 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOstrakon-VL: Towards Domain-Expert MLLM for Food-Service and Retail Stores
Jan 29, 2026Multimodal Large Language Models (MLLMs) have recently achieved substantial progress in general-purpose perception and reasoning. Nevertheless, their deployment in Food-Service and Retail Stores (FSRS) scenarios encounters two major obstacles: (i) real-world FSRS data, collected from heterogeneous acquisition devices, are highly noisy and lack auditable, closed-loop data curation, which impedes the construction of high-quality, controllable, and reproducible training corpora; and (ii) existing evaluation protocols do not offer a unified, fine-grained and standardized benchmark spanning single-image, multi-image, and video inputs, making it challenging to objectively gauge model robustness. To address these challenges, we first develop Ostrakon-VL, an FSRS-oriented MLLM based on Qwen3-VL-8B. Second, we introduce ShopBench, the first public benchmark for FSRS. Third, we propose QUAD (Quality-aware Unbiased Automated Data-curation), a multi-stage multimodal instruction data curation pipeline. Leveraging a multi-stage training strategy, Ostrakon-VL achieves an average score of 60.1 on ShopBench, establishing a new state of the art among open-source MLLMs with comparable parameter scales and diverse architectures. Notably, it surpasses the substantially larger Qwen3-VL-235B-A22B (59.4) by +0.7, and exceeds the same-scale Qwen3-VL-8B (55.3) by +4.8, demonstrating significantly improved parameter efficiency. These results indicate that Ostrakon-VL delivers more robust and reliable FSRS-centric perception and decision-making capabilities. To facilitate reproducible research, we will publicly release Ostrakon-VL and the ShopBench benchmark.
DualDiff: Dual-branch Diffusion Model for Autonomous Driving with Semantic Fusion
May 03, 2025Accurate and high-fidelity driving scene reconstruction relies on fully leveraging scene information as conditioning. However, existing approaches, which primarily use 3D bounding boxes and binary maps for foreground and background control, fall short in capturing the complexity of the scene and integrating multi-modal information. In this paper, we propose DualDiff, a dual-branch conditional diffusion model designed to enhance multi-view driving scene generation. We introduce Occupancy Ray Sampling (ORS), a semantic-rich 3D representation, alongside numerical driving scene representation, for comprehensive foreground and background control. To improve cross-modal information integration, we propose a Semantic Fusion Attention (SFA) mechanism that aligns and fuses features across modalities. Furthermore, we design a foreground-aware masked (FGM) loss to enhance the generation of tiny objects. DualDiff achieves state-of-the-art performance in FID score, as well as consistently better results in downstream BEV segmentation and 3D object detection tasks.
DualDiff+: Dual-Branch Diffusion for High-Fidelity Video Generation with Reward Guidance
Mar 05, 2025



Accurate and high-fidelity driving scene reconstruction demands the effective utilization of comprehensive scene information as conditional inputs. Existing methods predominantly rely on 3D bounding boxes and BEV road maps for foreground and background control, which fail to capture the full complexity of driving scenes and adequately integrate multimodal information. In this work, we present DualDiff, a dual-branch conditional diffusion model designed to enhance driving scene generation across multiple views and video sequences. Specifically, we introduce Occupancy Ray-shape Sampling (ORS) as a conditional input, offering rich foreground and background semantics alongside 3D spatial geometry to precisely control the generation of both elements. To improve the synthesis of fine-grained foreground objects, particularly complex and distant ones, we propose a Foreground-Aware Mask (FGM) denoising loss function. Additionally, we develop the Semantic Fusion Attention (SFA) mechanism to dynamically prioritize relevant information and suppress noise, enabling more effective multimodal fusion. Finally, to ensure high-quality image-to-video generation, we introduce the Reward-Guided Diffusion (RGD) framework, which maintains global consistency and semantic coherence in generated videos. Extensive experiments demonstrate that DualDiff achieves state-of-the-art (SOTA) performance across multiple datasets. On the NuScenes dataset, DualDiff reduces the FID score by 4.09% compared to the best baseline. In downstream tasks, such as BEV segmentation, our method improves vehicle mIoU by 4.50% and road mIoU by 1.70%, while in BEV 3D object detection, the foreground mAP increases by 1.46%. Code will be made available at https://github.com/yangzhaojason/DualDiff.
AUD-TGN: Advancing Action Unit Detection with Temporal Convolution and GPT-2 in Wild Audiovisual Contexts
Mar 20, 2024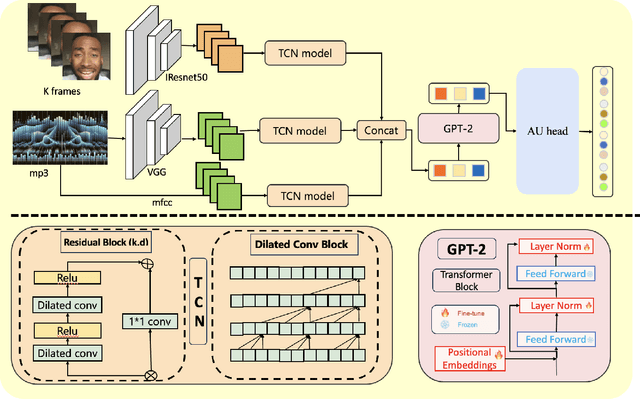
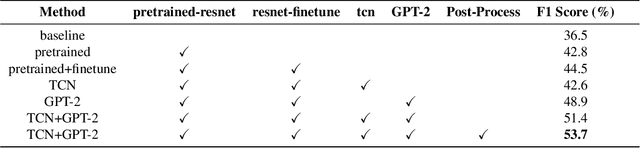
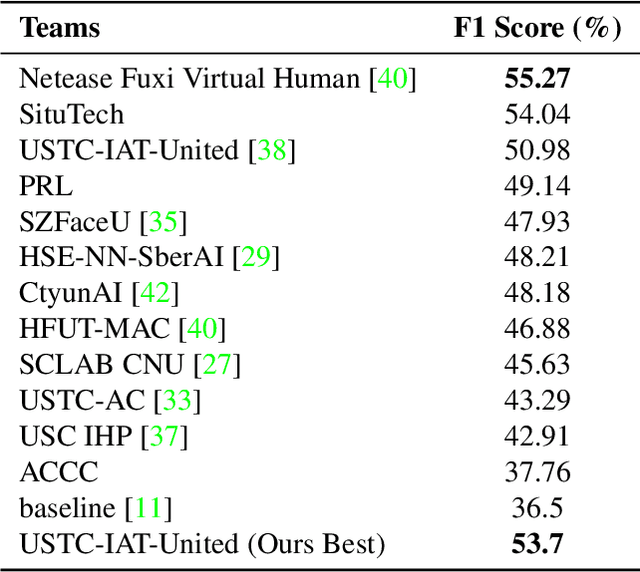
Leveraging the synergy of both audio data and visual data is essential for understanding human emotions and behaviors, especially in in-the-wild setting. Traditional methods for integrating such multimodal information often stumble, leading to less-than-ideal outcomes in the task of facial action unit detection. To overcome these shortcomings, we propose a novel approach utilizing audio-visual multimodal data. This method enhances audio feature extraction by leveraging Mel Frequency Cepstral Coefficients (MFCC) and Log-Mel spectrogram features alongside a pre-trained VGGish network. Moreover, this paper adaptively captures fusion features across modalities by modeling the temporal relationships, and ultilizes a pre-trained GPT-2 model for sophisticated context-aware fusion of multimodal information. Our method notably improves the accuracy of AU detection by understanding the temporal and contextual nuances of the data, showcasing significant advancements in the comprehension of intricate scenarios. These findings underscore the potential of integrating temporal dynamics and contextual interpretation, paving the way for future research endeavors.
Multimodal Fusion Method with Spatiotemporal Sequences and Relationship Learning for Valence-Arousal Estimation
Mar 20, 2024


This paper presents our approach for the VA (Valence-Arousal) estimation task in the ABAW6 competition. We devised a comprehensive model by preprocessing video frames and audio segments to extract visual and audio features. Through the utilization of Temporal Convolutional Network (TCN) modules, we effectively captured the temporal and spatial correlations between these features. Subsequently, we employed a Transformer encoder structure to learn long-range dependencies, thereby enhancing the model's performance and generalization ability. Our method leverages a multimodal data fusion approach, integrating pre-trained audio and video backbones for feature extraction, followed by TCN-based spatiotemporal encoding and Transformer-based temporal information capture. Experimental results demonstrate the effectiveness of our approach, achieving competitive performance in VA estimation on the AffWild2 dataset.
Exploring Facial Expression Recognition through Semi-Supervised Pretraining and Temporal Modeling
Mar 19, 2024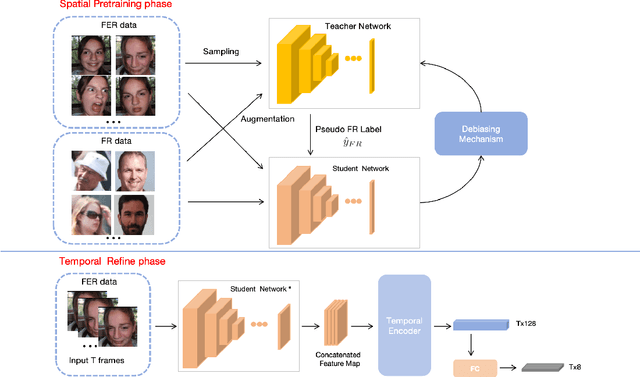

Facial Expression Recognition (FER) plays a crucial role in computer vision and finds extensive applications across various fields. This paper aims to present our approach for the upcoming 6th Affective Behavior Analysis in-the-Wild (ABAW) competition, scheduled to be held at CVPR2024. In the facial expression recognition task, The limited size of the FER dataset poses a challenge to the expression recognition model's generalization ability, resulting in subpar recognition performance. To address this problem, we employ a semi-supervised learning technique to generate expression category pseudo-labels for unlabeled face data. At the same time, we uniformly sampled the labeled facial expression samples and implemented a debiased feedback learning strategy to address the problem of category imbalance in the dataset and the possible data bias in semi-supervised learning. Moreover, to further compensate for the limitation and bias of features obtained only from static images, we introduced a Temporal Encoder to learn and capture temporal relationships between neighbouring expression image features. In the 6th ABAW competition, our method achieved outstanding results on the official validation set, a result that fully confirms the effectiveness and competitiveness of our proposed method.
Local Region Perception and Relationship Learning Combined with Feature Fusion for Facial Action Unit Detection
Mar 19, 2023



Human affective behavior analysis plays a vital role in human-computer interaction (HCI) systems. In this paper, we introduce our submission to the CVPR 2023 Competition on Affective Behavior Analysis in-the-wild (ABAW). We propose a single-stage trained AU detection framework. Specifically, in order to effectively extract facial local region features related to AU detection, we use a local region perception module to effectively extract features of different AUs. Meanwhile, we use a graph neural network-based relational learning module to capture the relationship between AUs. In addition, considering the role of the overall feature of the target face on AU detection, we also use the feature fusion module to fuse the feature information extracted by the backbone network and the AU feature information extracted by the relationship learning module. We also adopted some sampling methods, data augmentation techniques and post-processing strategies to further improve the performance of the model.
Exploring Large-scale Unlabeled Faces to Enhance Facial Expression Recognition
Mar 19, 2023Facial Expression Recognition (FER) is an important task in computer vision and has wide applications in human-computer interaction, intelligent security, emotion analysis, and other fields. However, the limited size of FER datasets limits the generalization ability of expression recognition models, resulting in ineffective model performance. To address this problem, we propose a semi-supervised learning framework that utilizes unlabeled face data to train expression recognition models effectively. Our method uses a dynamic threshold module (\textbf{DTM}) that can adaptively adjust the confidence threshold to fully utilize the face recognition (FR) data to generate pseudo-labels, thus improving the model's ability to model facial expressions. In the ABAW5 EXPR task, our method achieved excellent results on the official validation set.
A Dual Branch Network for Emotional Reaction Intensity Estimation
Mar 16, 2023Emotional Reaction Intensity(ERI) estimation is an important task in multimodal scenarios, and has fundamental applications in medicine, safe driving and other fields. In this paper, we propose a solution to the ERI challenge of the fifth Affective Behavior Analysis in-the-wild(ABAW), a dual-branch based multi-output regression model. The spatial attention is used to better extract visual features, and the Mel-Frequency Cepstral Coefficients technology extracts acoustic features, and a method named modality dropout is added to fusion multimodal features. Our method achieves excellent results on the official validation set.