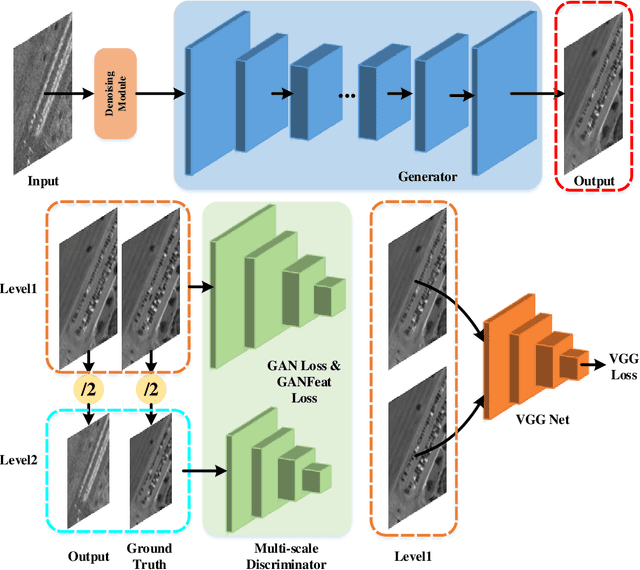
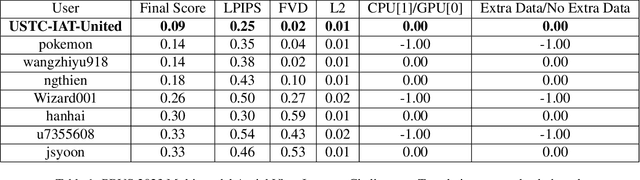

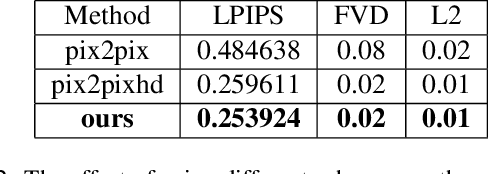
Synthetic Aperture Radar (SAR) to electro-optical (EO) image translation is a fundamental task in remote sensing that can enrich the dataset by fusing information from different sources. Recently, many methods have been proposed to tackle this task, but they are still difficult to complete the conversion from low-resolution images to high-resolution images. Thus, we propose a framework, SAR2EO, aiming at addressing this challenge. Firstly, to generate high-quality EO images, we adopt the coarse-to-fine generator, multi-scale discriminators, and improved adversarial loss in the pix2pixHD model to increase the synthesis quality. Secondly, we introduce a denoising module to remove the noise in SAR images, which helps to suppress the noise while preserving the structural information of the images. To validate the effectiveness of the proposed framework, we conduct experiments on the dataset of the Multi-modal Aerial View Imagery Challenge (MAVIC), which consists of large-scale SAR and EO image pairs. The experimental results demonstrate the superiority of our proposed framework, and we win the first place in the MAVIC held in CVPR PBVS 2023.
Local Region Perception and Relationship Learning Combined with Feature Fusion for Facial Action Unit Detection
Mar 19, 2023



Human affective behavior analysis plays a vital role in human-computer interaction (HCI) systems. In this paper, we introduce our submission to the CVPR 2023 Competition on Affective Behavior Analysis in-the-wild (ABAW). We propose a single-stage trained AU detection framework. Specifically, in order to effectively extract facial local region features related to AU detection, we use a local region perception module to effectively extract features of different AUs. Meanwhile, we use a graph neural network-based relational learning module to capture the relationship between AUs. In addition, considering the role of the overall feature of the target face on AU detection, we also use the feature fusion module to fuse the feature information extracted by the backbone network and the AU feature information extracted by the relationship learning module. We also adopted some sampling methods, data augmentation techniques and post-processing strategies to further improve the performance of the model.
Exploring Large-scale Unlabeled Faces to Enhance Facial Expression Recognition
Mar 19, 2023Facial Expression Recognition (FER) is an important task in computer vision and has wide applications in human-computer interaction, intelligent security, emotion analysis, and other fields. However, the limited size of FER datasets limits the generalization ability of expression recognition models, resulting in ineffective model performance. To address this problem, we propose a semi-supervised learning framework that utilizes unlabeled face data to train expression recognition models effectively. Our method uses a dynamic threshold module (\textbf{DTM}) that can adaptively adjust the confidence threshold to fully utilize the face recognition (FR) data to generate pseudo-labels, thus improving the model's ability to model facial expressions. In the ABAW5 EXPR task, our method achieved excellent results on the official validation set.
A Dual Branch Network for Emotional Reaction Intensity Estimation
Mar 16, 2023Emotional Reaction Intensity(ERI) estimation is an important task in multimodal scenarios, and has fundamental applications in medicine, safe driving and other fields. In this paper, we propose a solution to the ERI challenge of the fifth Affective Behavior Analysis in-the-wild(ABAW), a dual-branch based multi-output regression model. The spatial attention is used to better extract visual features, and the Mel-Frequency Cepstral Coefficients technology extracts acoustic features, and a method named modality dropout is added to fusion multimodal features. Our method achieves excellent results on the official validation set.
Multi-model Ensemble Learning Method for Human Expression Recognition
Mar 28, 2022



Analysis of human affect plays a vital role in human-computer interaction (HCI) systems. Due to the difficulty in capturing large amounts of real-life data, most of the current methods have mainly focused on controlled environments, which limit their application scenarios. To tackle this problem, we propose our solution based on the ensemble learning method. Specifically, we formulate the problem as a classification task, and then train several expression classification models with different types of backbones--ResNet, EfficientNet and InceptionNet. After that, the outputs of several models are fused via model ensemble method to predict the final results. Moreover, we introduce the multi-fold ensemble method to train and ensemble several models with the same architecture but different data distributions to enhance the performance of our solution. We conduct many experiments on the AffWild2 dataset of the ABAW2022 Challenge, and the results demonstrate the effectiveness of our solution.