 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive 1D Video Diffusion Autoencoder
Feb 04, 2026Recent video generation models largely rely on video autoencoders that compress pixel-space videos into latent representations. However, existing video autoencoders suffer from three major limitations: (1) fixed-rate compression that wastes tokens on simple videos, (2) inflexible CNN architectures that prevent variable-length latent modeling, and (3) deterministic decoders that struggle to recover appropriate details from compressed latents. To address these issues, we propose One-Dimensional Diffusion Video Autoencoder (One-DVA), a transformer-based framework for adaptive 1D encoding and diffusion-based decoding. The encoder employs query-based vision transformers to extract spatiotemporal features and produce latent representations, while a variable-length dropout mechanism dynamically adjusts the latent length. The decoder is a pixel-space diffusion transformer that reconstructs videos with the latents as input conditions. With a two-stage training strategy, One-DVA achieves performance comparable to 3D-CNN VAEs on reconstruction metrics at identical compression ratios. More importantly, it supports adaptive compression and thus can achieve higher compression ratios. To better support downstream latent generation, we further regularize the One-DVA latent distribution for generative modeling and fine-tune its decoder to mitigate artifacts caused by the generation process.
FSVideo: Fast Speed Video Diffusion Model in a Highly-Compressed Latent Space
Feb 02, 2026We introduce FSVideo, a fast speed transformer-based image-to-video (I2V) diffusion framework. We build our framework on the following key components: 1.) a new video autoencoder with highly-compressed latent space ($64\times64\times4$ spatial-temporal downsampling ratio), achieving competitive reconstruction quality; 2.) a diffusion transformer (DIT) architecture with a new layer memory design to enhance inter-layer information flow and context reuse within DIT, and 3.) a multi-resolution generation strategy via a few-step DIT upsampler to increase video fidelity. Our final model, which contains a 14B DIT base model and a 14B DIT upsampler, achieves competitive performance against other popular open-source models, while being an order of magnitude faster. We discuss our model design as well as training strategies in this report.
Multi-Modal Face Stylization with a Generative Prior
May 29, 2023In this work, we introduce a new approach for artistic face stylization. Despite existing methods achieving impressive results in this task, there is still room for improvement in generating high-quality stylized faces with diverse styles and accurate facial reconstruction. Our proposed framework, MMFS, supports multi-modal face stylization by leveraging the strengths of StyleGAN and integrates it into an encoder-decoder architecture. Specifically, we use the mid-resolution and high-resolution layers of StyleGAN as the decoder to generate high-quality faces, while aligning its low-resolution layer with the encoder to extract and preserve input facial details. We also introduce a two-stage training strategy, where we train the encoder in the first stage to align the feature maps with StyleGAN and enable a faithful reconstruction of input faces. In the second stage, the entire network is fine-tuned with artistic data for stylized face generation. To enable the fine-tuned model to be applied in zero-shot and one-shot stylization tasks, we train an additional mapping network from the large-scale Contrastive-Language-Image-Pre-training (CLIP) space to a latent $w+$ space of fine-tuned StyleGAN. Qualitative and quantitative experiments show that our framework achieves superior face stylization performance in both one-shot and zero-shot stylization tasks, outperforming state-of-the-art methods by a large margin.
Distribution Aligned Multimodal and Multi-Domain Image Stylization
Jun 02, 2020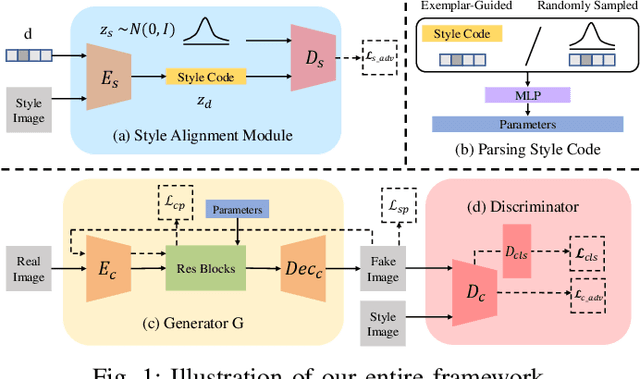



Multimodal and multi-domain stylization are two important problems in the field of image style transfer. Currently, there are few methods that can perform both multimodal and multi-domain stylization simultaneously. In this paper, we propose a unified framework for multimodal and multi-domain style transfer with the support of both exemplar-based reference and randomly sampled guidance. The key component of our method is a novel style distribution alignment module that eliminates the explicit distribution gaps between various style domains and reduces the risk of mode collapse. The multimodal diversity is ensured by either guidance from multiple images or random style code, while the multi-domain controllability is directly achieved by using a domain label. We validate our proposed framework on painting style transfer with a variety of different artistic styles and genres. Qualitative and quantitative comparisons with state-of-the-art methods demonstrate that our method can generate high-quality results of multi-domain styles and multimodal instances with reference style guidance or random sampled style.
Multi-Attribute Guided Painting Generation
Feb 26, 2020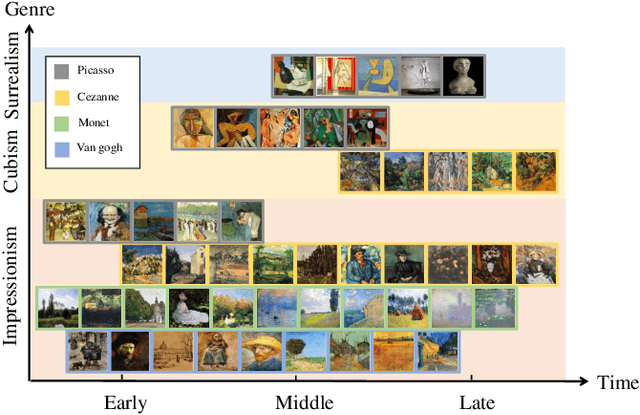



Controllable painting generation plays a pivotal role in image stylization. Currently, the control way of style transfer is subject to exemplar-based reference or a random one-hot vector guidance. Few works focus on decoupling the intrinsic properties of painting as control conditions, e.g., artist, genre and period. Under this circumstance, we propose a novel framework adopting multiple attributes from the painting to control the stylized results. An asymmetrical cycle structure is equipped to preserve the fidelity, associating with style preserving and attribute regression loss to keep the unique distinction of colors and textures between domains. Several qualitative and quantitative results demonstrate the effect of the combinations of multiple attributes and achieve satisfactory performance.