 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDDA: Data Driven Attribution at LinkedIn
May 14, 2025Data Driven Attribution, which assigns conversion credits to marketing interactions based on causal patterns learned from data, is the foundation of modern marketing intelligence and vital to any marketing businesses and advertising platform. In this paper, we introduce a unified transformer-based attribution approach that can handle member-level data, aggregate-level data, and integration of external macro factors. We detail the large scale implementation of the approach at LinkedIn, showcasing significant impact. We also share learning and insights that are broadly applicable to the marketing and ad tech fields.
Design a New Pulling Gear for the Automated Pant Bottom Hem Sewing Machine
Nov 18, 2024Automated machinery design for garment manufacturing is essential for improving productivity, consistency, and quality. This paper focuses on the development of new pulling gear for automated pant bottom hem sewing machines. Traditionally, these machines require manual intervention to guide the bottom hem sewing process, which often leads to inconsistent stitch quality and alignment. While twin-needle sewing machines can create twin lines for the bottom hem, they typically lack sufficient pulling force to adequately handle the fabric of the pants' bottom hem. The innovative design of the pulling gear aims to address this issue by providing the necessary pulling force for the bottom hem of eyelet pants. The research and design discussed in this article seek to solve technical challenges, eliminate the need for skilled manual operators, and enhance overall productivity. This improvement ensures smooth and precise feeding of fabric pieces in the automated twin needle sewing machine, ultimately improving the consistency and quality of the stitching. By integrating this innovation, garment manufacturers can boost productivity, reduce reliance on manual skilful labour, and optimize the output of the production process, thereby reaping the benefits of automation in the garment manufacturing industry.
Spatial-aware Attention Generative Adversarial Network for Semi-supervised Anomaly Detection in Medical Image
May 21, 2024


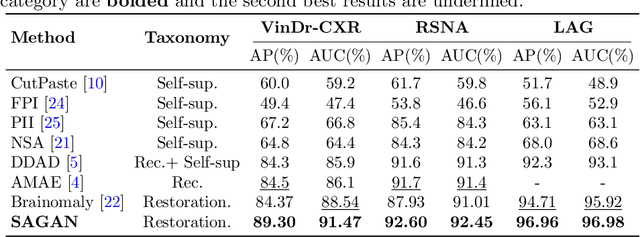
Medical anomaly detection is a critical research area aimed at recognizing abnormal images to aid in diagnosis.Most existing methods adopt synthetic anomalies and image restoration on normal samples to detect anomaly. The unlabeled data consisting of both normal and abnormal data is not well explored. We introduce a novel Spatial-aware Attention Generative Adversarial Network (SAGAN) for one-class semi-supervised generation of health images.Our core insight is the utilization of position encoding and attention to accurately focus on restoring abnormal regions and preserving normal regions. To fully utilize the unlabelled data, SAGAN relaxes the cyclic consistency requirement of the existing unpaired image-to-image conversion methods, and generates high-quality health images corresponding to unlabeled data, guided by the reconstruction of normal images and restoration of pseudo-anomaly images.Subsequently, the discrepancy between the generated healthy image and the original image is utilized as an anomaly score.Extensive experiments on three medical datasets demonstrate that the proposed SAGAN outperforms the state-of-the-art methods.
Position-Guided Prompt Learning for Anomaly Detection in Chest X-Rays
May 20, 2024



Anomaly detection in chest X-rays is a critical task. Most methods mainly model the distribution of normal images, and then regard significant deviation from normal distribution as anomaly. Recently, CLIP-based methods, pre-trained on a large number of medical images, have shown impressive performance on zero/few-shot downstream tasks. In this paper, we aim to explore the potential of CLIP-based methods for anomaly detection in chest X-rays. Considering the discrepancy between the CLIP pre-training data and the task-specific data, we propose a position-guided prompt learning method. Specifically, inspired by the fact that experts diagnose chest X-rays by carefully examining distinct lung regions, we propose learnable position-guided text and image prompts to adapt the task data to the frozen pre-trained CLIP-based model. To enhance the model's discriminative capability, we propose a novel structure-preserving anomaly synthesis method within chest x-rays during the training process. Extensive experiments on three datasets demonstrate that our proposed method outperforms some state-of-the-art methods. The code of our implementation is available at https://github.com/sunzc-sunny/PPAD.
Multimodal Fusion Method with Spatiotemporal Sequences and Relationship Learning for Valence-Arousal Estimation
Mar 20, 2024


This paper presents our approach for the VA (Valence-Arousal) estimation task in the ABAW6 competition. We devised a comprehensive model by preprocessing video frames and audio segments to extract visual and audio features. Through the utilization of Temporal Convolutional Network (TCN) modules, we effectively captured the temporal and spatial correlations between these features. Subsequently, we employed a Transformer encoder structure to learn long-range dependencies, thereby enhancing the model's performance and generalization ability. Our method leverages a multimodal data fusion approach, integrating pre-trained audio and video backbones for feature extraction, followed by TCN-based spatiotemporal encoding and Transformer-based temporal information capture. Experimental results demonstrate the effectiveness of our approach, achieving competitive performance in VA estimation on the AffWild2 dataset.
AUD-TGN: Advancing Action Unit Detection with Temporal Convolution and GPT-2 in Wild Audiovisual Contexts
Mar 20, 2024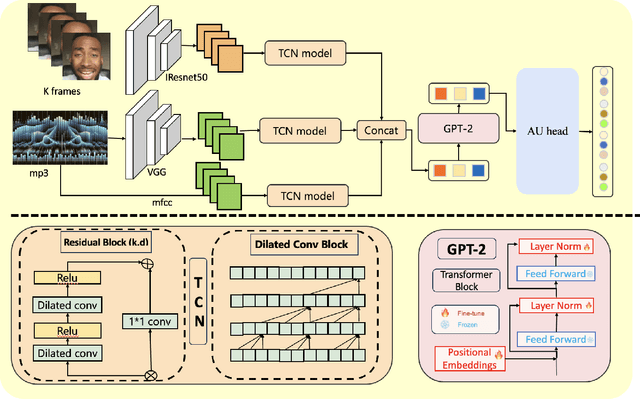
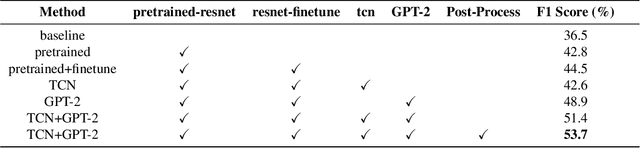
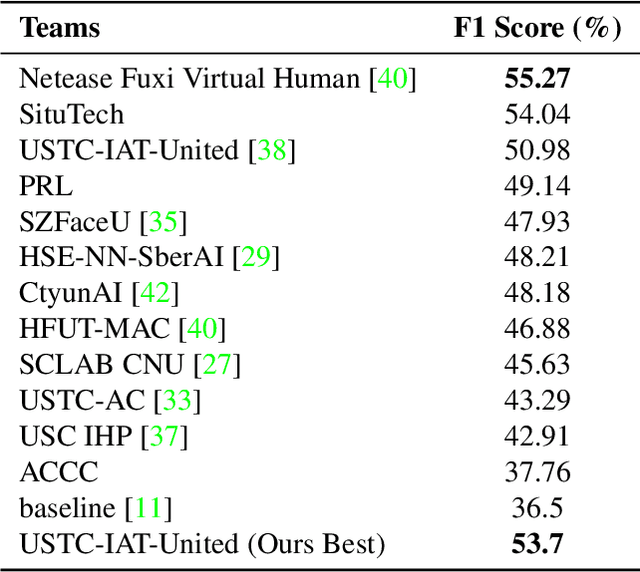
Leveraging the synergy of both audio data and visual data is essential for understanding human emotions and behaviors, especially in in-the-wild setting. Traditional methods for integrating such multimodal information often stumble, leading to less-than-ideal outcomes in the task of facial action unit detection. To overcome these shortcomings, we propose a novel approach utilizing audio-visual multimodal data. This method enhances audio feature extraction by leveraging Mel Frequency Cepstral Coefficients (MFCC) and Log-Mel spectrogram features alongside a pre-trained VGGish network. Moreover, this paper adaptively captures fusion features across modalities by modeling the temporal relationships, and ultilizes a pre-trained GPT-2 model for sophisticated context-aware fusion of multimodal information. Our method notably improves the accuracy of AU detection by understanding the temporal and contextual nuances of the data, showcasing significant advancements in the comprehension of intricate scenarios. These findings underscore the potential of integrating temporal dynamics and contextual interpretation, paving the way for future research endeavors.
Exploring Facial Expression Recognition through Semi-Supervised Pretraining and Temporal Modeling
Mar 19, 2024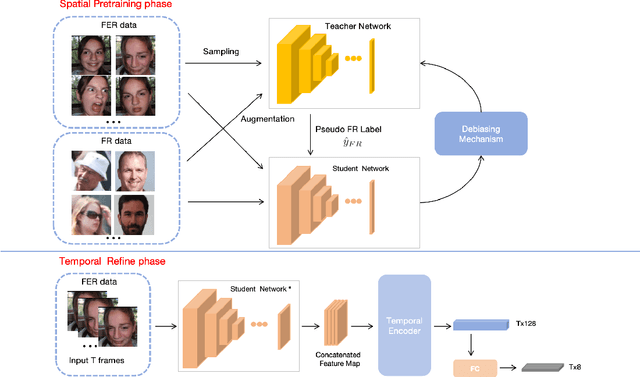

Facial Expression Recognition (FER) plays a crucial role in computer vision and finds extensive applications across various fields. This paper aims to present our approach for the upcoming 6th Affective Behavior Analysis in-the-Wild (ABAW) competition, scheduled to be held at CVPR2024. In the facial expression recognition task, The limited size of the FER dataset poses a challenge to the expression recognition model's generalization ability, resulting in subpar recognition performance. To address this problem, we employ a semi-supervised learning technique to generate expression category pseudo-labels for unlabeled face data. At the same time, we uniformly sampled the labeled facial expression samples and implemented a debiased feedback learning strategy to address the problem of category imbalance in the dataset and the possible data bias in semi-supervised learning. Moreover, to further compensate for the limitation and bias of features obtained only from static images, we introduced a Temporal Encoder to learn and capture temporal relationships between neighbouring expression image features. In the 6th ABAW competition, our method achieved outstanding results on the official validation set, a result that fully confirms the effectiveness and competitiveness of our proposed method.
RHOBIN Challenge: Reconstruction of Human Object Interaction
Jan 07, 2024Modeling the interaction between humans and objects has been an emerging research direction in recent years. Capturing human-object interaction is however a very challenging task due to heavy occlusion and complex dynamics, which requires understanding not only 3D human pose, and object pose but also the interaction between them. Reconstruction of 3D humans and objects has been two separate research fields in computer vision for a long time. We hence proposed the first RHOBIN challenge: reconstruction of human-object interactions in conjunction with the RHOBIN workshop. It was aimed at bringing the research communities of human and object reconstruction as well as interaction modeling together to discuss techniques and exchange ideas. Our challenge consists of three tracks of 3D reconstruction from monocular RGB images with a focus on dealing with challenging interaction scenarios. Our challenge attracted more than 100 participants with more than 300 submissions, indicating the broad interest in the research communities. This paper describes the settings of our challenge and discusses the winning methods of each track in more detail. We observe that the human reconstruction task is becoming mature even under heavy occlusion settings while object pose estimation and joint reconstruction remain challenging tasks. With the growing interest in interaction modeling, we hope this report can provide useful insights and foster future research in this direction. Our workshop website can be found at \href{https://rhobin-challenge.github.io/}{https://rhobin-challenge.github.io/}.