 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSissi: Zero-shot Style-guided Image Synthesis via Semantic-style Integration
Jan 10, 2026Text-guided image generation has advanced rapidly with large-scale diffusion models, yet achieving precise stylization with visual exemplars remains difficult. Existing approaches often depend on task-specific retraining or expensive inversion procedures, which can compromise content integrity, reduce style fidelity, and lead to an unsatisfactory trade-off between semantic prompt adherence and style alignment. In this work, we introduce a training-free framework that reformulates style-guided synthesis as an in-context learning task. Guided by textual semantic prompts, our method concatenates a reference style image with a masked target image, leveraging a pretrained ReFlow-based inpainting model to seamlessly integrate semantic content with the desired style through multimodal attention fusion. We further analyze the imbalance and noise sensitivity inherent in multimodal attention fusion and propose a Dynamic Semantic-Style Integration (DSSI) mechanism that reweights attention between textual semantic and style visual tokens, effectively resolving guidance conflicts and enhancing output coherence. Experiments show that our approach achieves high-fidelity stylization with superior semantic-style balance and visual quality, offering a simple yet powerful alternative to complex, artifact-prone prior methods.
Multi-turn Consistent Image Editing
May 07, 2025Many real-world applications, such as interactive photo retouching, artistic content creation, and product design, require flexible and iterative image editing. However, existing image editing methods primarily focus on achieving the desired modifications in a single step, which often struggles with ambiguous user intent, complex transformations, or the need for progressive refinements. As a result, these methods frequently produce inconsistent outcomes or fail to meet user expectations. To address these challenges, we propose a multi-turn image editing framework that enables users to iteratively refine their edits, progressively achieving more satisfactory results. Our approach leverages flow matching for accurate image inversion and a dual-objective Linear Quadratic Regulators (LQR) for stable sampling, effectively mitigating error accumulation. Additionally, by analyzing the layer-wise roles of transformers, we introduce a adaptive attention highlighting method that enhances editability while preserving multi-turn coherence. Extensive experiments demonstrate that our framework significantly improves edit success rates and visual fidelity compared to existing methods.
Z-Magic: Zero-shot Multiple Attributes Guided Image Creator
Mar 15, 2025The customization of multiple attributes has gained popularity with the rising demand for personalized content creation. Despite promising empirical results, the contextual coherence between different attributes has been largely overlooked. In this paper, we argue that subsequent attributes should follow the multivariable conditional distribution introduced by former attribute creation. In light of this, we reformulate multi-attribute creation from a conditional probability theory perspective and tackle the challenging zero-shot setting. By explicitly modeling the dependencies between attributes, we further enhance the coherence of generated images across diverse attribute combinations. Furthermore, we identify connections between multi-attribute customization and multi-task learning, effectively addressing the high computing cost encountered in multi-attribute synthesis. Extensive experiments demonstrate that Z-Magic outperforms existing models in zero-shot image generation, with broad implications for AI-driven design and creative applications.
FireFlow: Fast Inversion of Rectified Flow for Image Semantic Editing
Dec 10, 2024



Though Rectified Flows (ReFlows) with distillation offers a promising way for fast sampling, its fast inversion transforms images back to structured noise for recovery and following editing remains unsolved. This paper introduces FireFlow, a simple yet effective zero-shot approach that inherits the startling capacity of ReFlow-based models (such as FLUX) in generation while extending its capabilities to accurate inversion and editing in $8$ steps. We first demonstrate that a carefully designed numerical solver is pivotal for ReFlow inversion, enabling accurate inversion and reconstruction with the precision of a second-order solver while maintaining the practical efficiency of a first-order Euler method. This solver achieves a $3\times$ runtime speedup compared to state-of-the-art ReFlow inversion and editing techniques, while delivering smaller reconstruction errors and superior editing results in a training-free mode. The code is available at $\href{https://github.com/HolmesShuan/FireFlow}{this URL}$.
Z-STAR+: A Zero-shot Style Transfer Method via Adjusting Style Distribution
Nov 28, 2024



Style transfer presents a significant challenge, primarily centered on identifying an appropriate style representation. Conventional methods employ style loss, derived from second-order statistics or contrastive learning, to constrain style representation in the stylized result. However, these pre-defined style representations often limit stylistic expression, leading to artifacts. In contrast to existing approaches, we have discovered that latent features in vanilla diffusion models inherently contain natural style and content distributions. This allows for direct extraction of style information and seamless integration of generative priors into the content image without necessitating retraining. Our method adopts dual denoising paths to represent content and style references in latent space, subsequently guiding the content image denoising process with style latent codes. We introduce a Cross-attention Reweighting module that utilizes local content features to query style image information best suited to the input patch, thereby aligning the style distribution of the stylized results with that of the style image. Furthermore, we design a scaled adaptive instance normalization to mitigate inconsistencies in color distribution between style and stylized images on a global scale. Through theoretical analysis and extensive experimentation, we demonstrate the effectiveness and superiority of our diffusion-based \uline{z}ero-shot \uline{s}tyle \uline{t}ransfer via \uline{a}djusting style dist\uline{r}ibution, termed Z-STAR+.
CapHuman: Capture Your Moments in Parallel Universes
Feb 01, 2024



We concentrate on a novel human-centric image synthesis task, that is, given only one reference facial photograph, it is expected to generate specific individual images with diverse head positions, poses, and facial expressions in different contexts. To accomplish this goal, we argue that our generative model should be capable of the following favorable characteristics: (1) a strong visual and semantic understanding of our world and human society for basic object and human image generation. (2) generalizable identity preservation ability. (3) flexible and fine-grained head control. Recently, large pre-trained text-to-image diffusion models have shown remarkable results, serving as a powerful generative foundation. As a basis, we aim to unleash the above two capabilities of the pre-trained model. In this work, we present a new framework named CapHuman. We embrace the ``encode then learn to align" paradigm, which enables generalizable identity preservation for new individuals without cumbersome tuning at inference. CapHuman encodes identity features and then learns to align them into the latent space. Moreover, we introduce the 3D facial prior to equip our model with control over the human head in a flexible and 3D-consistent manner. Extensive qualitative and quantitative analyses demonstrate our CapHuman can produce well-identity-preserved, photo-realistic, and high-fidelity portraits with content-rich representations and various head renditions, superior to established baselines. Code and checkpoint will be released at https://github.com/VamosC/CapHuman.
$Z^*$: Zero-shot Style Transfer via Attention Rearrangement
Nov 25, 2023

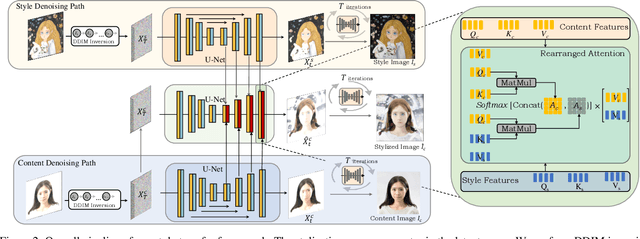
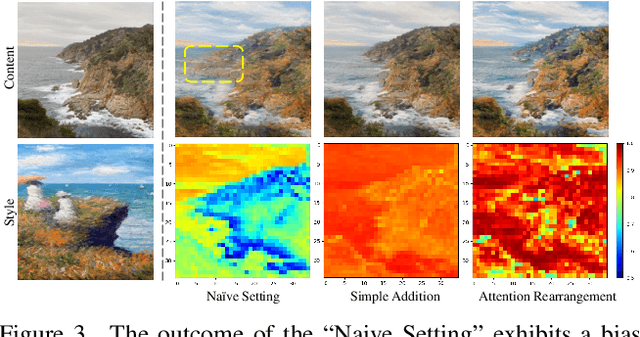
Despite the remarkable progress in image style transfer, formulating style in the context of art is inherently subjective and challenging. In contrast to existing learning/tuning methods, this study shows that vanilla diffusion models can directly extract style information and seamlessly integrate the generative prior into the content image without retraining. Specifically, we adopt dual denoising paths to represent content/style references in latent space and then guide the content image denoising process with style latent codes. We further reveal that the cross-attention mechanism in latent diffusion models tends to blend the content and style images, resulting in stylized outputs that deviate from the original content image. To overcome this limitation, we introduce a cross-attention rearrangement strategy. Through theoretical analysis and experiments, we demonstrate the effectiveness and superiority of the diffusion-based $\underline{Z}$ero-shot $\underline{S}$tyle $\underline{T}$ransfer via $\underline{A}$ttention $\underline{R}$earrangement, Z-STAR.
StyTr^2: Unbiased Image Style Transfer with Transformers
Jun 08, 2021
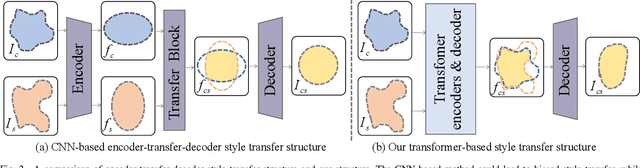


The goal of image style transfer is to render an image with artistic features guided by a style reference while maintaining the original content. Due to the locality and spatial invariance in CNNs, it is difficult to extract and maintain the global information of input images. Therefore, traditional neural style transfer methods are usually biased and content leak can be observed by running several times of the style transfer process with the same reference style image. To address this critical issue, we take long-range dependencies of input images into account for unbiased style transfer by proposing a transformer-based approach, namely StyTr^2. In contrast with visual transformers for other vision tasks, our StyTr^2 contains two different transformer encoders to generate domain-specific sequences for content and style, respectively. Following the encoders, a multi-layer transformer decoder is adopted to stylize the content sequence according to the style sequence. In addition, we analyze the deficiency of existing positional encoding methods and propose the content-aware positional encoding (CAPE) which is scale-invariant and more suitable for image style transfer task. Qualitative and quantitative experiments demonstrate the effectiveness of the proposed StyTr^2 compared to state-of-the-art CNN-based and flow-based approaches.
Arbitrary Video Style Transfer via Multi-Channel Correlation
Sep 17, 2020



Video style transfer is getting more attention in AI community for its numerous applications such as augmented reality and animation productions. Compared with traditional image style transfer, performing this task on video presents new challenges: how to effectively generate satisfactory stylized results for any specified style, and maintain temporal coherence across frames at the same time. Towards this end, we propose Multi-Channel Correction network (MCCNet), which can be trained to fuse the exemplar style features and input content features for efficient style transfer while naturally maintaining the coherence of input videos. Specifically, MCCNet works directly on the feature space of style and content domain where it learns to rearrange and fuse style features based on their similarity with content features. The outputs generated by MCC are features containing the desired style patterns which can further be decoded into images with vivid style textures. Moreover, MCCNet is also designed to explicitly align the features to input which ensures the output maintains the content structures as well as the temporal continuity. To further improve the performance of MCCNet under complex light conditions, we also introduce the illumination loss during training. Qualitative and quantitative evaluations demonstrate that MCCNet performs well in both arbitrary video and image style transfer tasks.
Arbitrary Style Transfer via Multi-Adaptation Network
May 27, 2020


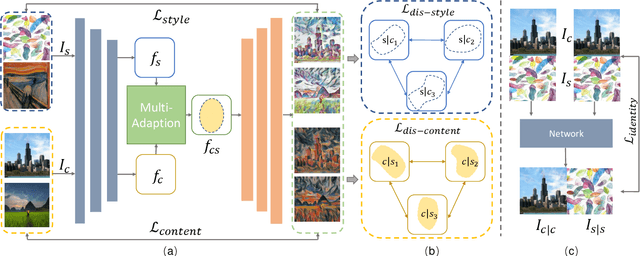
Arbitrary style transfer is a significant topic with both research value and application prospect.Given a content image and a referenced style painting, a desired style transfer would render the content image with the color tone and vivid stroke patterns of the style painting while synchronously maintain the detailed content structure information.Commonly, style transfer approaches would learn content and style representations of the content and style references first and then generate the stylized images guided by these representations.In this paper, we propose the multi-adaption network which involves two Self-Adaptation (SA) modules and one Co-Adaptation (CA) module: SA modules adaptively disentangles the content and style representations, i.e., content SA module uses the position-wise self-attention to enhance content representation and style SA module uses channel-wise self-attention to enhance style representation; CA module rearranges the distribution of style representation according to content representation distribution by calculating the local similarity between the disentangled content and style features in a non-local fashion.Moreover, a new disentanglement loss function enables our network to extract main style patterns to adapt to various content images and extract exact content features to adapt to various style images. Various qualitative and quantitative experiments demonstrate that the proposed multi-adaption network leads to better results than the state-of-the-art style transfer methods.