 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEuphonium: Steering Video Flow Matching via Process Reward Gradient Guided Stochastic Dynamics
Feb 04, 2026While online Reinforcement Learning has emerged as a crucial technique for aligning flow matching models with human preferences, current approaches are hindered by inefficient exploration during training rollouts. Relying on undirected stochasticity and sparse outcome rewards, these methods struggle to discover high-reward samples, resulting in data-inefficient and slow optimization. To address these limitations, we propose Euphonium, a novel framework that steers generation via process reward gradient guided dynamics. Our key insight is to formulate the sampling process as a theoretically principled Stochastic Differential Equation that explicitly incorporates the gradient of a Process Reward Model into the flow drift. This design enables dense, step-by-step steering toward high-reward regions, advancing beyond the unguided exploration in prior works, and theoretically encompasses existing sampling methods (e.g., Flow-GRPO, DanceGRPO) as special cases. We further derive a distillation objective that internalizes the guidance signal into the flow network, eliminating inference-time dependency on the reward model. We instantiate this framework with a Dual-Reward Group Relative Policy Optimization algorithm, combining latent process rewards for efficient credit assignment with pixel-level outcome rewards for final visual fidelity. Experiments on text-to-video generation show that Euphonium achieves better alignment compared to existing methods while accelerating training convergence by 1.66x.
SoliReward: Mitigating Susceptibility to Reward Hacking and Annotation Noise in Video Generation Reward Models
Dec 17, 2025Post-training alignment of video generation models with human preferences is a critical goal. Developing effective Reward Models (RMs) for this process faces significant methodological hurdles. Current data collection paradigms, reliant on in-prompt pairwise annotations, suffer from labeling noise. Concurrently, the architectural design of VLM-based RMs, particularly their output mechanisms, remains underexplored. Furthermore, RM is susceptible to reward hacking in post-training. To mitigate these limitations, we propose SoliReward, a systematic framework for video RM training. Our framework first sources high-quality, cost-efficient data via single-item binary annotations, then constructs preference pairs using a cross-prompt pairing strategy. Architecturally, we employ a Hierarchical Progressive Query Attention mechanism to enhance feature aggregation. Finally, we introduce a modified BT loss that explicitly accommodates win-tie scenarios. This approach regularizes the RM's score distribution for positive samples, providing more nuanced preference signals to alleviate over-focus on a small number of top-scoring samples. Our approach is validated on benchmarks evaluating physical plausibility, subject deformity, and semantic alignment, demonstrating improvements in direct RM evaluation metrics and in the efficacy of post-training on video generation models. Code and benchmark will be publicly available.
Interactive Visual Assessment for Text-to-Image Generation Models
Nov 23, 2024Visual generation models have achieved remarkable progress in computer graphics applications but still face significant challenges in real-world deployment. Current assessment approaches for visual generation tasks typically follow an isolated three-phase framework: test input collection, model output generation, and user assessment. These fashions suffer from fixed coverage, evolving difficulty, and data leakage risks, limiting their effectiveness in comprehensively evaluating increasingly complex generation models. To address these limitations, we propose DyEval, an LLM-powered dynamic interactive visual assessment framework that facilitates collaborative evaluation between humans and generative models for text-to-image systems. DyEval features an intuitive visual interface that enables users to interactively explore and analyze model behaviors, while adaptively generating hierarchical, fine-grained, and diverse textual inputs to continuously probe the capability boundaries of the models based on their feedback. Additionally, to provide interpretable analysis for users to further improve tested models, we develop a contextual reflection module that mines failure triggers of test inputs and reflects model potential failure patterns supporting in-depth analysis using the logical reasoning ability of LLM. Qualitative and quantitative experiments demonstrate that DyEval can effectively help users identify max up to 2.56 times generation failures than conventional methods, and uncover complex and rare failure patterns, such as issues with pronoun generation and specific cultural context generation. Our framework provides valuable insights for improving generative models and has broad implications for advancing the reliability and capabilities of visual generation systems across various domains.
Visual-Friendly Concept Protection via Selective Adversarial Perturbations
Aug 16, 2024Personalized concept generation by tuning diffusion models with a few images raises potential legal and ethical concerns regarding privacy and intellectual property rights. Researchers attempt to prevent malicious personalization using adversarial perturbations. However, previous efforts have mainly focused on the effectiveness of protection while neglecting the visibility of perturbations. They utilize global adversarial perturbations, which introduce noticeable alterations to original images and significantly degrade visual quality. In this work, we propose the Visual-Friendly Concept Protection (VCPro) framework, which prioritizes the protection of key concepts chosen by the image owner through adversarial perturbations with lower perceptibility. To ensure these perturbations are as inconspicuous as possible, we introduce a relaxed optimization objective to identify the least perceptible yet effective adversarial perturbations, solved using the Lagrangian multiplier method. Qualitative and quantitative experiments validate that VCPro achieves a better trade-off between the visibility of perturbations and protection effectiveness, effectively prioritizing the protection of target concepts in images with less perceptible perturbations.
U-VAP: User-specified Visual Appearance Personalization via Decoupled Self Augmentation
Mar 29, 2024



Concept personalization methods enable large text-to-image models to learn specific subjects (e.g., objects/poses/3D models) and synthesize renditions in new contexts. Given that the image references are highly biased towards visual attributes, state-of-the-art personalization models tend to overfit the whole subject and cannot disentangle visual characteristics in pixel space. In this study, we proposed a more challenging setting, namely fine-grained visual appearance personalization. Different from existing methods, we allow users to provide a sentence describing the desired attributes. A novel decoupled self-augmentation strategy is proposed to generate target-related and non-target samples to learn user-specified visual attributes. These augmented data allow for refining the model's understanding of the target attribute while mitigating the impact of unrelated attributes. At the inference stage, adjustments are conducted on semantic space through the learned target and non-target embeddings to further enhance the disentanglement of target attributes. Extensive experiments on various kinds of visual attributes with SOTA personalization methods show the ability of the proposed method to mimic target visual appearance in novel contexts, thus improving the controllability and flexibility of personalization.
CODIS: Benchmarking Context-Dependent Visual Comprehension for Multimodal Large Language Models
Feb 21, 2024



Multimodal large language models (MLLMs) have demonstrated promising results in a variety of tasks that combine vision and language. As these models become more integral to research and applications, conducting comprehensive evaluations of their capabilities has grown increasingly important. However, most existing benchmarks fail to consider that, in certain situations, images need to be interpreted within a broader context. In this work, we introduce a new benchmark, named as CODIS, designed to assess the ability of models to use context provided in free-form text to enhance visual comprehension. Our findings indicate that MLLMs consistently fall short of human performance on this benchmark. Further analysis confirms that these models struggle to effectively extract and utilize contextual information to improve their understanding of images. This underscores the pressing need to enhance the ability of MLLMs to comprehend visuals in a context-dependent manner. View our project website at https://thunlp-mt.github.io/CODIS.
Adversarial Robust Memory-Based Continual Learner
Nov 29, 2023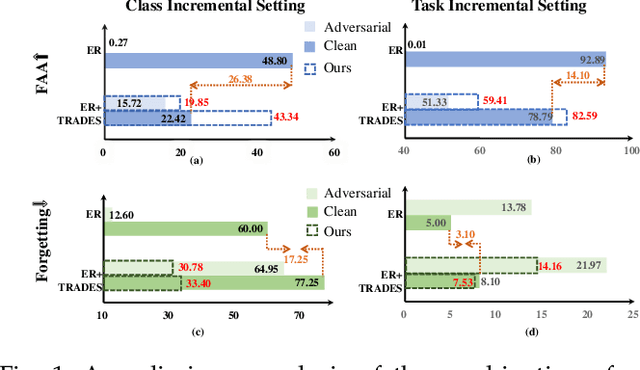
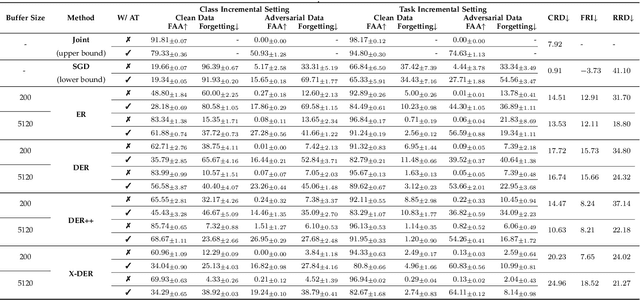
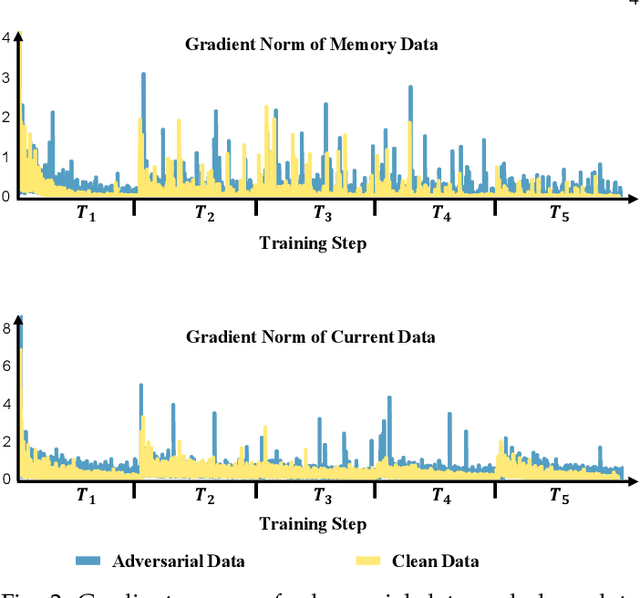
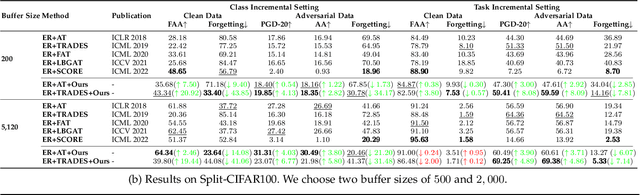
Despite the remarkable advances that have been made in continual learning, the adversarial vulnerability of such methods has not been fully discussed. We delve into the adversarial robustness of memory-based continual learning algorithms and observe limited robustness improvement by directly applying adversarial training techniques. Preliminary studies reveal the twin challenges for building adversarial robust continual learners: accelerated forgetting in continual learning and gradient obfuscation in adversarial robustness. In this study, we put forward a novel adversarial robust memory-based continual learner that adjusts data logits to mitigate the forgetting of pasts caused by adversarial samples. Furthermore, we devise a gradient-based data selection mechanism to overcome the gradient obfuscation caused by limited stored data. The proposed approach can widely integrate with existing memory-based continual learning as well as adversarial training algorithms in a plug-and-play way. Extensive experiments on Split-CIFAR10/100 and Split-Tiny-ImageNet demonstrate the effectiveness of our approach, achieving up to 8.13% higher accuracy for adversarial data.
Topology-Preserving Adversarial Training
Nov 29, 2023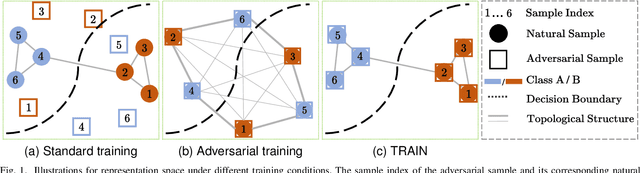
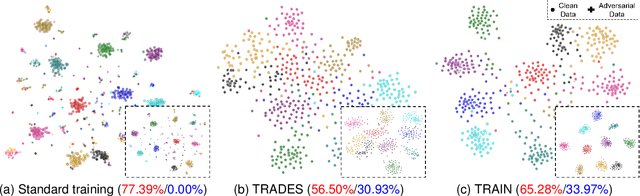
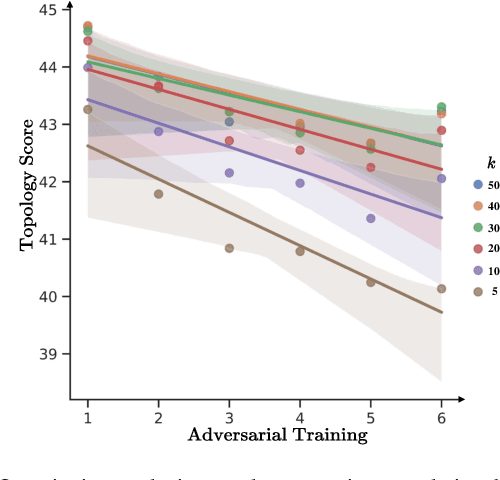
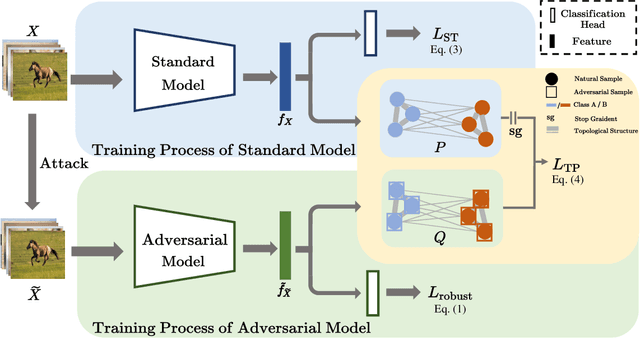
Despite the effectiveness in improving the robustness of neural networks, adversarial training has suffered from the natural accuracy degradation problem, i.e., accuracy on natural samples has reduced significantly. In this study, we reveal that natural accuracy degradation is highly related to the disruption of the natural sample topology in the representation space by quantitative and qualitative experiments. Based on this observation, we propose Topology-pReserving Adversarial traINing (TRAIN) to alleviate the problem by preserving the topology structure of natural samples from a standard model trained only on natural samples during adversarial training. As an additional regularization, our method can easily be combined with various popular adversarial training algorithms in a plug-and-play manner, taking advantage of both sides. Extensive experiments on CIFAR-10, CIFAR-100, and Tiny ImageNet show that our proposed method achieves consistent and significant improvements over various strong baselines in most cases. Specifically, without additional data, our proposed method achieves up to 8.78% improvement in natural accuracy and 4.50% improvement in robust accuracy.
Position-Enhanced Visual Instruction Tuning for Multimodal Large Language Models
Sep 14, 2023



Recently, Multimodal Large Language Models (MLLMs) that enable Large Language Models (LLMs) to interpret images through visual instruction tuning have achieved significant success. However, existing visual instruction tuning methods only utilize image-language instruction data to align the language and image modalities, lacking a more fine-grained cross-modal alignment. In this paper, we propose Position-enhanced Visual Instruction Tuning (PVIT), which extends the functionality of MLLMs by integrating an additional region-level vision encoder. This integration promotes a more detailed comprehension of images for the MLLM. In addition, to efficiently achieve a fine-grained alignment between the vision modules and the LLM, we design multiple data generation strategies to construct an image-region-language instruction dataset. Finally, we present both quantitative experiments and qualitative analysis that demonstrate the superiority of the proposed model. Code and data will be released at https://github.com/PVIT-official/PVIT.
Progressive Domain Expansion Network for Single Domain Generalization
Mar 30, 2021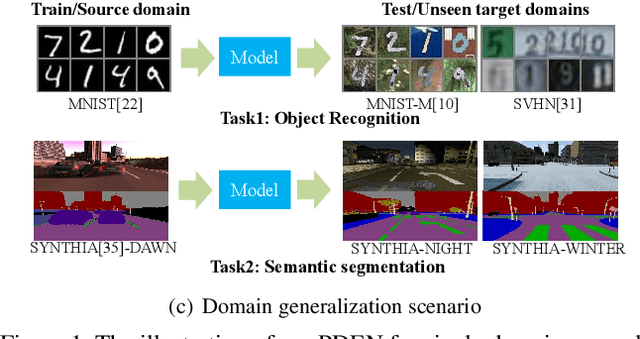
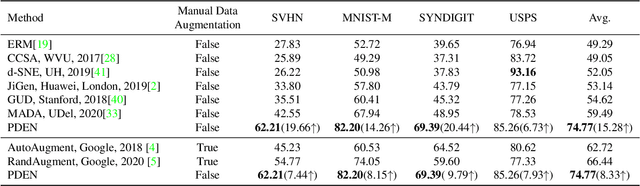
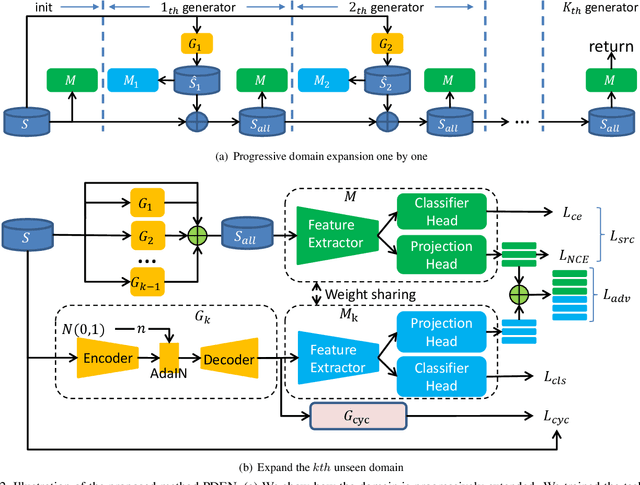
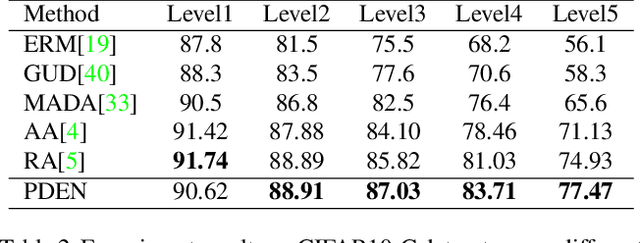
Single domain generalization is a challenging case of model generalization, where the models are trained on a single domain and tested on other unseen domains. A promising solution is to learn cross-domain invariant representations by expanding the coverage of the training domain. These methods have limited generalization performance gains in practical applications due to the lack of appropriate safety and effectiveness constraints. In this paper, we propose a novel learning framework called progressive domain expansion network (PDEN) for single domain generalization. The domain expansion subnetwork and representation learning subnetwork in PDEN mutually benefit from each other by joint learning. For the domain expansion subnetwork, multiple domains are progressively generated in order to simulate various photometric and geometric transforms in unseen domains. A series of strategies are introduced to guarantee the safety and effectiveness of the expanded domains. For the domain invariant representation learning subnetwork, contrastive learning is introduced to learn the domain invariant representation in which each class is well clustered so that a better decision boundary can be learned to improve it's generalization. Extensive experiments on classification and segmentation have shown that PDEN can achieve up to 15.28% improvement compared with the state-of-the-art single-domain generalization methods.