 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Model-based Evaluation of Neuropsychiatric Disorders: A Lifespan-Inclusive, Multi-Modal, and Multi-Lingual Study
Dec 24, 2025Neuropsychiatric disorders, such as Alzheimer's disease (AD), depression, and autism spectrum disorder (ASD), are characterized by linguistic and acoustic abnormalities, offering potential biomarkers for early detection. Despite the promise of multi-modal approaches, challenges like multi-lingual generalization and the absence of a unified evaluation framework persist. To address these gaps, we propose FEND (Foundation model-based Evaluation of Neuropsychiatric Disorders), a comprehensive multi-modal framework integrating speech and text modalities for detecting AD, depression, and ASD across the lifespan. Leveraging 13 multi-lingual datasets spanning English, Chinese, Greek, French, and Dutch, we systematically evaluate multi-modal fusion performance. Our results show that multi-modal fusion excels in AD and depression detection but underperforms in ASD due to dataset heterogeneity. We also identify modality imbalance as a prevalent issue, where multi-modal fusion fails to surpass the best mono-modal models. Cross-corpus experiments reveal robust performance in task- and language-consistent scenarios but noticeable degradation in multi-lingual and task-heterogeneous settings. By providing extensive benchmarks and a detailed analysis of performance-influencing factors, FEND advances the field of automated, lifespan-inclusive, and multi-lingual neuropsychiatric disorder assessment. We encourage researchers to adopt the FEND framework for fair comparisons and reproducible research.
DualDiff+: Dual-Branch Diffusion for High-Fidelity Video Generation with Reward Guidance
Mar 05, 2025



Accurate and high-fidelity driving scene reconstruction demands the effective utilization of comprehensive scene information as conditional inputs. Existing methods predominantly rely on 3D bounding boxes and BEV road maps for foreground and background control, which fail to capture the full complexity of driving scenes and adequately integrate multimodal information. In this work, we present DualDiff, a dual-branch conditional diffusion model designed to enhance driving scene generation across multiple views and video sequences. Specifically, we introduce Occupancy Ray-shape Sampling (ORS) as a conditional input, offering rich foreground and background semantics alongside 3D spatial geometry to precisely control the generation of both elements. To improve the synthesis of fine-grained foreground objects, particularly complex and distant ones, we propose a Foreground-Aware Mask (FGM) denoising loss function. Additionally, we develop the Semantic Fusion Attention (SFA) mechanism to dynamically prioritize relevant information and suppress noise, enabling more effective multimodal fusion. Finally, to ensure high-quality image-to-video generation, we introduce the Reward-Guided Diffusion (RGD) framework, which maintains global consistency and semantic coherence in generated videos. Extensive experiments demonstrate that DualDiff achieves state-of-the-art (SOTA) performance across multiple datasets. On the NuScenes dataset, DualDiff reduces the FID score by 4.09% compared to the best baseline. In downstream tasks, such as BEV segmentation, our method improves vehicle mIoU by 4.50% and road mIoU by 1.70%, while in BEV 3D object detection, the foreground mAP increases by 1.46%. Code will be made available at https://github.com/yangzhaojason/DualDiff.
Re-Parameterization of Lightweight Transformer for On-Device Speech Emotion Recognition
Nov 14, 2024
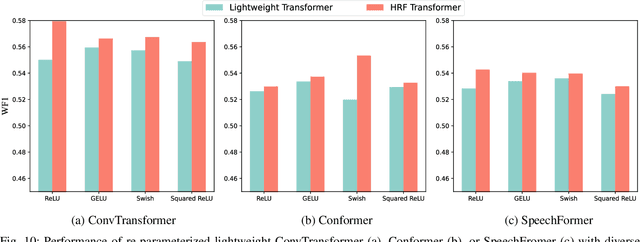
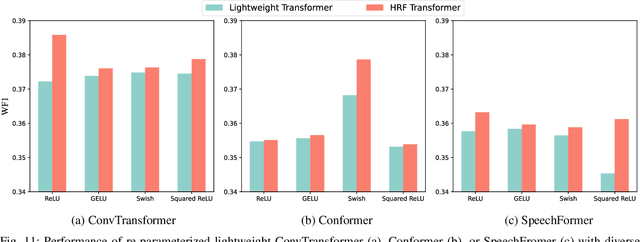
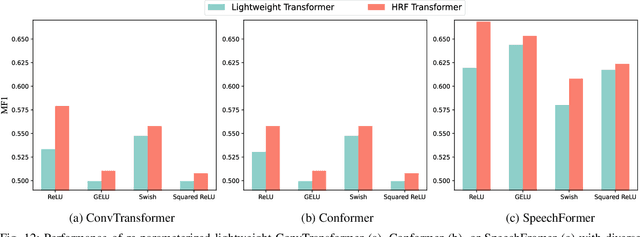
With the increasing implementation of machine learning models on edge or Internet-of-Things (IoT) devices, deploying advanced models on resource-constrained IoT devices remains challenging. Transformer models, a currently dominant neural architecture, have achieved great success in broad domains but their complexity hinders its deployment on IoT devices with limited computation capability and storage size. Although many model compression approaches have been explored, they often suffer from notorious performance degradation. To address this issue, we introduce a new method, namely Transformer Re-parameterization, to boost the performance of lightweight Transformer models. It consists of two processes: the High-Rank Factorization (HRF) process in the training stage and the deHigh-Rank Factorization (deHRF) process in the inference stage. In the former process, we insert an additional linear layer before the Feed-Forward Network (FFN) of the lightweight Transformer. It is supposed that the inserted HRF layers can enhance the model learning capability. In the later process, the auxiliary HRF layer will be merged together with the following FFN layer into one linear layer and thus recover the original structure of the lightweight model. To examine the effectiveness of the proposed method, we evaluate it on three widely used Transformer variants, i.e., ConvTransformer, Conformer, and SpeechFormer networks, in the application of speech emotion recognition on the IEMOCAP, M3ED and DAIC-WOZ datasets. Experimental results show that our proposed method consistently improves the performance of lightweight Transformers, even making them comparable to large models. The proposed re-parameterization approach enables advanced Transformer models to be deployed on resource-constrained IoT devices.
ParaLBench: A Large-Scale Benchmark for Computational Paralinguistics over Acoustic Foundation Models
Nov 14, 2024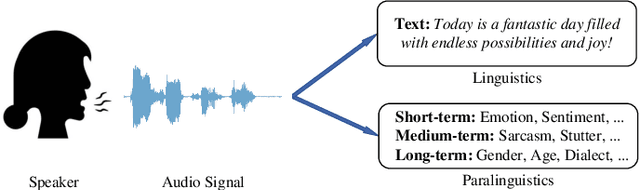
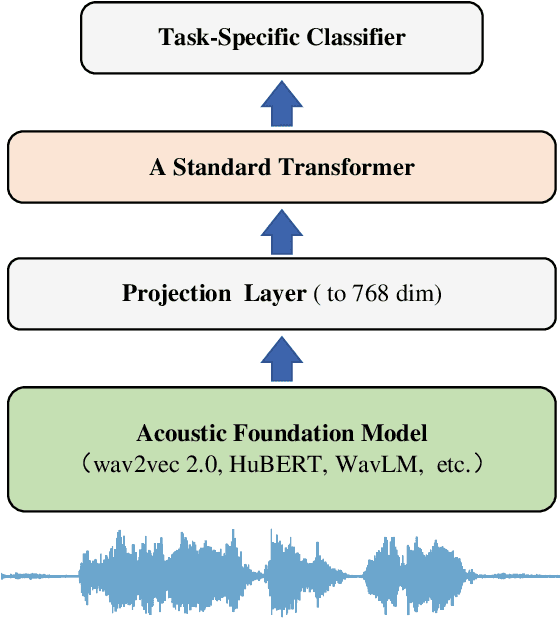
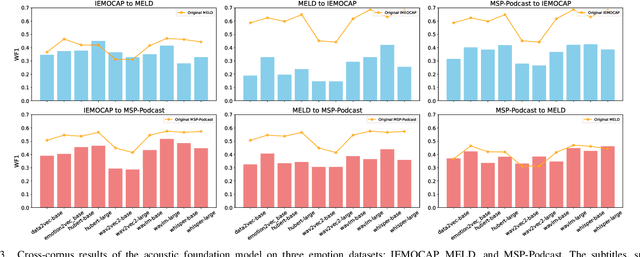
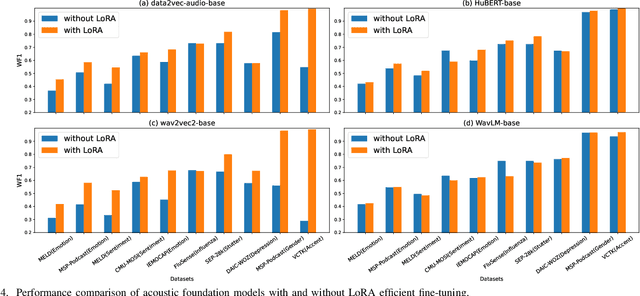
Computational paralinguistics (ComParal) aims to develop algorithms and models to automatically detect, analyze, and interpret non-verbal information from speech communication, e. g., emotion, health state, age, and gender. Despite its rapid progress, it heavily depends on sophisticatedly designed models given specific paralinguistic tasks. Thus, the heterogeneity and diversity of ComParal models largely prevent the realistic implementation of ComParal models. Recently, with the advent of acoustic foundation models because of self-supervised learning, developing more generic models that can efficiently perceive a plethora of paralinguistic information has become an active topic in speech processing. However, it lacks a unified evaluation framework for a fair and consistent performance comparison. To bridge this gap, we conduct a large-scale benchmark, namely ParaLBench, which concentrates on standardizing the evaluation process of diverse paralinguistic tasks, including critical aspects of affective computing such as emotion recognition and emotion dimensions prediction, over different acoustic foundation models. This benchmark contains ten datasets with thirteen distinct paralinguistic tasks, covering short-, medium- and long-term characteristics. Each task is carried out on 14 acoustic foundation models under a unified evaluation framework, which allows for an unbiased methodological comparison and offers a grounded reference for the ComParal community. Based on the insights gained from ParaLBench, we also point out potential research directions, i.e., the cross-corpus generalizability, to propel ComParal research in the future. The code associated with this study will be available to foster the transparency and replicability of this work for succeeding researchers.
TernaryLLM: Ternarized Large Language Model
Jun 11, 2024
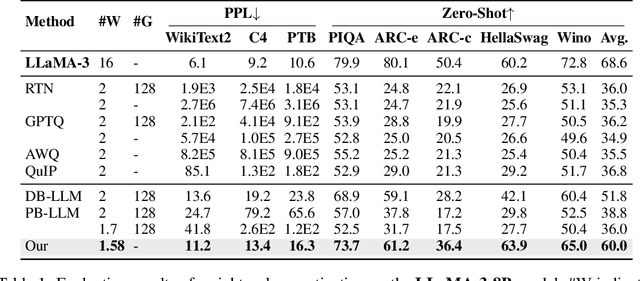

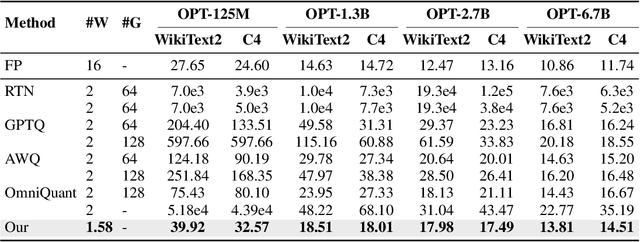
Large language models (LLMs) have achieved remarkable performance on Natural Language Processing (NLP) tasks, but they are hindered by high computational costs and memory requirements. Ternarization, an extreme form of quantization, offers a solution by reducing memory usage and enabling energy-efficient floating-point additions. However, applying ternarization to LLMs faces challenges stemming from outliers in both weights and activations. In this work, observing asymmetric outliers and non-zero means in weights, we introduce Dual Learnable Ternarization (DLT), which enables both scales and shifts to be learnable. We also propose Outlier-Friendly Feature Knowledge Distillation (OFF) to recover the information lost in extremely low-bit quantization. The proposed OFF can incorporate semantic information and is insensitive to outliers. At the core of OFF is maximizing the mutual information between features in ternarized and floating-point models using cosine similarity. Extensive experiments demonstrate that our TernaryLLM surpasses previous low-bit quantization methods on the standard text generation and zero-shot benchmarks for different LLM families. Specifically, for one of the most powerful open-source models, LLaMA-3, our approach (W1.58A16) outperforms the previous state-of-the-art method (W2A16) by 5.8 in terms of perplexity on C4 and by 8.2% in terms of average accuracy on zero-shot tasks.
LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
Jun 05, 2024



In this paper, we present a light-weight detection transformer, LW-DETR, which outperforms YOLOs for real-time object detection. The architecture is a simple stack of a ViT encoder, a projector, and a shallow DETR decoder. Our approach leverages recent advanced techniques, such as training-effective techniques, e.g., improved loss and pretraining, and interleaved window and global attentions for reducing the ViT encoder complexity. We improve the ViT encoder by aggregating multi-level feature maps, and the intermediate and final feature maps in the ViT encoder, forming richer feature maps, and introduce window-major feature map organization for improving the efficiency of interleaved attention computation. Experimental results demonstrate that the proposed approach is superior over existing real-time detectors, e.g., YOLO and its variants, on COCO and other benchmark datasets. Code and models are available at (https://github.com/Atten4Vis/LW-DETR).
HAFFormer: A Hierarchical Attention-Free Framework for Alzheimer's Disease Detection From Spontaneous Speech
May 07, 2024


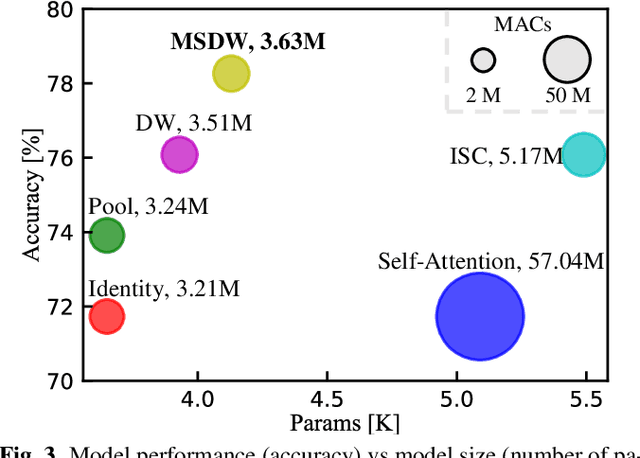
Automatically detecting Alzheimer's Disease (AD) from spontaneous speech plays an important role in its early diagnosis. Recent approaches highly rely on the Transformer architectures due to its efficiency in modelling long-range context dependencies. However, the quadratic increase in computational complexity associated with self-attention and the length of audio poses a challenge when deploying such models on edge devices. In this context, we construct a novel framework, namely Hierarchical Attention-Free Transformer (HAFFormer), to better deal with long speech for AD detection. Specifically, we employ an attention-free module of Multi-Scale Depthwise Convolution to replace the self-attention and thus avoid the expensive computation, and a GELU-based Gated Linear Unit to replace the feedforward layer, aiming to automatically filter out the redundant information. Moreover, we design a hierarchical structure to force it to learn a variety of information grains, from the frame level to the dialogue level. By conducting extensive experiments on the ADReSS-M dataset, the introduced HAFFormer can achieve competitive results (82.6% accuracy) with other recent work, but with significant computational complexity and model size reduction compared to the standard Transformer. This shows the efficiency of HAFFormer in dealing with long audio for AD detection.
Soft Threshold Ternary Networks
Apr 04, 2022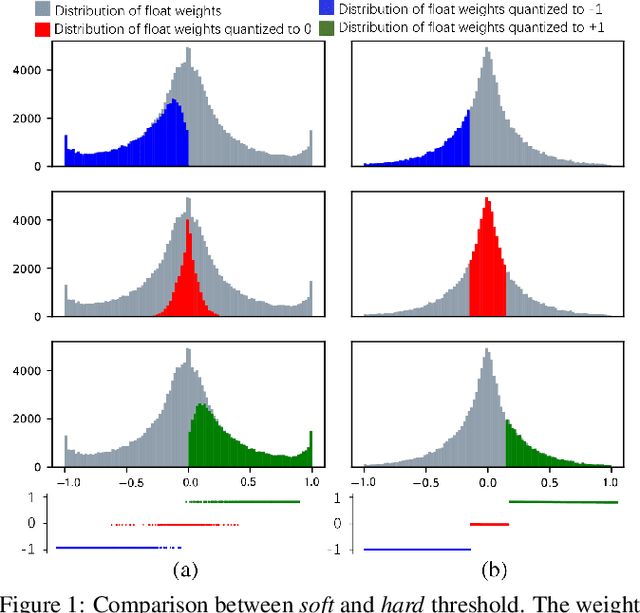

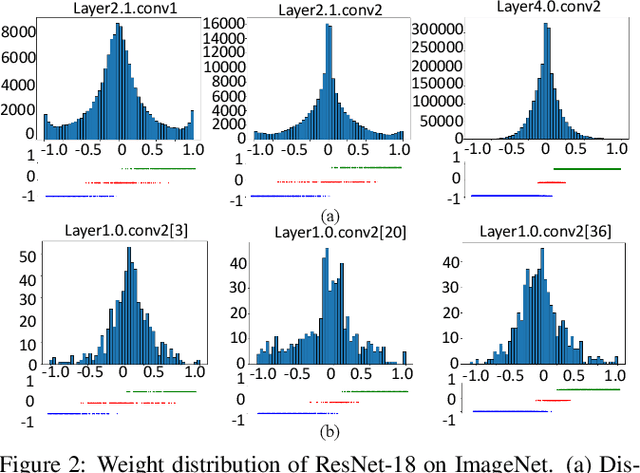

Large neural networks are difficult to deploy on mobile devices because of intensive computation and storage. To alleviate it, we study ternarization, a balance between efficiency and accuracy that quantizes both weights and activations into ternary values. In previous ternarized neural networks, a hard threshold {\Delta} is introduced to determine quantization intervals. Although the selection of {\Delta} greatly affects the training results, previous works estimate {\Delta} via an approximation or treat it as a hyper-parameter, which is suboptimal. In this paper, we present the Soft Threshold Ternary Networks (STTN), which enables the model to automatically determine quantization intervals instead of depending on a hard threshold. Concretely, we replace the original ternary kernel with the addition of two binary kernels at training time, where ternary values are determined by the combination of two corresponding binary values. At inference time, we add up the two binary kernels to obtain a single ternary kernel. Our method dramatically outperforms current state-of-the-arts, lowering the performance gap between full-precision networks and extreme low bit networks. Experiments on ImageNet with ResNet-18 (Top-1 66.2%) achieves new state-of-the-art. Update: In this version, we further fine-tune the experimental hyperparameters and training procedure. The latest STTN shows that ResNet-18 with ternary weights and ternary activations achieves up to 68.2% Top-1 accuracy on ImageNet. Code is available at: github.com/WeixiangXu/STTN.
Improving Binary Neural Networks through Fully Utilizing Latent Weights
Oct 12, 2021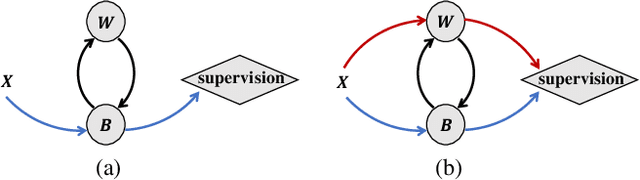

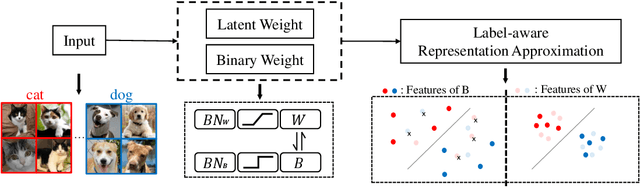
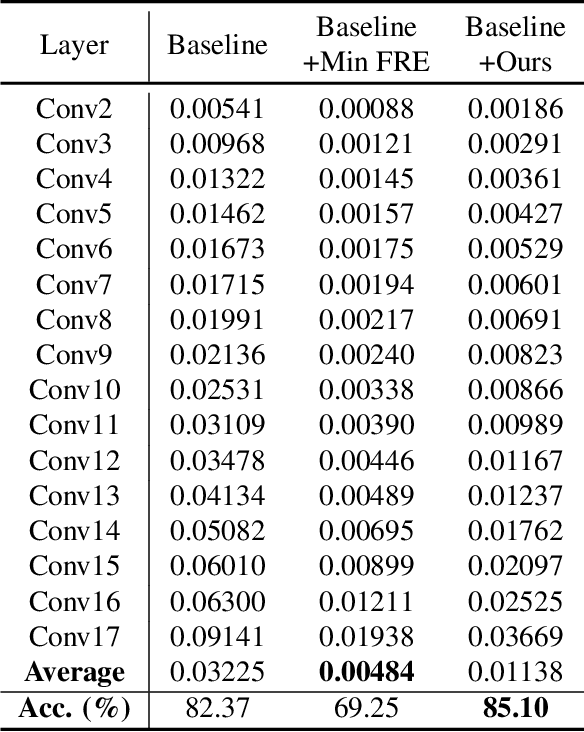
Binary Neural Networks (BNNs) rely on a real-valued auxiliary variable W to help binary training. However, pioneering binary works only use W to accumulate gradient updates during backward propagation, which can not fully exploit its power and may hinder novel advances in BNNs. In this work, we explore the role of W in training besides acting as a latent variable. Notably, we propose to add W into the computation graph, making it perform as a real-valued feature extractor to aid the binary training. We make different attempts on how to utilize the real-valued weights and propose a specialized supervision. Visualization experiments qualitatively verify the effectiveness of our approach in making it easier to distinguish between different categories. Quantitative experiments show that our approach outperforms current state-of-the-arts, further closing the performance gap between floating-point networks and BNNs. Evaluation on ImageNet with ResNet-18 (Top-1 63.4%), ResNet-34 (Top-1 67.0%) achieves new state-of-the-art.
Architecture Aware Latency Constrained Sparse Neural Networks
Sep 01, 2021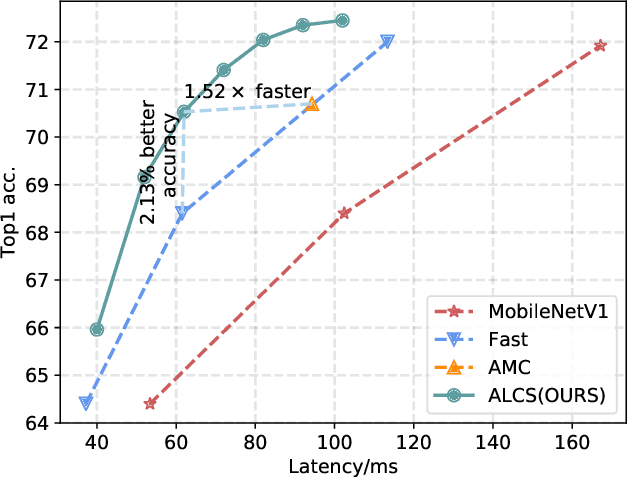
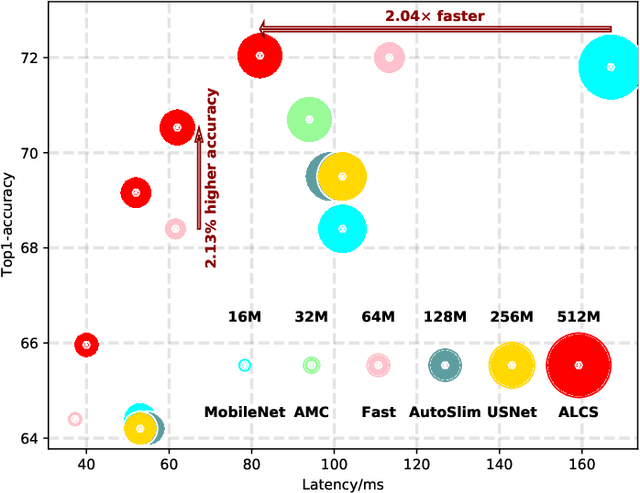
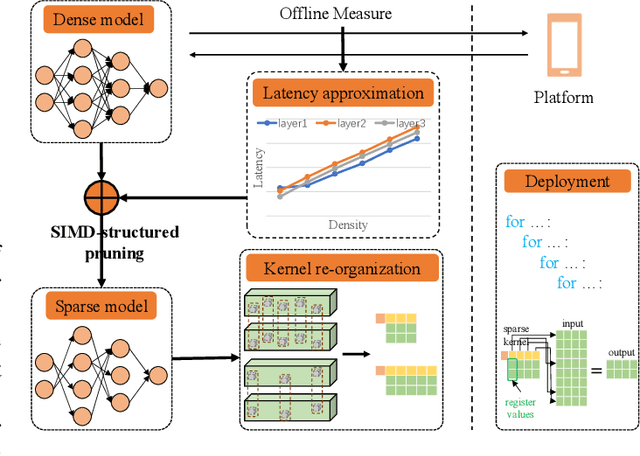
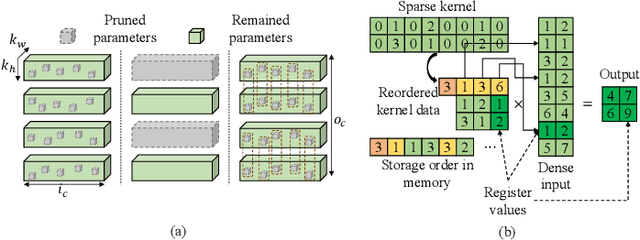
Acceleration of deep neural networks to meet a specific latency constraint is essential for their deployment on mobile devices. In this paper, we design an architecture aware latency constrained sparse (ALCS) framework to prune and accelerate CNN models. Taking modern mobile computation architectures into consideration, we propose Single Instruction Multiple Data (SIMD)-structured pruning, along with a novel sparse convolution algorithm for efficient computation. Besides, we propose to estimate the run time of sparse models with piece-wise linear interpolation. The whole latency constrained pruning task is formulated as a constrained optimization problem that can be efficiently solved with Alternating Direction Method of Multipliers (ADMM). Extensive experiments show that our system-algorithm co-design framework can achieve much better Pareto frontier among network accuracy and latency on resource-constrained mobile devices.