 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Pixels: Visual Metaphor Transfer via Schema-Driven Agentic Reasoning
Feb 01, 2026A visual metaphor constitutes a high-order form of human creativity, employing cross-domain semantic fusion to transform abstract concepts into impactful visual rhetoric. Despite the remarkable progress of generative AI, existing models remain largely confined to pixel-level instruction alignment and surface-level appearance preservation, failing to capture the underlying abstract logic necessary for genuine metaphorical generation. To bridge this gap, we introduce the task of Visual Metaphor Transfer (VMT), which challenges models to autonomously decouple the "creative essence" from a reference image and re-materialize that abstract logic onto a user-specified target subject. We propose a cognitive-inspired, multi-agent framework that operationalizes Conceptual Blending Theory (CBT) through a novel Schema Grammar ("G"). This structured representation decouples relational invariants from specific visual entities, providing a rigorous foundation for cross-domain logic re-instantiation. Our pipeline executes VMT through a collaborative system of specialized agents: a perception agent that distills the reference into a schema, a transfer agent that maintains generic space invariance to discover apt carriers, a generation agent for high-fidelity synthesis and a hierarchical diagnostic agent that mimics a professional critic, performing closed-loop backtracking to identify and rectify errors across abstract logic, component selection, and prompt encoding. Extensive experiments and human evaluations demonstrate that our method significantly outperforms SOTA baselines in metaphor consistency, analogy appropriateness, and visual creativity, paving the way for automated high-impact creative applications in advertising and media. Source code will be made publicly available.
TAG-MoE: Task-Aware Gating for Unified Generative Mixture-of-Experts
Jan 12, 2026Unified image generation and editing models suffer from severe task interference in dense diffusion transformers architectures, where a shared parameter space must compromise between conflicting objectives (e.g., local editing v.s. subject-driven generation). While the sparse Mixture-of-Experts (MoE) paradigm is a promising solution, its gating networks remain task-agnostic, operating based on local features, unaware of global task intent. This task-agnostic nature prevents meaningful specialization and fails to resolve the underlying task interference. In this paper, we propose a novel framework to inject semantic intent into MoE routing. We introduce a Hierarchical Task Semantic Annotation scheme to create structured task descriptors (e.g., scope, type, preservation). We then design Predictive Alignment Regularization to align internal routing decisions with the task's high-level semantics. This regularization evolves the gating network from a task-agnostic executor to a dispatch center. Our model effectively mitigates task interference, outperforming dense baselines in fidelity and quality, and our analysis shows that experts naturally develop clear and semantically correlated specializations.
Sissi: Zero-shot Style-guided Image Synthesis via Semantic-style Integration
Jan 10, 2026Text-guided image generation has advanced rapidly with large-scale diffusion models, yet achieving precise stylization with visual exemplars remains difficult. Existing approaches often depend on task-specific retraining or expensive inversion procedures, which can compromise content integrity, reduce style fidelity, and lead to an unsatisfactory trade-off between semantic prompt adherence and style alignment. In this work, we introduce a training-free framework that reformulates style-guided synthesis as an in-context learning task. Guided by textual semantic prompts, our method concatenates a reference style image with a masked target image, leveraging a pretrained ReFlow-based inpainting model to seamlessly integrate semantic content with the desired style through multimodal attention fusion. We further analyze the imbalance and noise sensitivity inherent in multimodal attention fusion and propose a Dynamic Semantic-Style Integration (DSSI) mechanism that reweights attention between textual semantic and style visual tokens, effectively resolving guidance conflicts and enhancing output coherence. Experiments show that our approach achieves high-fidelity stylization with superior semantic-style balance and visual quality, offering a simple yet powerful alternative to complex, artifact-prone prior methods.
HunyuanVideo-HOMA: Generic Human-Object Interaction in Multimodal Driven Human Animation
Jun 10, 2025To address key limitations in human-object interaction (HOI) video generation -- specifically the reliance on curated motion data, limited generalization to novel objects/scenarios, and restricted accessibility -- we introduce HunyuanVideo-HOMA, a weakly conditioned multimodal-driven framework. HunyuanVideo-HOMA enhances controllability and reduces dependency on precise inputs through sparse, decoupled motion guidance. It encodes appearance and motion signals into the dual input space of a multimodal diffusion transformer (MMDiT), fusing them within a shared context space to synthesize temporally consistent and physically plausible interactions. To optimize training, we integrate a parameter-space HOI adapter initialized from pretrained MMDiT weights, preserving prior knowledge while enabling efficient adaptation, and a facial cross-attention adapter for anatomically accurate audio-driven lip synchronization. Extensive experiments confirm state-of-the-art performance in interaction naturalness and generalization under weak supervision. Finally, HunyuanVideo-HOMA demonstrates versatility in text-conditioned generation and interactive object manipulation, supported by a user-friendly demo interface. The project page is at https://anonymous.4open.science/w/homa-page-0FBE/.
In-Context Brush: Zero-shot Customized Subject Insertion with Context-Aware Latent Space Manipulation
May 26, 2025Recent advances in diffusion models have enhanced multimodal-guided visual generation, enabling customized subject insertion that seamlessly "brushes" user-specified objects into a given image guided by textual prompts. However, existing methods often struggle to insert customized subjects with high fidelity and align results with the user's intent through textual prompts. In this work, we propose "In-Context Brush", a zero-shot framework for customized subject insertion by reformulating the task within the paradigm of in-context learning. Without loss of generality, we formulate the object image and the textual prompts as cross-modal demonstrations, and the target image with the masked region as the query. The goal is to inpaint the target image with the subject aligning textual prompts without model tuning. Building upon a pretrained MMDiT-based inpainting network, we perform test-time enhancement via dual-level latent space manipulation: intra-head "latent feature shifting" within each attention head that dynamically shifts attention outputs to reflect the desired subject semantics and inter-head "attention reweighting" across different heads that amplifies prompt controllability through differential attention prioritization. Extensive experiments and applications demonstrate that our approach achieves superior identity preservation, text alignment, and image quality compared to existing state-of-the-art methods, without requiring dedicated training or additional data collection.
Attend to Not Attended: Structure-then-Detail Token Merging for Post-training DiT Acceleration
May 16, 2025Diffusion transformers have shown exceptional performance in visual generation but incur high computational costs. Token reduction techniques that compress models by sharing the denoising process among similar tokens have been introduced. However, existing approaches neglect the denoising priors of the diffusion models, leading to suboptimal acceleration and diminished image quality. This study proposes a novel concept: attend to prune feature redundancies in areas not attended by the diffusion process. We analyze the location and degree of feature redundancies based on the structure-then-detail denoising priors. Subsequently, we introduce SDTM, a structure-then-detail token merging approach that dynamically compresses feature redundancies. Specifically, we design dynamic visual token merging, compression ratio adjusting, and prompt reweighting for different stages. Served in a post-training way, the proposed method can be integrated seamlessly into any DiT architecture. Extensive experiments across various backbones, schedulers, and datasets showcase the superiority of our method, for example, it achieves 1.55 times acceleration with negligible impact on image quality. Project page: https://github.com/ICTMCG/SDTM.
Multi-turn Consistent Image Editing
May 07, 2025Many real-world applications, such as interactive photo retouching, artistic content creation, and product design, require flexible and iterative image editing. However, existing image editing methods primarily focus on achieving the desired modifications in a single step, which often struggles with ambiguous user intent, complex transformations, or the need for progressive refinements. As a result, these methods frequently produce inconsistent outcomes or fail to meet user expectations. To address these challenges, we propose a multi-turn image editing framework that enables users to iteratively refine their edits, progressively achieving more satisfactory results. Our approach leverages flow matching for accurate image inversion and a dual-objective Linear Quadratic Regulators (LQR) for stable sampling, effectively mitigating error accumulation. Additionally, by analyzing the layer-wise roles of transformers, we introduce a adaptive attention highlighting method that enhances editability while preserving multi-turn coherence. Extensive experiments demonstrate that our framework significantly improves edit success rates and visual fidelity compared to existing methods.
A Survey on Cross-Modal Interaction Between Music and Multimodal Data
Apr 17, 2025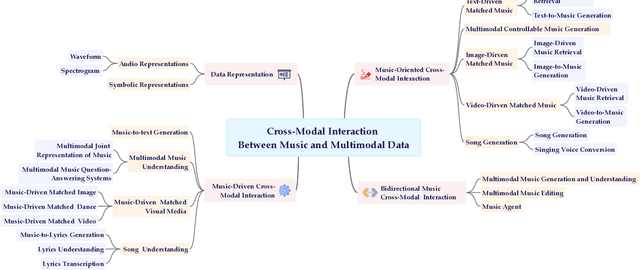
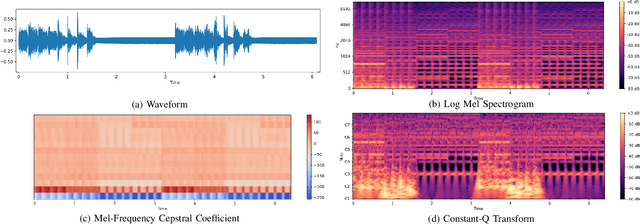

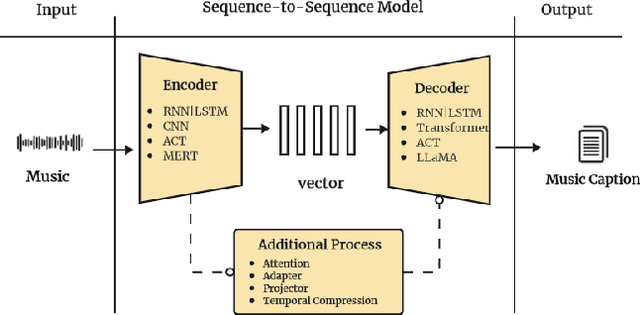
Multimodal learning has driven innovation across various industries, particularly in the field of music. By enabling more intuitive interaction experiences and enhancing immersion, it not only lowers the entry barriers to the music but also increases its overall appeal. This survey aims to provide a comprehensive review of multimodal tasks related to music, outlining how music contributes to multimodal learning and offering insights for researchers seeking to expand the boundaries of computational music. Unlike text and images, which are often semantically or visually intuitive, music primarily interacts with humans through auditory perception, making its data representation inherently less intuitive. Therefore, this paper first introduces the representations of music and provides an overview of music datasets. Subsequently, we categorize cross-modal interactions between music and multimodal data into three types: music-driven cross-modal interactions, music-oriented cross-modal interactions, and bidirectional music cross-modal interactions. For each category, we systematically trace the development of relevant sub-tasks, analyze existing limitations, and discuss emerging trends. Furthermore, we provide a comprehensive summary of datasets and evaluation metrics used in multimodal tasks related to music, offering benchmark references for future research. Finally, we discuss the current challenges in cross-modal interactions involving music and propose potential directions for future research.
Beyond Words: Augmenting Discriminative Richness via Diffusions in Unsupervised Prompt Learning
Apr 16, 2025Fine-tuning vision-language models (VLMs) with large amounts of unlabeled data has recently garnered significant interest. However, a key challenge remains the lack of high-quality pseudo-labeled data. Current pseudo-labeling strategies often struggle with mismatches between semantic and visual information, leading to sub-optimal performance of unsupervised prompt learning (UPL) methods. In this paper, we introduce a simple yet effective approach called \textbf{A}ugmenting D\textbf{i}scriminative \textbf{R}ichness via Diffusions (AiR), toward learning a richer discriminating way to represent the class comprehensively and thus facilitate classification. Specifically, our approach includes a pseudo-label generation module that leverages high-fidelity synthetic samples to create an auxiliary classifier, which captures richer visual variation, bridging text-image-pair classification to a more robust image-image-pair classification. Additionally, we exploit the diversity of diffusion-based synthetic samples to enhance prompt learning, providing greater information for semantic-visual alignment. Extensive experiments on five public benchmarks, including RESISC45 and Flowers102, and across three learning paradigms-UL, SSL, and TRZSL-demonstrate that AiR achieves substantial and consistent performance improvements over state-of-the-art unsupervised prompt learning methods.
Z-Magic: Zero-shot Multiple Attributes Guided Image Creator
Mar 15, 2025The customization of multiple attributes has gained popularity with the rising demand for personalized content creation. Despite promising empirical results, the contextual coherence between different attributes has been largely overlooked. In this paper, we argue that subsequent attributes should follow the multivariable conditional distribution introduced by former attribute creation. In light of this, we reformulate multi-attribute creation from a conditional probability theory perspective and tackle the challenging zero-shot setting. By explicitly modeling the dependencies between attributes, we further enhance the coherence of generated images across diverse attribute combinations. Furthermore, we identify connections between multi-attribute customization and multi-task learning, effectively addressing the high computing cost encountered in multi-attribute synthesis. Extensive experiments demonstrate that Z-Magic outperforms existing models in zero-shot image generation, with broad implications for AI-driven design and creative applications.