 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSissi: Zero-shot Style-guided Image Synthesis via Semantic-style Integration
Jan 10, 2026Text-guided image generation has advanced rapidly with large-scale diffusion models, yet achieving precise stylization with visual exemplars remains difficult. Existing approaches often depend on task-specific retraining or expensive inversion procedures, which can compromise content integrity, reduce style fidelity, and lead to an unsatisfactory trade-off between semantic prompt adherence and style alignment. In this work, we introduce a training-free framework that reformulates style-guided synthesis as an in-context learning task. Guided by textual semantic prompts, our method concatenates a reference style image with a masked target image, leveraging a pretrained ReFlow-based inpainting model to seamlessly integrate semantic content with the desired style through multimodal attention fusion. We further analyze the imbalance and noise sensitivity inherent in multimodal attention fusion and propose a Dynamic Semantic-Style Integration (DSSI) mechanism that reweights attention between textual semantic and style visual tokens, effectively resolving guidance conflicts and enhancing output coherence. Experiments show that our approach achieves high-fidelity stylization with superior semantic-style balance and visual quality, offering a simple yet powerful alternative to complex, artifact-prone prior methods.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Multi-turn Consistent Image Editing
May 07, 2025Many real-world applications, such as interactive photo retouching, artistic content creation, and product design, require flexible and iterative image editing. However, existing image editing methods primarily focus on achieving the desired modifications in a single step, which often struggles with ambiguous user intent, complex transformations, or the need for progressive refinements. As a result, these methods frequently produce inconsistent outcomes or fail to meet user expectations. To address these challenges, we propose a multi-turn image editing framework that enables users to iteratively refine their edits, progressively achieving more satisfactory results. Our approach leverages flow matching for accurate image inversion and a dual-objective Linear Quadratic Regulators (LQR) for stable sampling, effectively mitigating error accumulation. Additionally, by analyzing the layer-wise roles of transformers, we introduce a adaptive attention highlighting method that enhances editability while preserving multi-turn coherence. Extensive experiments demonstrate that our framework significantly improves edit success rates and visual fidelity compared to existing methods.
Z-Magic: Zero-shot Multiple Attributes Guided Image Creator
Mar 15, 2025The customization of multiple attributes has gained popularity with the rising demand for personalized content creation. Despite promising empirical results, the contextual coherence between different attributes has been largely overlooked. In this paper, we argue that subsequent attributes should follow the multivariable conditional distribution introduced by former attribute creation. In light of this, we reformulate multi-attribute creation from a conditional probability theory perspective and tackle the challenging zero-shot setting. By explicitly modeling the dependencies between attributes, we further enhance the coherence of generated images across diverse attribute combinations. Furthermore, we identify connections between multi-attribute customization and multi-task learning, effectively addressing the high computing cost encountered in multi-attribute synthesis. Extensive experiments demonstrate that Z-Magic outperforms existing models in zero-shot image generation, with broad implications for AI-driven design and creative applications.
FireFlow: Fast Inversion of Rectified Flow for Image Semantic Editing
Dec 10, 2024



Though Rectified Flows (ReFlows) with distillation offers a promising way for fast sampling, its fast inversion transforms images back to structured noise for recovery and following editing remains unsolved. This paper introduces FireFlow, a simple yet effective zero-shot approach that inherits the startling capacity of ReFlow-based models (such as FLUX) in generation while extending its capabilities to accurate inversion and editing in $8$ steps. We first demonstrate that a carefully designed numerical solver is pivotal for ReFlow inversion, enabling accurate inversion and reconstruction with the precision of a second-order solver while maintaining the practical efficiency of a first-order Euler method. This solver achieves a $3\times$ runtime speedup compared to state-of-the-art ReFlow inversion and editing techniques, while delivering smaller reconstruction errors and superior editing results in a training-free mode. The code is available at $\href{https://github.com/HolmesShuan/FireFlow}{this URL}$.
Z-STAR+: A Zero-shot Style Transfer Method via Adjusting Style Distribution
Nov 28, 2024



Style transfer presents a significant challenge, primarily centered on identifying an appropriate style representation. Conventional methods employ style loss, derived from second-order statistics or contrastive learning, to constrain style representation in the stylized result. However, these pre-defined style representations often limit stylistic expression, leading to artifacts. In contrast to existing approaches, we have discovered that latent features in vanilla diffusion models inherently contain natural style and content distributions. This allows for direct extraction of style information and seamless integration of generative priors into the content image without necessitating retraining. Our method adopts dual denoising paths to represent content and style references in latent space, subsequently guiding the content image denoising process with style latent codes. We introduce a Cross-attention Reweighting module that utilizes local content features to query style image information best suited to the input patch, thereby aligning the style distribution of the stylized results with that of the style image. Furthermore, we design a scaled adaptive instance normalization to mitigate inconsistencies in color distribution between style and stylized images on a global scale. Through theoretical analysis and extensive experimentation, we demonstrate the effectiveness and superiority of our diffusion-based \uline{z}ero-shot \uline{s}tyle \uline{t}ransfer via \uline{a}djusting style dist\uline{r}ibution, termed Z-STAR+.
$Z^*$: Zero-shot Style Transfer via Attention Rearrangement
Nov 25, 2023

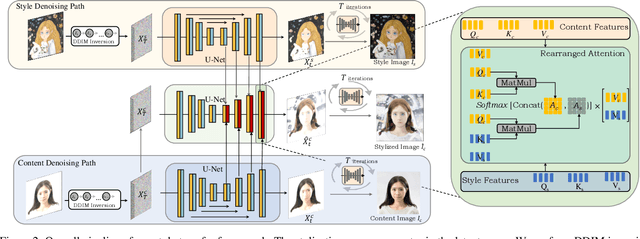
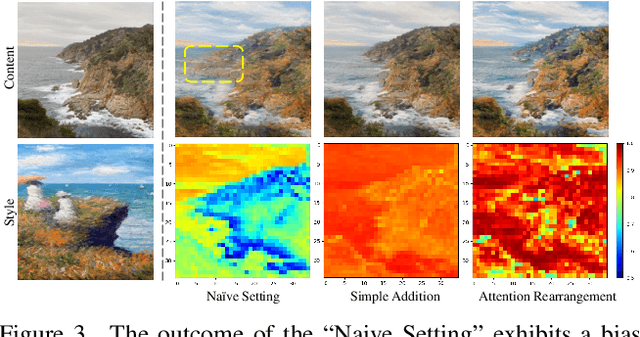
Despite the remarkable progress in image style transfer, formulating style in the context of art is inherently subjective and challenging. In contrast to existing learning/tuning methods, this study shows that vanilla diffusion models can directly extract style information and seamlessly integrate the generative prior into the content image without retraining. Specifically, we adopt dual denoising paths to represent content/style references in latent space and then guide the content image denoising process with style latent codes. We further reveal that the cross-attention mechanism in latent diffusion models tends to blend the content and style images, resulting in stylized outputs that deviate from the original content image. To overcome this limitation, we introduce a cross-attention rearrangement strategy. Through theoretical analysis and experiments, we demonstrate the effectiveness and superiority of the diffusion-based $\underline{Z}$ero-shot $\underline{S}$tyle $\underline{T}$ransfer via $\underline{A}$ttention $\underline{R}$earrangement, Z-STAR.
Singular Value Fine-tuning: Few-shot Segmentation requires Few-parameters Fine-tuning
Jun 13, 2022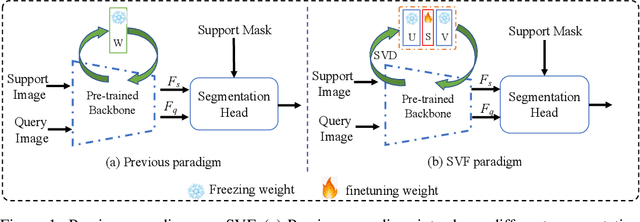
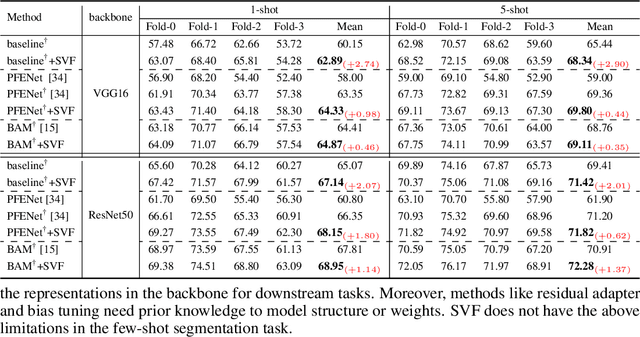
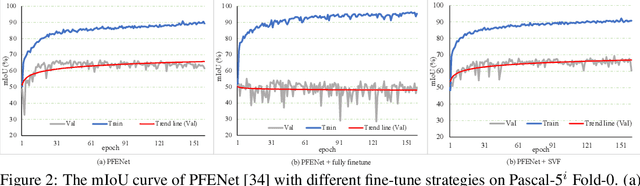
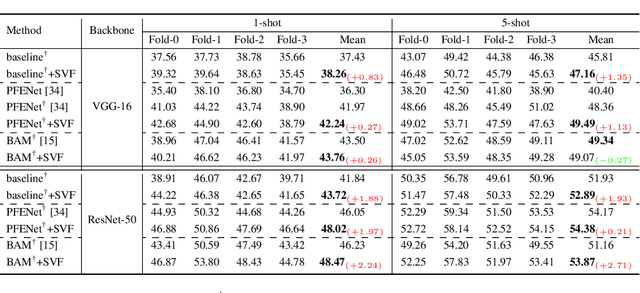
Freezing the pre-trained backbone has become a standard paradigm to avoid overfitting in few-shot segmentation. In this paper, we rethink the paradigm and explore a new regime: {\em fine-tuning a small part of parameters in the backbone}. We present a solution to overcome the overfitting problem, leading to better model generalization on learning novel classes. Our method decomposes backbone parameters into three successive matrices via the Singular Value Decomposition (SVD), then {\em only fine-tunes the singular values} and keeps others frozen. The above design allows the model to adjust feature representations on novel classes while maintaining semantic clues within the pre-trained backbone. We evaluate our {\em Singular Value Fine-tuning (SVF)} approach on various few-shot segmentation methods with different backbones. We achieve state-of-the-art results on both Pascal-5$^i$ and COCO-20$^i$ across 1-shot and 5-shot settings. Hopefully, this simple baseline will encourage researchers to rethink the role of backbone fine-tuning in few-shot settings. The source code and models will be available at \url{https://github.com/syp2ysy/SVF}.
Soft Threshold Ternary Networks
Apr 04, 2022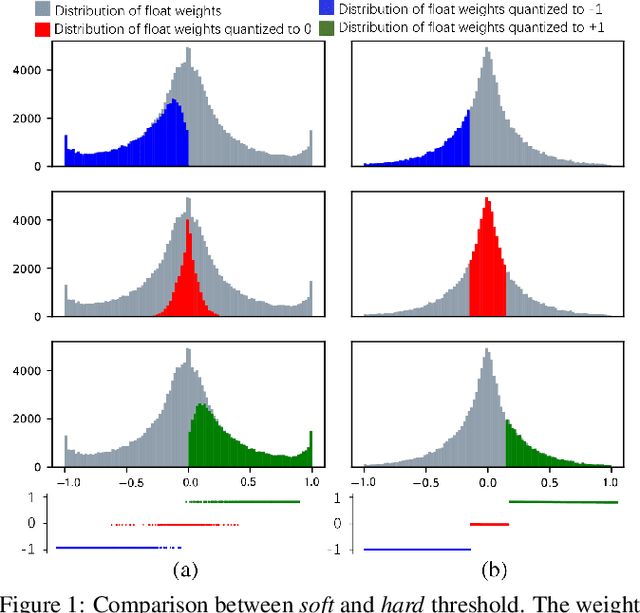

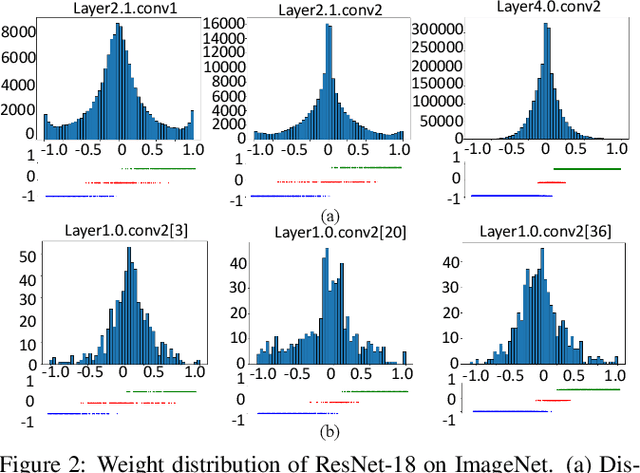

Large neural networks are difficult to deploy on mobile devices because of intensive computation and storage. To alleviate it, we study ternarization, a balance between efficiency and accuracy that quantizes both weights and activations into ternary values. In previous ternarized neural networks, a hard threshold {\Delta} is introduced to determine quantization intervals. Although the selection of {\Delta} greatly affects the training results, previous works estimate {\Delta} via an approximation or treat it as a hyper-parameter, which is suboptimal. In this paper, we present the Soft Threshold Ternary Networks (STTN), which enables the model to automatically determine quantization intervals instead of depending on a hard threshold. Concretely, we replace the original ternary kernel with the addition of two binary kernels at training time, where ternary values are determined by the combination of two corresponding binary values. At inference time, we add up the two binary kernels to obtain a single ternary kernel. Our method dramatically outperforms current state-of-the-arts, lowering the performance gap between full-precision networks and extreme low bit networks. Experiments on ImageNet with ResNet-18 (Top-1 66.2%) achieves new state-of-the-art. Update: In this version, we further fine-tune the experimental hyperparameters and training procedure. The latest STTN shows that ResNet-18 with ternary weights and ternary activations achieves up to 68.2% Top-1 accuracy on ImageNet. Code is available at: github.com/WeixiangXu/STTN.
Revisiting L1 Loss in Super-Resolution: A Probabilistic View and Beyond
Jan 25, 2022Super-resolution as an ill-posed problem has many high-resolution candidates for a low-resolution input. However, the popular $\ell_1$ loss used to best fit the given HR image fails to consider this fundamental property of non-uniqueness in image restoration. In this work, we fix the missing piece in $\ell_1$ loss by formulating super-resolution with neural networks as a probabilistic model. It shows that $\ell_1$ loss is equivalent to a degraded likelihood function that removes the randomness from the learning process. By introducing a data-adaptive random variable, we present a new objective function that aims at minimizing the expectation of the reconstruction error over all plausible solutions. The experimental results show consistent improvements on mainstream architectures, with no extra parameter or computing cost at inference time.